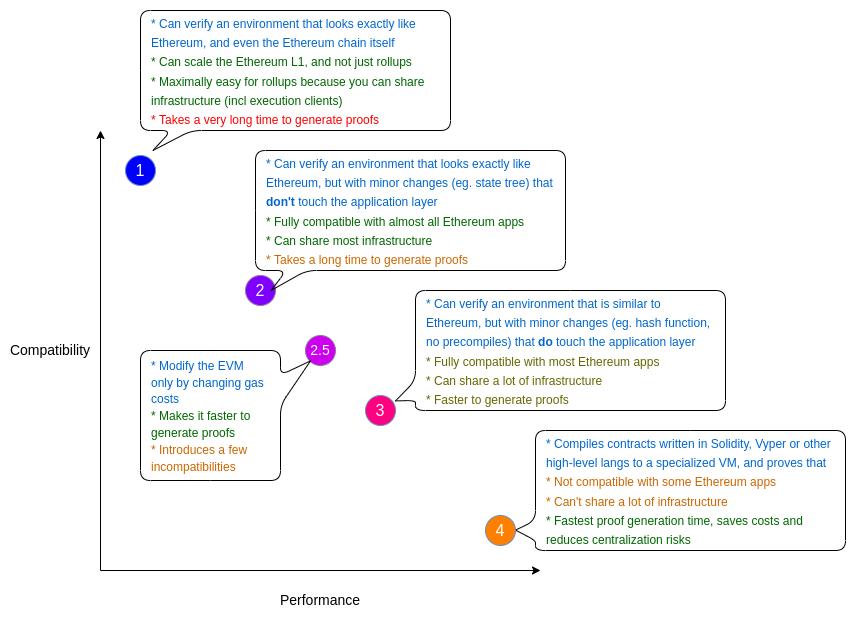
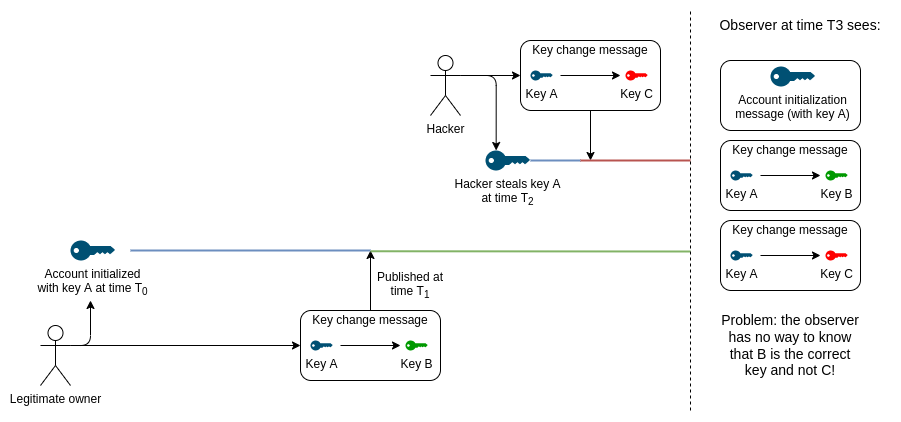
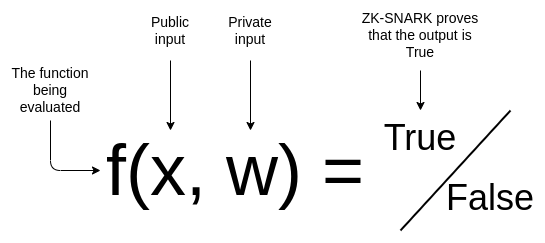
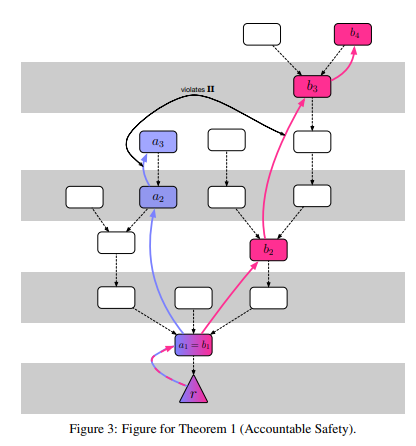
找到
227
篇与
科普知识
相关的结果
-
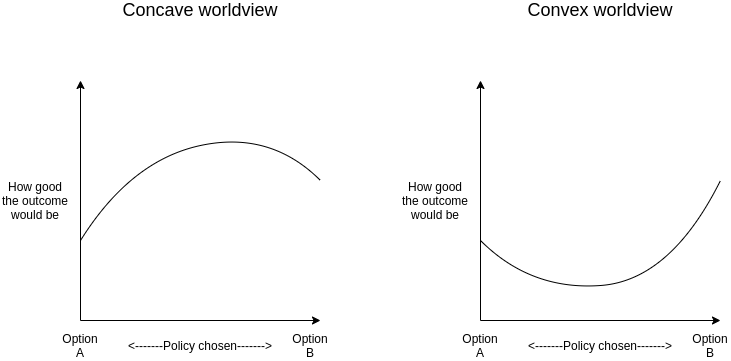
 DAOs are not corporations: where decentralization in autonomous organizations matters DAOs are not corporations: where decentralization in autonomous organizations matters2022 Sep 20 See all posts DAOs are not corporations: where decentralization in autonomous organizations matters Special thanks to Karl Floersch and Tina Zhen for feedback and review on earlier versions of this article.Recently, there has been a lot of discourse around the idea that highly decentralized DAOs do not work, and DAO governance should start to more closely resemble that of traditional corporations in order to remain competitive. The argument is always similar: highly decentralized governance is inefficient, and traditional corporate governance structures with boards, CEOs and the like evolved over hundreds of years to optimize for the goal of making good decisions and delivering value to shareholders in a changing world. DAO idealists are naive to assume that egalitarian ideals of decentralization can outperform this, when attempts to do this in the traditional corporate sector have had marginal success at best.This post will argue why this position is often wrong, and offer a different and more detailed perspective about where different kinds of decentralization are important. In particular, I will focus on three types of situations where decentralization is important:Decentralization for making better decisions in concave environments, where pluralism and even naive forms of compromise are on average likely to outperform the kinds of coherency and focus that come from centralization. Decentralization for censorship resistance: applications that need to continue functioning while resisting attacks from powerful external actors. Decentralization as credible fairness: applications where DAOs are taking on nation-state-like functions like basic infrastructure provision, and so traits like predictability, robustness and neutrality are valued above efficiency. Centralization is convex, decentralization is concaveSee the original post: ../../../2020/11/08/concave.htmlOne way to categorize decisions that need to be made is to look at whether they are convex or concave. In a choice between A and B, we would first look not at the question of A vs B itself, but instead at a higher-order question: would you rather take a compromise between A and B or a coin flip? In expected utility terms, we can express this distinction using a graph: If a decision is concave, we would prefer a compromise, and if it's convex, we would prefer a coin flip. Often, we can answer the higher-order question of whether a compromise or a coin flip is better much more easily than we can answer the first-order question of A vs B itself.Examples of convex decisions include:Pandemic response: a 100% travel ban may work at keeping a virus out, a 0% travel ban won't stop viruses but at least doesn't inconvenience people, but a 50% or 90% travel ban is the worst of both worlds. Military strategy: attacking on front A may make sense, attacking on front B may make sense, but splitting your army in half and attacking at both just means the enemy can easily deal with the two halves one by one Technology choices in crypto protocols: using technology A may make sense, using technology B may make sense, but some hybrid between the two often just leads to needless complexity and even adds risks of the two interfering with each other. Examples of concave decisions include:Judicial decisions: an average between two independently chosen judgements is probably more likely to be fair, and less likely to be completely ridiculous, than a random choice of one of the two judgements. Public goods funding: usually, giving $X to each of two promising projects is more effective than giving $2X to one and nothing to the other. Having any money at all gives a much bigger boost to a project's ability to achieve its mission than going from $X to $2X does. Tax rates: because of quadratic deadweight loss mechanics, a tax rate of X% is often only a quarter as harmful as a tax rate of 2X%, and at the same time more than half as good at raising revenue. Hence, moderate taxes are better than a coin flip between low/no taxes and high taxes. When decisions are convex, decentralizing the process of making that decision can easily lead to confusion and low-quality compromises. When decisions are concave, on the other hand, relying on the wisdom of the crowds can give better answers. In these cases, DAO-like structures with large amounts of diverse input going into decision-making can make a lot of sense. And indeed, people who see the world as a more concave place in general are more likely to see a need for decentralization in a wider variety of contexts.Should VitaDAO and Ukraine DAO be DAOs?Many of the more recent DAOs differ from earlier DAOs, like MakerDAO, in that whereas the earlier DAOs are organized around providing infrastructure, the newer DAOs are organized around performing various tasks around a particular theme. VitaDAO is a DAO funding early-stage longevity research, and UkraineDAO is a DAO organizing and funding efforts related to helping Ukrainian victims of war and supporting the Ukrainian defense effort. Does it make sense for these to be DAOs?This is a nuanced question, and we can get a view of one possible answer by understanding the internal workings of UkraineDAO itself. Typical DAOs tend to "decentralize" by gathering large amounts of capital into a single pool and using token-holder voting to fund each allocation. UkraineDAO, on the other hand, works by splitting its functions up into many pods, where each pod works as independently as possible. A top layer of governance can create new pods (in principle, governance can also fund pods, though so far funding has only gone to external Ukraine-related organizations), but once a pod is made and endowed with resources, it functions largely on its own. Internally, individual pods do have leaders and function in a more centralized way, though they still try to respect an ethos of personal autonomy. One natural question that one might ask is: isn't this kind of "DAO" just rebranding the traditional concept of multi-layer hierarchy? I would say this depends on the implementation: it's certainly possible to take this template and turn it into something that feels authoritarian in the same way stereotypical large corporations do, but it's also possible to use the template in a very different way.Two things that can help ensure that an organization built this way will actually turn out to be meaningfully decentralized include:A truly high level of autonomy for pods, where the pods accept resources from the core and are occasionally checked for alignment and competence if they want to keep getting those resources, but otherwise act entirely on their own and don't "take orders" from the core. Highly decentralized and diverse core governance. This does not require a "governance token", but it does require broader and more diverse participation in the core. Normally, broad and diverse participation is a large tax on efficiency. But if (1) is satisfied, so pods are highly autonomous and the core needs to make fewer decisions, the effects of top-level governance being less efficient become smaller. Now, how does this fit into the "convex vs concave" framework? Here, the answer is roughly as follows: the (more decentralized) top level is concave, the (more centralized within each pod) bottom level is convex. Giving a pod $X is generally better than a coin flip between giving it $0 and giving it $2X, and there isn't a large loss from having compromises or "inconsistent" philosophies guiding different decisions. But within each individual pod, having a clear opinionated perspective guiding decisions and being able to insist on many choices that have synergies with each other is much more important.Decentralization and censorship resistanceThe most often publicly cited reason for decentralization in crypto is censorship resistance: a DAO or protocol needs to be able to function and defend itself despite external attack, including from large corporate or even state actors. This has already been publicly talked about at length, and so deserves less elaboration, but there are still some important nuances.Two of the most successful censorship-resistant services that large numbers of people use today are The Pirate Bay and Sci-Hub. The Pirate Bay is a hybrid system: it's a search engine for BitTorrent, which is a highly decentralized network, but the search engine itself is centralized. It has a small core team that is dedicated to keeping it running, and it defends itself with the mole's strategy in whack-a-mole: when the hammer comes down, move out of the way and re-appear somewhere else. The Pirate Bay and Sci-Hub have both frequently changed domain names, relied on arbitrage between different jurisdictions, and used all kinds of other techniques. This strategy is centralized, but it has allowed them both to be successful both at defense and at product-improvement agility.DAOs do not act like The Pirate Bay and Sci-Hub; DAOs act like BitTorrent. And there is a reason why BitTorrent does need to be decentralized: it requires not just censorship resistance, but also long-term investment and reliability. If BitTorrent got shut down once a year and required all its seeders and users to switch to a new provider, the network would quickly degrade in quality. Censorship resistance-demanding DAOs should also be in the same category: they should be providing a service that isn't just evading permanent censorship, but also evading mere instability and disruption. MakerDAO (and the Reflexer DAO which manages RAI) are excellent examples of this. A DAO running a decentralized search engine probably does not: you can just build a regular search engine and use Sci-Hub-style techniques to ensure its survival.Decentralization as credible fairnessSometimes, DAOs' primary concern is not a need to resist nation states, but rather a need to take on some of the functions of nation states. This often involves tasks that can be described as "maintaining basic infrastructure". Because governments have less ability to oversee DAOs, DAOs need to be structured to take on a greater ability to oversee themselves. And this requires decentralization. Of course, it's not actually possible to come anywhere close to eliminating hierarchy and inequality of information and decision-making power in its entirety etc etc etc, but what if we can get even 30% of the way there? Consider three motivating examples: algorithmic stablecoins, the Kleros court, and the Optimism retroactive funding mechanism.An algorithmic stablecoin DAO is a system that uses on-chain financial contracts to create a crypto-asset whose price tracks some stable index, often but not necessarily the US dollar. Kleros is a "decentralized court": a DAO whose function is to give rulings on arbitration questions such as "is this Github commit an acceptable submission to this on-chain bounty?" Optimism's retroactive funding mechanism is a component of the Optimism DAO which retroactively rewards projects that have provided value to the Ethereum and Optimism ecosystems. In all three cases, there is a need to make subjective judgements, which cannot be done automatically through a piece of on-chain code. In the first case, the goal is simply to get reasonably accurate measurements of some price index. If the stablecoin tracks the US dollar, then you just need the ETH/USD price. If hyperinflation or some other reason to abandon the US dollar arises, the stablecoin DAO might need to manage a trustworthy on-chain CPI calculation. Kleros is all about making unavoidably subjective judgements on any arbitrary question that is submitted to it, including whether or not submitted questions should be rejected for being "unethical". Optimism's retroactive funding is tasked with one of the most open-ended subjective questions at all: what projects have done work that is the most useful to the Ethereum and Optimism ecosystems?All three cases have an unavoidable need for "governance", and pretty robust governance too. In all cases, governance being attackable, from the outside or the inside, can easily lead to very big problems. Finally, the governance doesn't just need to be robust, it needs to credibly convince a large and untrusting public that it is robust.The algorithmic stablecoin's Achilles heel: the oracleAlgorithmic stablecoins depend on oracles. In order for an on-chain smart contract to know whether to target the value of DAI to 0.005 ETH or 0.0005 ETH, it needs some mechanism to learn the (external-to-the-chain) piece of information of what the ETH/USD price is. And in fact, this "oracle" is the primary place at which an algorithmic stablecoin can be attacked.This leads to a security conundrum: an algorithmic stablecoin cannot safely hold more collateral, and therefore cannot issue more units, than the market cap of its speculative token (eg. MKR, FLX...), because if it does, then it becomes profitable to buy up half the speculative token supply, use those tokens to control the oracle, and steal funds from users by feeding bad oracle values and liquidating them.Here is a possible alternative design for a stablecoin oracle: add a layer of indirection. Quoting the ethresear.ch post:We set up a contract where there are 13 "providers"; the answer to a query is the median of the answer returned by these providers. Every week, there is a vote, where the oracle token holders can replace one of the providers ...The security model is simple: if you trust the voting mechanism, you can trust the oracle output, unless 7 providers get corrupted at the same time. If you trust the current set of oracle providers, you can trust the output for at least the next six weeks, even if you completely do not trust the voting mechanism. Hence, if the voting mechanism gets corrupted, there will be able time for participants in any applications that depend on the oracle to make an orderly exit.Notice the very un-corporate-like nature of this proposal. It involves taking away the governance's ability to act quickly, and intentionally spreading out oracle responsibility across a large number of participants. This is valuable for two reasons. First, it makes it harder for outsiders to attack the oracle, and for new coin holders to quickly take over control of the oracle. Second, it makes it harder for the oracle participants themselves to collude to attack the system. It also mitigates oracle extractable value, where a single provider might intentionally delay publishing to personally profit from a liquidation (in a multi-provider system, if one provider doesn't immediately publish, others soon will).Fairness in KlerosThe "decentralized court" system Kleros is a really valuable and important piece of infrastructure for the Ethereum ecosystem: Proof of Humanity uses it, various "smart contract bug insurance" products use it, and many other projects plug into it as some kind of "adjudication of last resort".Recently, there have been some public concerns about whether or not the platform's decision-making is fair. Some participants have made cases, trying to claim a payout from decentralized smart contract insurance platforms that they argue they deserve. Perhaps the most famous of these cases is Mizu's report on case #1170. The case blew up from being a minor language intepretation dispute into a broader scandal because of the accusation that insiders to Kleros itself were making a coordinated effort to throw a large number of tokens to pushing the decision in the direction they wanted. A participant to the debate writes:The incentives-based decision-making process of the court ... is by all appearances being corrupted by a single dev with a very large (25%) stake in the courts.Of course, this is but one side of one issue in a broader debate, and it's up to the Kleros community to figure out who is right or wrong and how to respond. But zooming out from the question of this individual case, what is important here is the the extent to which the entire value proposition of something like Kleros depends on it being able to convince the public that it is strongly protected against this kind of centralized manipulation. For something like Kleros to be trusted, it seems necessary that there should not be a single individual with a 25% stake in a high-level court. Whether through a more widely distributed token supply, or through more use of non-token-driven governance, a more credibly decentralized form of governance could help Kleros avoid such concerns entirely.Optimism retro fundingOptimism's retroactive founding round 1 results were chosen by a quadratic vote among 24 "badge holders". Round 2 will likely use a larger number of badge holders, and the eventual goal is to move to a system where a much larger body of citizens control retro funding allocation, likely through some multilayered mechanism involving sortition, subcommittees and/or delegation.There have been some internal debates about whether to have more vs fewer citizens: should "citizen" really mean something closer to "senator", an expert contributor who deeply understands the Optimism ecosystem, should it be a position given out to just about anyone who has significantly participated in the Optimism ecosystem, or somewhere in between? My personal stance on this issue has always been in the direction of more citizens, solving governance inefficiency issues with second-layer delegation instead of adding enshrined centralization into the governance protocol. One key reason for my position is the potential for insider trading and self-dealing issues.The Optimism retroactive funding mechanism has always been intended to be coupled with a prospective speculation ecosystem: public-goods projects that need funding now could sell "project tokens", and anyone who buys project tokens becomes eligible for a large retroactively-funded compensation later. But this mechanism working well depends crucially on the retroactive funding part working correctly, and is very vulnerable to the retroactive funding mechanism becoming corrupted. Some example attacks:If some group of people has decided how they will vote on some project, they can buy up (or if overpriced, short) its project token ahead of releasing the decision. If some group of people knows that they will later adjudicate on some specific project, they can buy up the project token early and then intentionally vote in its favor even if the project does not actually deserve funding. Funding deciders can accept bribes from projects. There are typically three ways of dealing with these types of corruption and insider trading issues:Retroactively punish malicious deciders. Proactively filter for higher-quality deciders. Add more deciders. The corporate world typically focuses on the first two, using financial surveillance and judicious penalties for the first and in-person interviews and background checks for the second. The decentralized world has less access to such tools: project tokens are likely to be tradeable anonymously, DAOs have at best limited recourse to external judicial systems, and the remote and online nature of the projects and the desire for global inclusivity makes it harder to do background checks and informal in-person "smell tests" for character. Hence, the decentralized world needs to put more weight on the third technique: distribute decision-making power among more deciders, so that each individual decider has less power, and so collusions are more likely to be whistleblown on and revealed.Should DAOs learn more from corporate governance or political science?Curtis Yarvin, an American philosopher whose primary "big idea" is that corporations are much more effective and optimized than governments and so we should improve governments by making them look more like corporations (eg. by moving away from democracy and closer to monarchy), recently wrote an article expressing his thoughts on how DAO governance should be designed. Not surprisingly, his answer involves borrowing ideas from governance of traditional corporations. From his introduction:Instead the basic design of the Anglo-American limited-liability joint-stock company has remained roughly unchanged since the start of the Industrial Revolution—which, a contrarian historian might argue, might actually have been a Corporate Revolution. If the joint-stock design is not perfectly optimal, we can expect it to be nearly optimal.While there is a categorical difference between these two types of organizations—we could call them first-order (sovereign) and second-order (contractual) organizations—it seems that society in the current year has very effective second-order organizations, but not very effective first-order organizations.Therefore, we probably know more about second-order organizations. So, when designing a DAO, we should start from corporate governance, not political science.Yarvin's post is very correct in identifying the key difference between "first-order" (sovereign) and "second-order" (contractual) organizations - in fact, that exact distinction is precisely the topic of the section in my own post above on credible fairness. However, Yarvin's post makes a big, and surprising, mistake immediately after, by immediately pivoting to saying that corporate governance is the better starting point for how DAOs should operate. The mistake is surprising because the logic of the situation seems to almost directly imply the exact opposite conclusion. Because DAOs do not have a sovereign above them, and are often explicitly in the business of providing services (like currency and arbitration) that are typically reserved for sovereigns, it is precisely the design of sovereigns (political science), and not the design of corporate governance, that DAOs have more to learn from.To Yarvin's credit, the second part of his post does advocate an "hourglass" model that combines a decentralized alignment and accountability layer and a centralized management and execution layer, but this is already an admission that DAO design needs to learn at least as much from first-order orgs as from second-order orgs.Sovereigns are inefficient and corporations are efficient for the same reason why number theory can prove very many things but abstract group theory can prove much fewer things: corporations fail less and accomplish more because they can make more assumptions and have more powerful tools to work with. Corporations can count on their local sovereign to stand up to defend them if the need arises, as well as to provide an external legal system they can lean on to stabilize their incentive structure. In a sovereign, on the other hand, the biggest challenge is often what to do when the incentive structure is under attack and/or at risk of collapsing entirely, with no external leviathan standing ready to support it.Perhaps the greatest problem in the design of successful governance systems for sovereigns is what Samo Burja calls "the succession problem": how to ensure continuity as the system transitions from being run by one group of humans to another group as the first group retires. Corporations, Burja writes, often just don't solve the problem at all:Silicon Valley enthuses over "disruption" because we have become so used to the succession problem remaining unsolved within discrete institutions such as companies.DAOs will need to solve the succession problem eventually (in fact, given the sheer frequency of the "get rich and retire" pattern among crypto early adopters, some DAOs have to deal with succession issues already). Monarchies and corporate-like forms often have a hard time solving the succession problem, because the institutional structure gets deeply tied up with the habits of one specific person, and it either proves difficult to hand off, or there is a very-high-stakes struggle over whom to hand it off to. More decentralized political forms like democracy have at least a theory of how smooth transitions can happen. Hence, I would argue that for this reason too, DAOs have more to learn from the more liberal and democratic schools of political science than they do from the governance of corporations.Of course, DAOs will in some cases have to accomplish specific complicated tasks, and some use of corporate-like forms for accomplishing those tasks may well be a good idea. Additionally, DAOs need to handle unexpected uncertainty. A system that was intended to function in a stable and unchanging way around one set of assumptions, when faced with an extreme and unexpected change to those circumstances, does need some kind of brave leader to coordinate a response. A prototypical example of the latter is stablecoins handling a US dollar collapse: what happens when a stablecoin DAO that evolved around the assumption that it's just trying to track the US dollar suddenly faces a world where the US dollar is no longer a viable thing to be tracking, and a rapid switch to some kind of CPI is needed? Stylized diagram of the internal experience of the RAI ecosystem going through an unexpected transition to a CPI-based regime if the USD ceases to be a viable reference asset. Here, corporate governance-inspired approaches may seem better, because they offer a ready-made pattern for responding to such a problem: the founder organizes a pivot. But as it turns out, the history of political systems also offers a pattern well-suited to this situation, and one that covers the question of how to go back to a decentralized mode when the crisis is over: the Roman Republic custom of electing a dictator for a temporary term to respond to a crisis.Realistically, we probably only need a small number of DAOs that look more like constructs from political science than something out of corporate governance. But those are the really important ones. A stablecoin does not need to be efficient; it must first and foremost be stable and decentralized. A decentralized court is similar. A system that directs funding for a particular cause - whether Optimism retroactive funding, VitaDAO, UkraineDAO or something else - is optimizing for a much more complicated purpose than profit maximization, and so an alignment solution other than shareholder profit is needed to make sure it keeps using the funds for the purpose that was intended.By far the greatest number of organizations, even in a crypto world, are going to be "contractual" second-order organizations that ultimately lean on these first-order giants for support, and for these organizations, much simpler and leader-driven forms of governance emphasizing agility are often going to make sense. But this should not distract from the fact that the ecosystem would not survive without some non-corporate decentralized forms keeping the whole thing stable.
DAOs are not corporations: where decentralization in autonomous organizations matters DAOs are not corporations: where decentralization in autonomous organizations matters2022 Sep 20 See all posts DAOs are not corporations: where decentralization in autonomous organizations matters Special thanks to Karl Floersch and Tina Zhen for feedback and review on earlier versions of this article.Recently, there has been a lot of discourse around the idea that highly decentralized DAOs do not work, and DAO governance should start to more closely resemble that of traditional corporations in order to remain competitive. The argument is always similar: highly decentralized governance is inefficient, and traditional corporate governance structures with boards, CEOs and the like evolved over hundreds of years to optimize for the goal of making good decisions and delivering value to shareholders in a changing world. DAO idealists are naive to assume that egalitarian ideals of decentralization can outperform this, when attempts to do this in the traditional corporate sector have had marginal success at best.This post will argue why this position is often wrong, and offer a different and more detailed perspective about where different kinds of decentralization are important. In particular, I will focus on three types of situations where decentralization is important:Decentralization for making better decisions in concave environments, where pluralism and even naive forms of compromise are on average likely to outperform the kinds of coherency and focus that come from centralization. Decentralization for censorship resistance: applications that need to continue functioning while resisting attacks from powerful external actors. Decentralization as credible fairness: applications where DAOs are taking on nation-state-like functions like basic infrastructure provision, and so traits like predictability, robustness and neutrality are valued above efficiency. Centralization is convex, decentralization is concaveSee the original post: ../../../2020/11/08/concave.htmlOne way to categorize decisions that need to be made is to look at whether they are convex or concave. In a choice between A and B, we would first look not at the question of A vs B itself, but instead at a higher-order question: would you rather take a compromise between A and B or a coin flip? In expected utility terms, we can express this distinction using a graph: If a decision is concave, we would prefer a compromise, and if it's convex, we would prefer a coin flip. Often, we can answer the higher-order question of whether a compromise or a coin flip is better much more easily than we can answer the first-order question of A vs B itself.Examples of convex decisions include:Pandemic response: a 100% travel ban may work at keeping a virus out, a 0% travel ban won't stop viruses but at least doesn't inconvenience people, but a 50% or 90% travel ban is the worst of both worlds. Military strategy: attacking on front A may make sense, attacking on front B may make sense, but splitting your army in half and attacking at both just means the enemy can easily deal with the two halves one by one Technology choices in crypto protocols: using technology A may make sense, using technology B may make sense, but some hybrid between the two often just leads to needless complexity and even adds risks of the two interfering with each other. Examples of concave decisions include:Judicial decisions: an average between two independently chosen judgements is probably more likely to be fair, and less likely to be completely ridiculous, than a random choice of one of the two judgements. Public goods funding: usually, giving $X to each of two promising projects is more effective than giving $2X to one and nothing to the other. Having any money at all gives a much bigger boost to a project's ability to achieve its mission than going from $X to $2X does. Tax rates: because of quadratic deadweight loss mechanics, a tax rate of X% is often only a quarter as harmful as a tax rate of 2X%, and at the same time more than half as good at raising revenue. Hence, moderate taxes are better than a coin flip between low/no taxes and high taxes. When decisions are convex, decentralizing the process of making that decision can easily lead to confusion and low-quality compromises. When decisions are concave, on the other hand, relying on the wisdom of the crowds can give better answers. In these cases, DAO-like structures with large amounts of diverse input going into decision-making can make a lot of sense. And indeed, people who see the world as a more concave place in general are more likely to see a need for decentralization in a wider variety of contexts.Should VitaDAO and Ukraine DAO be DAOs?Many of the more recent DAOs differ from earlier DAOs, like MakerDAO, in that whereas the earlier DAOs are organized around providing infrastructure, the newer DAOs are organized around performing various tasks around a particular theme. VitaDAO is a DAO funding early-stage longevity research, and UkraineDAO is a DAO organizing and funding efforts related to helping Ukrainian victims of war and supporting the Ukrainian defense effort. Does it make sense for these to be DAOs?This is a nuanced question, and we can get a view of one possible answer by understanding the internal workings of UkraineDAO itself. Typical DAOs tend to "decentralize" by gathering large amounts of capital into a single pool and using token-holder voting to fund each allocation. UkraineDAO, on the other hand, works by splitting its functions up into many pods, where each pod works as independently as possible. A top layer of governance can create new pods (in principle, governance can also fund pods, though so far funding has only gone to external Ukraine-related organizations), but once a pod is made and endowed with resources, it functions largely on its own. Internally, individual pods do have leaders and function in a more centralized way, though they still try to respect an ethos of personal autonomy. One natural question that one might ask is: isn't this kind of "DAO" just rebranding the traditional concept of multi-layer hierarchy? I would say this depends on the implementation: it's certainly possible to take this template and turn it into something that feels authoritarian in the same way stereotypical large corporations do, but it's also possible to use the template in a very different way.Two things that can help ensure that an organization built this way will actually turn out to be meaningfully decentralized include:A truly high level of autonomy for pods, where the pods accept resources from the core and are occasionally checked for alignment and competence if they want to keep getting those resources, but otherwise act entirely on their own and don't "take orders" from the core. Highly decentralized and diverse core governance. This does not require a "governance token", but it does require broader and more diverse participation in the core. Normally, broad and diverse participation is a large tax on efficiency. But if (1) is satisfied, so pods are highly autonomous and the core needs to make fewer decisions, the effects of top-level governance being less efficient become smaller. Now, how does this fit into the "convex vs concave" framework? Here, the answer is roughly as follows: the (more decentralized) top level is concave, the (more centralized within each pod) bottom level is convex. Giving a pod $X is generally better than a coin flip between giving it $0 and giving it $2X, and there isn't a large loss from having compromises or "inconsistent" philosophies guiding different decisions. But within each individual pod, having a clear opinionated perspective guiding decisions and being able to insist on many choices that have synergies with each other is much more important.Decentralization and censorship resistanceThe most often publicly cited reason for decentralization in crypto is censorship resistance: a DAO or protocol needs to be able to function and defend itself despite external attack, including from large corporate or even state actors. This has already been publicly talked about at length, and so deserves less elaboration, but there are still some important nuances.Two of the most successful censorship-resistant services that large numbers of people use today are The Pirate Bay and Sci-Hub. The Pirate Bay is a hybrid system: it's a search engine for BitTorrent, which is a highly decentralized network, but the search engine itself is centralized. It has a small core team that is dedicated to keeping it running, and it defends itself with the mole's strategy in whack-a-mole: when the hammer comes down, move out of the way and re-appear somewhere else. The Pirate Bay and Sci-Hub have both frequently changed domain names, relied on arbitrage between different jurisdictions, and used all kinds of other techniques. This strategy is centralized, but it has allowed them both to be successful both at defense and at product-improvement agility.DAOs do not act like The Pirate Bay and Sci-Hub; DAOs act like BitTorrent. And there is a reason why BitTorrent does need to be decentralized: it requires not just censorship resistance, but also long-term investment and reliability. If BitTorrent got shut down once a year and required all its seeders and users to switch to a new provider, the network would quickly degrade in quality. Censorship resistance-demanding DAOs should also be in the same category: they should be providing a service that isn't just evading permanent censorship, but also evading mere instability and disruption. MakerDAO (and the Reflexer DAO which manages RAI) are excellent examples of this. A DAO running a decentralized search engine probably does not: you can just build a regular search engine and use Sci-Hub-style techniques to ensure its survival.Decentralization as credible fairnessSometimes, DAOs' primary concern is not a need to resist nation states, but rather a need to take on some of the functions of nation states. This often involves tasks that can be described as "maintaining basic infrastructure". Because governments have less ability to oversee DAOs, DAOs need to be structured to take on a greater ability to oversee themselves. And this requires decentralization. Of course, it's not actually possible to come anywhere close to eliminating hierarchy and inequality of information and decision-making power in its entirety etc etc etc, but what if we can get even 30% of the way there? Consider three motivating examples: algorithmic stablecoins, the Kleros court, and the Optimism retroactive funding mechanism.An algorithmic stablecoin DAO is a system that uses on-chain financial contracts to create a crypto-asset whose price tracks some stable index, often but not necessarily the US dollar. Kleros is a "decentralized court": a DAO whose function is to give rulings on arbitration questions such as "is this Github commit an acceptable submission to this on-chain bounty?" Optimism's retroactive funding mechanism is a component of the Optimism DAO which retroactively rewards projects that have provided value to the Ethereum and Optimism ecosystems. In all three cases, there is a need to make subjective judgements, which cannot be done automatically through a piece of on-chain code. In the first case, the goal is simply to get reasonably accurate measurements of some price index. If the stablecoin tracks the US dollar, then you just need the ETH/USD price. If hyperinflation or some other reason to abandon the US dollar arises, the stablecoin DAO might need to manage a trustworthy on-chain CPI calculation. Kleros is all about making unavoidably subjective judgements on any arbitrary question that is submitted to it, including whether or not submitted questions should be rejected for being "unethical". Optimism's retroactive funding is tasked with one of the most open-ended subjective questions at all: what projects have done work that is the most useful to the Ethereum and Optimism ecosystems?All three cases have an unavoidable need for "governance", and pretty robust governance too. In all cases, governance being attackable, from the outside or the inside, can easily lead to very big problems. Finally, the governance doesn't just need to be robust, it needs to credibly convince a large and untrusting public that it is robust.The algorithmic stablecoin's Achilles heel: the oracleAlgorithmic stablecoins depend on oracles. In order for an on-chain smart contract to know whether to target the value of DAI to 0.005 ETH or 0.0005 ETH, it needs some mechanism to learn the (external-to-the-chain) piece of information of what the ETH/USD price is. And in fact, this "oracle" is the primary place at which an algorithmic stablecoin can be attacked.This leads to a security conundrum: an algorithmic stablecoin cannot safely hold more collateral, and therefore cannot issue more units, than the market cap of its speculative token (eg. MKR, FLX...), because if it does, then it becomes profitable to buy up half the speculative token supply, use those tokens to control the oracle, and steal funds from users by feeding bad oracle values and liquidating them.Here is a possible alternative design for a stablecoin oracle: add a layer of indirection. Quoting the ethresear.ch post:We set up a contract where there are 13 "providers"; the answer to a query is the median of the answer returned by these providers. Every week, there is a vote, where the oracle token holders can replace one of the providers ...The security model is simple: if you trust the voting mechanism, you can trust the oracle output, unless 7 providers get corrupted at the same time. If you trust the current set of oracle providers, you can trust the output for at least the next six weeks, even if you completely do not trust the voting mechanism. Hence, if the voting mechanism gets corrupted, there will be able time for participants in any applications that depend on the oracle to make an orderly exit.Notice the very un-corporate-like nature of this proposal. It involves taking away the governance's ability to act quickly, and intentionally spreading out oracle responsibility across a large number of participants. This is valuable for two reasons. First, it makes it harder for outsiders to attack the oracle, and for new coin holders to quickly take over control of the oracle. Second, it makes it harder for the oracle participants themselves to collude to attack the system. It also mitigates oracle extractable value, where a single provider might intentionally delay publishing to personally profit from a liquidation (in a multi-provider system, if one provider doesn't immediately publish, others soon will).Fairness in KlerosThe "decentralized court" system Kleros is a really valuable and important piece of infrastructure for the Ethereum ecosystem: Proof of Humanity uses it, various "smart contract bug insurance" products use it, and many other projects plug into it as some kind of "adjudication of last resort".Recently, there have been some public concerns about whether or not the platform's decision-making is fair. Some participants have made cases, trying to claim a payout from decentralized smart contract insurance platforms that they argue they deserve. Perhaps the most famous of these cases is Mizu's report on case #1170. The case blew up from being a minor language intepretation dispute into a broader scandal because of the accusation that insiders to Kleros itself were making a coordinated effort to throw a large number of tokens to pushing the decision in the direction they wanted. A participant to the debate writes:The incentives-based decision-making process of the court ... is by all appearances being corrupted by a single dev with a very large (25%) stake in the courts.Of course, this is but one side of one issue in a broader debate, and it's up to the Kleros community to figure out who is right or wrong and how to respond. But zooming out from the question of this individual case, what is important here is the the extent to which the entire value proposition of something like Kleros depends on it being able to convince the public that it is strongly protected against this kind of centralized manipulation. For something like Kleros to be trusted, it seems necessary that there should not be a single individual with a 25% stake in a high-level court. Whether through a more widely distributed token supply, or through more use of non-token-driven governance, a more credibly decentralized form of governance could help Kleros avoid such concerns entirely.Optimism retro fundingOptimism's retroactive founding round 1 results were chosen by a quadratic vote among 24 "badge holders". Round 2 will likely use a larger number of badge holders, and the eventual goal is to move to a system where a much larger body of citizens control retro funding allocation, likely through some multilayered mechanism involving sortition, subcommittees and/or delegation.There have been some internal debates about whether to have more vs fewer citizens: should "citizen" really mean something closer to "senator", an expert contributor who deeply understands the Optimism ecosystem, should it be a position given out to just about anyone who has significantly participated in the Optimism ecosystem, or somewhere in between? My personal stance on this issue has always been in the direction of more citizens, solving governance inefficiency issues with second-layer delegation instead of adding enshrined centralization into the governance protocol. One key reason for my position is the potential for insider trading and self-dealing issues.The Optimism retroactive funding mechanism has always been intended to be coupled with a prospective speculation ecosystem: public-goods projects that need funding now could sell "project tokens", and anyone who buys project tokens becomes eligible for a large retroactively-funded compensation later. But this mechanism working well depends crucially on the retroactive funding part working correctly, and is very vulnerable to the retroactive funding mechanism becoming corrupted. Some example attacks:If some group of people has decided how they will vote on some project, they can buy up (or if overpriced, short) its project token ahead of releasing the decision. If some group of people knows that they will later adjudicate on some specific project, they can buy up the project token early and then intentionally vote in its favor even if the project does not actually deserve funding. Funding deciders can accept bribes from projects. There are typically three ways of dealing with these types of corruption and insider trading issues:Retroactively punish malicious deciders. Proactively filter for higher-quality deciders. Add more deciders. The corporate world typically focuses on the first two, using financial surveillance and judicious penalties for the first and in-person interviews and background checks for the second. The decentralized world has less access to such tools: project tokens are likely to be tradeable anonymously, DAOs have at best limited recourse to external judicial systems, and the remote and online nature of the projects and the desire for global inclusivity makes it harder to do background checks and informal in-person "smell tests" for character. Hence, the decentralized world needs to put more weight on the third technique: distribute decision-making power among more deciders, so that each individual decider has less power, and so collusions are more likely to be whistleblown on and revealed.Should DAOs learn more from corporate governance or political science?Curtis Yarvin, an American philosopher whose primary "big idea" is that corporations are much more effective and optimized than governments and so we should improve governments by making them look more like corporations (eg. by moving away from democracy and closer to monarchy), recently wrote an article expressing his thoughts on how DAO governance should be designed. Not surprisingly, his answer involves borrowing ideas from governance of traditional corporations. From his introduction:Instead the basic design of the Anglo-American limited-liability joint-stock company has remained roughly unchanged since the start of the Industrial Revolution—which, a contrarian historian might argue, might actually have been a Corporate Revolution. If the joint-stock design is not perfectly optimal, we can expect it to be nearly optimal.While there is a categorical difference between these two types of organizations—we could call them first-order (sovereign) and second-order (contractual) organizations—it seems that society in the current year has very effective second-order organizations, but not very effective first-order organizations.Therefore, we probably know more about second-order organizations. So, when designing a DAO, we should start from corporate governance, not political science.Yarvin's post is very correct in identifying the key difference between "first-order" (sovereign) and "second-order" (contractual) organizations - in fact, that exact distinction is precisely the topic of the section in my own post above on credible fairness. However, Yarvin's post makes a big, and surprising, mistake immediately after, by immediately pivoting to saying that corporate governance is the better starting point for how DAOs should operate. The mistake is surprising because the logic of the situation seems to almost directly imply the exact opposite conclusion. Because DAOs do not have a sovereign above them, and are often explicitly in the business of providing services (like currency and arbitration) that are typically reserved for sovereigns, it is precisely the design of sovereigns (political science), and not the design of corporate governance, that DAOs have more to learn from.To Yarvin's credit, the second part of his post does advocate an "hourglass" model that combines a decentralized alignment and accountability layer and a centralized management and execution layer, but this is already an admission that DAO design needs to learn at least as much from first-order orgs as from second-order orgs.Sovereigns are inefficient and corporations are efficient for the same reason why number theory can prove very many things but abstract group theory can prove much fewer things: corporations fail less and accomplish more because they can make more assumptions and have more powerful tools to work with. Corporations can count on their local sovereign to stand up to defend them if the need arises, as well as to provide an external legal system they can lean on to stabilize their incentive structure. In a sovereign, on the other hand, the biggest challenge is often what to do when the incentive structure is under attack and/or at risk of collapsing entirely, with no external leviathan standing ready to support it.Perhaps the greatest problem in the design of successful governance systems for sovereigns is what Samo Burja calls "the succession problem": how to ensure continuity as the system transitions from being run by one group of humans to another group as the first group retires. Corporations, Burja writes, often just don't solve the problem at all:Silicon Valley enthuses over "disruption" because we have become so used to the succession problem remaining unsolved within discrete institutions such as companies.DAOs will need to solve the succession problem eventually (in fact, given the sheer frequency of the "get rich and retire" pattern among crypto early adopters, some DAOs have to deal with succession issues already). Monarchies and corporate-like forms often have a hard time solving the succession problem, because the institutional structure gets deeply tied up with the habits of one specific person, and it either proves difficult to hand off, or there is a very-high-stakes struggle over whom to hand it off to. More decentralized political forms like democracy have at least a theory of how smooth transitions can happen. Hence, I would argue that for this reason too, DAOs have more to learn from the more liberal and democratic schools of political science than they do from the governance of corporations.Of course, DAOs will in some cases have to accomplish specific complicated tasks, and some use of corporate-like forms for accomplishing those tasks may well be a good idea. Additionally, DAOs need to handle unexpected uncertainty. A system that was intended to function in a stable and unchanging way around one set of assumptions, when faced with an extreme and unexpected change to those circumstances, does need some kind of brave leader to coordinate a response. A prototypical example of the latter is stablecoins handling a US dollar collapse: what happens when a stablecoin DAO that evolved around the assumption that it's just trying to track the US dollar suddenly faces a world where the US dollar is no longer a viable thing to be tracking, and a rapid switch to some kind of CPI is needed? Stylized diagram of the internal experience of the RAI ecosystem going through an unexpected transition to a CPI-based regime if the USD ceases to be a viable reference asset. Here, corporate governance-inspired approaches may seem better, because they offer a ready-made pattern for responding to such a problem: the founder organizes a pivot. But as it turns out, the history of political systems also offers a pattern well-suited to this situation, and one that covers the question of how to go back to a decentralized mode when the crisis is over: the Roman Republic custom of electing a dictator for a temporary term to respond to a crisis.Realistically, we probably only need a small number of DAOs that look more like constructs from political science than something out of corporate governance. But those are the really important ones. A stablecoin does not need to be efficient; it must first and foremost be stable and decentralized. A decentralized court is similar. A system that directs funding for a particular cause - whether Optimism retroactive funding, VitaDAO, UkraineDAO or something else - is optimizing for a much more complicated purpose than profit maximization, and so an alignment solution other than shareholder profit is needed to make sure it keeps using the funds for the purpose that was intended.By far the greatest number of organizations, even in a crypto world, are going to be "contractual" second-order organizations that ultimately lean on these first-order giants for support, and for these organizations, much simpler and leader-driven forms of governance emphasizing agility are often going to make sense. But this should not distract from the fact that the ecosystem would not survive without some non-corporate decentralized forms keeping the whole thing stable. -
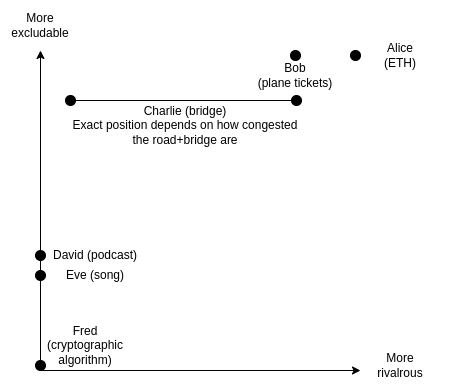
The Revenue-Evil Curve: a different way to think about prioritizing public goods funding The Revenue-Evil Curve: a different way to think about prioritizing public goods funding2022 Oct 28 See all posts The Revenue-Evil Curve: a different way to think about prioritizing public goods funding Special thanks to Karl Floersch, Hasu and Tina Zhen for feedback and review.Public goods are an incredibly important topic in any large-scale ecosystem, but they are also one that is often surprisingly tricky to define. There is an economist definition of public goods - goods that are non-excludable and non-rivalrous, two technical terms that taken together mean that it's difficult to provide them through private property and market-based means. There is a layman's definition of public good: "anything that is good for the public". And there is a democracy enthusiast's definition of public good, which includes connotations of public participation in decision-making.But more importantly, when the abstract category of non-excludable non-rivalrous public goods interacts with the real world, in almost any specific case there are all kinds of subtle edge cases that need to be treated differently. A park is a public good. But what if you add a $5 entrance fee? What if you fund it by auctioning off the right to have a statue of the winner in the park's central square? What if it's maintained by a semi-altruistic billionaire that enjoys the park for personal use, and designs the park around their personal use, but still leaves it open for anyone to visit?This post will attempt to provide a different way of analyzing "hybrid" goods on the spectrum between private and public: the revenue-evil curve. We ask the question: what are the tradeoffs of different ways to monetize a given project, and how much good can be done by adding external subsidies to remove the pressure to monetize? This is far from a universal framework: it assumes a "mixed-economy" setting in a single monolithic "community" with a commercial market combined with subsidies from a central funder. But it can still tell us a lot about how to approach funding public goods in crypto communities, countries and many other real-world contexts today.The traditional framework: excludability and rivalrousnessLet us start off by understanding how the usual economist lens views which projects are private vs public goods. Consider the following examples:Alice owns 1000 ETH, and wants to sell it on the market. Bob runs an airline, and sells tickets for a flight. Charlie builds a bridge, and charges a toll to pay for it. David makes and releases a podcast. Eve makes and releases a song. Fred invents a new and better cryptographic algorithm for making zero knowledge proofs. We put these situations on a chart with two axes:Rivalrousness: to what extent does one person enjoying the good reduce another person's ability to enjoy it? Excludability: how difficult is it to prevent specific individuals, eg. those who do not pay, from enjoying the good? Such a chart might look like this: Alice's ETH is completely excludable (she has total power to choose who gets her coins), and crypto coins are rivalrous (if one person owns a particular coin, no one else owns that same coin) Bob's plane tickets are excludable, but a tiny bit less rivalrous: there's a chance the plane won't be full. Charlie's bridge is a bit less excludable than plane tickets, because adding a gate to verify payment of tolls takes extra effort (so Charlie can exclude but it's costly, both to him and to users), and its rivalrousness depends on whether the road is congested or not. David's podcast and Eve's song are not rivalrous: one person listening to it does not interfere with another person doing the same. They're a little bit excludable, because you can make a paywall but people can circumvent the paywall. And Fred's cryptographic algorithm is close to not excludable at all: it needs to be open-source for people to trust it, and if Fred tries to patent it, the target user base (open-source-loving crypto users) may well refuse to use the algorithm and even cancel him for it. This is all a good and important analysis. Excludability tells us whether or not you can fund the project by charging a toll as a business model, and rivalrousness tells us whether exclusion is a tragic waste or if it's just an unavoidable property of the good in question that if one person gets it another does not. But if we look at some of the examples carefully, especially the digital examples, we start to see that it misses a very important issue: there are many business models available other than exclusion, and those business models have tradeoffs too.Consider one particular case: David's podcast versus Eve's song. In practice, a huge number of podcasts are released mostly or completely freely, but songs are more often gated with licensing and copyright restrictions. To see why, we need only look at how these podcasts are funded: sponsorships. Podcast hosts typically find a few sponsors, and talk about the sponsors briefly at the start or middle of each episode. Sponsoring songs is harder: you can't suddenly start talking about how awesome Athletic Greens* are in the middle of a love song, because come on, it kills the vibe, man!Can we get beyond focusing solely on exclusion, and talk about monetization and the harms of different monetization strategies more generally? Indeed we can, and this is exactly what the revenue/evil curve is about.The revenue-evil curve, definedThe revenue-evil curve of a product is a two-dimensional curve that plots the answer to the following question:How much harm would the product's creator have to inflict on their potential users and the wider community to earn $N of revenue to pay for building the product?The word "evil" here is absolutely not meant to imply that no quantity of evil is acceptable, and that if you can't fund a project without committing evil you should not do it at all. Many projects make hard tradeoffs that hurt their customers and community in order to ensure sustainable funding, and often the value of the project existing at all greatly outweighs these harms. But nevertheless, the goal is to highlight that there is a tragic aspect to many monetization schemes, and public goods funding can provide value by giving existing projects a financial cushion that enables them to avoid such sacrifices.Here is a rough attempt at plotting the revenue-evil curves of our six examples above: For Alice, selling her ETH at market price is actually the most compassionate thing she could do. If she sells more cheaply, she will almost certainly create an on-chain gas war, trader HFT war, or other similarly value-destructive financial conflict between everyone trying to claim her coins the fastest. Selling above market price is not even an option: no one would buy. For Bob, the socially-optimal price to sell at is the highest price at which all tickets get sold out. If Bob sells below that price, tickets will sell out quickly and some people will not be able to get seats at all even if they really need them (underpricing may have a few countervailing benefits by giving opportunities to poor people, but it is far from the most efficient way to achieve that goal). Bob could also sell above market price and potentially earn a higher profit at the cost of selling fewer seats and (from the god's-eye perspective) needlessly excluding people. If Charlie's bridge and the road leading to it are uncongested, charging any toll at all imposes a burden and needlessly excludes drivers. If they are congested, low tolls help by reducing congestion and high tolls needlessly exclude people. David's podcast can monetize to some extent without hurting listeners much by adding advertisements from sponsors. If pressure to monetize increases, David would have to adopt more and more intrusive forms of advertising, and truly maxing out on revenue would require paywalling the podcast, a high cost to potential listeners. Eve is in the same position as David, but with fewer low-harm options (perhaps selling an NFT?). Especially in Eve's case, paywalling may well require actively participating in the legal apparatus of copyright enforcement and suing infringers, which carries further harms. Fred has even fewer monetization options. He could patent it, or potentially do exotic things like auction off the right to choose parameters so that hardware manufacturers that favor particular values would bid on it. All options are high-cost. What we see here is that there are actually many kinds of "evil" on the revenue-evil curve:Traditional economic deadweight loss from exclusion: if a product is priced above marginal cost, mutually beneficial transactions that could have taken place do not take place Race conditions: congestion, shortages and other costs from products being too cheap. "Polluting" the product in ways that make it appealing to a sponsor, but is harmful to a (maybe small, maybe large) degree to listeners. Engaging in offensive actions through the legal system, which increases everyone's fear and need to spend money on lawyers, and has all kinds of hard-to-predict secondary chilling effects. This is particularly severe in the case of patenting. Sacrificing on principles highly valued by the users, the community and even the people working on the project itself. In many cases, this evil is very context-dependent. Patenting is both extremely harmful and ideologically offensive within the crypto space and software more broadly, but this is less true in industries building physical goods: in physical goods industries, most people who realistically can create a derivative work of something patented are going to be large and well-organized enough to negotiate for a license, and capital costs mean that the need for monetization is much higher and hence maintaining purity is harder. To what extent advertisements are harmful depends on the advertiser and the audience: if the podcaster understands the audience very well, ads can even be helpful! Whether or not the possibility to "exclude" even exists depends on property rights.But by talking about committing evil for the sake of earning revenue in general terms, we gain the ability to compare these situations against each other.What does the revenue-evil curve tell us about funding prioritization?Now, let's get back to the key question of why we care about what is a public good and what is not: funding prioritization. If we have a limited pool of capital that is dedicated to helping a community prosper, which things should we direct funding to? The revenue-evil curve graphic gives us a simple starting point for an answer: direct funds toward those projects where the slope of the revenue-evil curve is the steepest.We should focus on projects where each $1 of subsidies, by reducing the pressure to monetize, most greatly reduces the evil that is unfortunately required to make the project possible. This gives us roughly this ranking:Top of the line are "pure" public goods, because often there aren't any ways to monetize them at all, or if there are, the economic or moral costs of trying to monetize are extremely high. Second priority is "naturally" public but monetizable goods that can be funded through commercial channels by tweaking them a bit, like songs or sponsorships to a podcast. Third priority is non-commodity-like private goods where social welfare is already optimized by charging a fee, but where profit margins are high or more generally there are opportunities to "pollute" the product to increase revenue, eg. by keeping accompanying software closed-source or refusing to use standards, and subsidies could be used to push such projects to make more pro-social choices on the margin. Notice that the excludability and rivalrousness framework usually outputs similar answers: focus on non-excludable and non-rivalrous goods first, excludable goods but non-rivalrous second, and excludable and partially rivalrous goods last - and excludable and rivalrous goods never (if you have capital left over, it's better to just give it out as a UBI). There is a rough approximate mapping between revenue/evil curves and excludability and rivalrousness: higher excludability means lower slope of the revenue/evil curve, and rivalrousness tells us whether the bottom of the revenue/evil curve is zero or nonzero. But the revenue/evil curve is a much more general tool, which allows us to talk about tradeoffs of monetization strategies that go far beyond exclusion.One practical example of how this framework can be used to analyze decision-making is Wikimedia donations. I personally have never donated to Wikimedia, because I've always thought that they could and should fund themselves without relying on limited public-goods-funding capital by just adding a few advertisements, and this would be only a small cost to their user experience and neutrality. Wikipedia admins, however, disagree; they even have a wiki page listing their arguments why they disagree.We can understand this disagreement as a dispute over revenue-evil curves: I think Wikimedia's revenue-evil curve has a low slope ("ads are not that bad"), and therefore they are low priority for my charity dollars; some other people think their revenue-evil curve has a high slope, and therefore they are high priority for their charity dollars.Revenue-evil curves are an intellectual tool, NOT a good direct mechanismOne important conclusion that it is important NOT to take from this idea is that we should try to use revenue-evil curves directly as a way of prioritizing individual projects. There are severe constraints on our ability to do this because of limits to monitoring.If this framework is widely used, projects would have an incentive to misrepresent their revenue-evil curves. Anyone charging a toll would have an incentive to come up with clever arguments to try to show that the world would be much better if the toll could be 20% lower, but because they're desperately under-budget, they just can't lower the toll without subsidies. Projects would have an incentive to be more evil in the short term, to attract subsidies that help them become less evil.For these reasons, it is probably best to use the framework not as a way to allocate decisions directly, but to identify general principles for what kinds of projects to prioritize funding for. For example, the framework can be a valid way to determine how to prioritize whole industries or whole categories of goods. It can help you answer questions like: if a company is producing a public good, or is making pro-social but financially costly choices in the design of a not-quite-public good, do they deserve subsidies for that? But even here, it's better to treat revenue-evil curves as a mental tool, rather than attempting to precisely measure them and use them to make individual decisions.ConclusionsExcludability and rivalrousness are important dimensions of a good, that have really important consequences for its ability to monetize itself, and for answering the question of how much harm can be averted by funding it out of some public pot. But especially once more complex projects enter the fray, these two dimensions quickly start to become insufficient for determining how to prioritize funding. Most things are not pure public goods: they are some hybrid in the middle, and there are many dimensions on which they could become more or less public that do not easily map to "exclusion".Looking at the revenue-evil curve of a project gives us another way of measuring the statistic that really matters: how much harm can be averted by relieving a project of one dollar of monetization pressure? Sometimes, the gains from relieving monetization pressure are decisive: there just is no way to fund certain kinds of things through commercial channels, until you can find one single user that benefits from them enough to fund them unilaterally. Other times, commercial funding options exist, but have harmful side effects. Sometimes these effects are smaller, sometimes they are greater. Sometimes a small piece of an individual project has a clear tradeoff between pro-social choices and increasing monetization. And, still other times, projects just fund themselves, and there is no need to subsidize them - or at least, uncertainties and hidden information make it too hard to create a subsidy schedule that does more good than harm. It's always better to prioritize funding in order of greatest gains to smallest; and how far you can go depends on how much funding you have.* I did not accept sponsorship money from Athletic Greens. But the podcaster Lex Fridman did. And no, I did not accept sponsorship money from Lex Fridman either. But maybe someone else did. Whatevs man, as long as we can keep getting podcasts funded so they can be free-to-listen without annoying people too much, it's all good, you know?
-
Should there be demand-based recurring fees on ENS domains? Should there be demand-based recurring fees on ENS domains?2022 Sep 09 See all posts Should there be demand-based recurring fees on ENS domains? Special thanks to Lars Doucet, Glen Weyl and Nick Johnson for discussion and feedback on various topics.ENS domains today are cheap. Very cheap. The cost to register and maintain a five-letter domain name is only $5 per year. This sounds reasonable from the perspective of one person trying to register a single domain, but it looks very different when you look at the situation globally: when ENS was younger, someone could have registered all 8938 five-letter words in the Scrabble wordlist (which includes exotic stuff like "BURRS", "FLUYT" and "ZORIL") and pre-paid their ownership for a hundred years, all for the price of a dozen lambos. And in fact, many people did: today, almost all of those five-letter words are already taken, many by squatters waiting for someone to buy the domain from them at a much higher price. A random scrape of OpenSea shows that about 40% of all these domains are for sale or have been sold on that platform alone.The question worth asking is: is this really the best way to allocate domains? By selling off these domains so cheaply, ENS DAO is almost certainly gathering far less revenue than it could, which limits its ability to act to improve the ecosystem. The status quo is also bad for fairness: being able to buy up all the domains cheaply was great for people in 2017, is okay in 2022, but the consequences may severely handicap the system in 2050. And given that buying a five-letter-word domain in practice costs anywhere from 0.1 to 500 ETH, the notionally cheap registration prices are not actually providing cost savings to users. In fact, there are deep economic reasons to believe that reliance on secondary markets makes domains more expensive than a well-designed in-protocol mechanism.Could we allocate ongoing ownership of domains in a better way? Is there a way to raise more revenue for ENS DAO, do a better job of ensuring domains go to those who can make best use of them, and at the same time preserve the credible neutrality and the accessible very strong guarantees of long-term ownership that make ENS valuable?Problem 1: there is a fundamental tradeoff between strength of property rights and fairnessSuppose that there are \(N\) "high-value names" (eg. five-letter words in the Scrabble dictionary, but could be any similar category). Suppose that each year, users grab up \(k\) names, and some portion \(p\) of them get grabbed by someone who's irrationally stubborn and not willing to give them up (\(p\) could be really low, it just needs to be greater than zero). Then, after \(\frac\) years, no one will be able to get a high-value name again.This is a two-line mathematical theorem, and it feels too simple to be saying anything important. But it actually gets at a crucial truth: time-unlimited allocation of a finite resource is incompatible with fairness across long time horizons. This is true for land; it's the reason why there have been so many land reforms throughout history, and it's a big part of why many advocate for land taxes today. It's also true for domains, though the problem in the traditional domain space has been temporarily alleviated by a "forced dilution" of early .com holders in the form of a mass introduction of .io, .me, .network and many other domains. ENS has soft-committed to not add new TLDs to avoid polluting the global namespace and rupturing its chances of eventual integration with mainstream DNS, so such a dilution is not an option.Fortunately, ENS charges not just a one-time fee to register a domain, but also a recurring annual fee to maintain it. Not all decentralized domain name systems had the foresight to implement this; Unstoppable Domains did not, and even goes so far as to proudly advertise its preference for short-term consumer appeal over long-term sustainability ("No renewal fees ever!"). The recurring fees in ENS and traditional DNS are a healthy mitigation to the worst excesses of a truly unlimited pay-once-own-forever model: at the very least, the recurring fees mean that no one will be able to accidentally lock down a domain forever through forgetfulness or carelessness. But it may not be enough. It's still possible to spend $500 to lock down an ENS domain for an entire century, and there are certainly some types of domains that are in high enough demand that this is vastly underpriced.Problem 2: speculators do not actually create efficient marketsOnce we admit that a first-come-first-serve model with low fixed fees has these problems, a common counterargument is to say: yes, many of the names will get bought up by speculators, but speculation is natural and good. It is a free market mechanism, where speculators who actually want to maximize their profit are motivated to resell the domain in such a way that it goes to whoever can make the best use of the domain, and their outsized returns are just compensation for this service.But as it turns out, there has been academic research on this topic, and it is not actually true that profit-maximizing auctioneers maximize social welfare! Quoting Myerson 1981:By announcing a reservation price of 50, the seller risks a probability \((1 / 2^n)\) of keeping the object even though some bidder is willing to pay more than \(t_0\) for it; but the seller also increases his expected revenue, because he can command a higher price when the object is sold.Thus the optimal auction may not be ex-post efficient. To see more clearly why this can happen, consider the example in the above paragraph, for the case when \(n = 1\) ... Ex post efficiency would require that the bidder must always get the object, as long as his value estimate is positive. But then the bidder would never admit to more than an infinitesimal value estimate, since any positive bid would win the object ... In fact the seller's optimal policy is to refuse to sell the object for less than 50.Translated into diagram form: Maximizing revenue for the seller almost always requires accepting some probability of never selling the domain at all, leaving it unused outright. One important nuance in the argument is that seller-revenue-maximizing auctions are at their most inefficient when there is one possible buyer (or at least, one buyer with a valuation far above the others), and the inefficiency decreases quickly once there are many competing potential buyers. But for a large class of domains, the first category is precisely the situation they are in. Domains that are simply some person, project or company's name, for example, have one natural buyer: that person or project. And so if a speculator buys up such a name, they will of course set the price high, accepting a large chance of never coming to a deal to maximize their revenue in the case where a deal does arise.Hence, we cannot say that speculators grabbing a large portion of domain allocation revenues is merely just compensation for them ensuring that the market is efficient. On the contrary, speculators can easily make the market worse than a well-designed mechanism in the protocol that encourages domains to be directly available for sale at fair prices.One cheer for stricter property rights: stability of domain ownership has positive externalitiesThe monopoly problems of overly-strict property rights on non-fungible assets have been known for a long time. Resolving this issue in a market-based way was the original goal of Harberger taxes: require the owner of each covered asset to set a price at which they are willing to sell it to anyone else, and charge an annual fee based on that price. For example, one could charge 0.5% of the sale price every year. Holders would be incentivized to leave the asset available for purchase at prices that are reasonable, "lazy" holders who refuse to sell would lose money every year, and hoarding assets without using them would in many cases become economically infeasible outright.But the risk of being forced to sell something at any time can have large economic and psychological costs, and it's for this reason that advocates of Harberger taxes generally focus on industrial property applications where the market participants are sophisticated. Where do domains fall on the spectrum? Let us consider the costs of a business getting "relocated", in three separate cases: a data center, a restaurant, and an ENS name. Data center Restaurant ENS name Confusion from people expecting old location An employee comes to the old location, and unexpectedly finds it closed. An employee or a customer comes to the old location, and unexpectedly finds it closed. Someone sends a big chunk of money to the wrong address. Loss of location-specific long-term investment Low The restaurant will probably lose many long-term customers for whom the new location is too far away The owner spent years building a brand around the old name that cannot easily carry over. As it turns out, domains do not hold up very well. Domain name owners are often not sophisticated, the costs of switching domain names are often high, and negative externalities of a name-change gone wrong can be large. The highest-value owner of coinbase.eth may not be Coinbase; it could just as easily be a scammer who would grab up the domain and then immediately make a fake charity or ICO claiming it's run by Coinbase and ask people to send that address their money. For these reasons, Harberger taxing domains is not a great idea.Alternative solution 1: demand-based recurring pricingMaintaining ownership over an ENS domain today requires paying a recurring fee. For most domains, this is a simple and very low $5 per year. The only exceptions are four-letter domains ($160 per year) and three-letter domains ($640 per year). But what if instead, we make the fee somehow depend on the actual level of market demand for the domain?This would not be a Harberger-like scheme where you have to make the domain available for immediate sale at a particular price. Rather, the initiative in the price-setting procedure would fall on the bidders. Anyone could bid on a particular domain, and if they keep an open bid for a sufficiently long period of time (eg. 4 weeks), the domain's valuation rises to that level. The annual fee on the domain would be proportional to the valuation (eg. it might be set to 0.5% of the valuation). If there are no bids, the fee might decay at a constant rate. When a bidder sends their bid amount into a smart contract to place a bid, the owner has two options: they could either accept the bid, or they could reject, though they may have to start paying a higher price. If a bidder bids a value higher than the actual value of the domain, the owner could sell to them, costing the bidder a huge amount of money.This property is important, because it means that "griefing" domain holders is risky and expensive, and may even end up benefiting the victim. If you own a domain, and a powerful actor wants to harass or censor you, they could try to make a very high bid for that domain to greatly increase your annual fee. But if they do this, you could simply sell to them and collect the massive payout.This already provides much more stability and is more noob-friendly than a Harberger tax. Domain owners don't need to constantly worry whether or not they're setting prices too low. Rather, they can simply sit back and pay the annual fee, and if someone offers to bid they can take 4 weeks to make a decision and either sell the domain or continue holding it and accept the higher fee. But even this probably does not provide quite enough stability. To go even further, we need a compromise on the compromise.Alternative solution 2: capped demand-based recurring pricingWe can modify the above scheme to offer even stronger guarantees to domain-name holders. Specifically, we can try to offer the following property:Strong time-bound ownership guarantee: for any fixed number of years, it's always possible to compute a fixed amount of money that you can pre-pay to unconditionally guarantee ownership for at least that number of years.In math language, there must be some function \(y = f(n)\) such that if you pay \(y\) dollars (or ETH), you get a hard guarantee that you will be able to hold on to the domain for at least \(n\) years, no matter what happens. \(f\) may also depend on other factors, such as what happened to the domain previously, as long as those factors are known at the time the transaction to register or extend a domain is made. Note that the maximum annual fee after \(n\) years would be the derivative \(f'(n)\).The new price after a bid would be capped at the implied maximum annual fee. For example, if \(f(n) = \fracn^2\), so \(f'(n) = n\), and you get a bid of $5 after 7 years, the annual fee would rise to $5, but if you get a bid of $10 after 7 years, the annual fee would only rise to $7. If no bids that raise the fee to the max are made for some length of time (eg. a full year), \(n\) resets. If a bid is made and rejected, \(n\) resets.And of course, we have a highly subjective criterion that \(f(n)\) must be "reasonable". We can create compromise proposals by trying different shapes for \(f\):Type \(f(n)\) (\(p_0\) = price of last sale or last rejected bid, or $1 if most recent event is a reset) In plain English Total cost to guarantee holding for >= 10 years Total cost to guarantee holding for >= 100 years Exponential fee growth \(f(n) = \int_0^n p_0 * 1.1^n\) The fee can grow by a maximum of 10% per year (with compounding). $836 $7.22m Linear fee growth \(f(n) = p_0 * n + \fracn^2\) The annual fee can grow by a maximum of $15 per year. $1250 $80k Capped annual fee \(f(n) = 640 * n\) The annual fee cannot exceed $640 per year. That is, a domain in high demand can start to cost as much as a three-letter domain, but not more. $6400 $64k Or in chart form: Note that the amounts in the table are only the theoretical maximums needed to guarantee holding a domain for that number of years. In practice, almost no domains would have bidders willing to bid very high amounts, and so holders of almost all domains would end up paying much less than the maximum.One fascinating property of the "capped annual fee" approach is that there are versions of it that are strictly more favorable to existing domain-name holders than the status quo. In particular, we could imagine a system where a domain that gets no bids does not have to pay any annual fee, and a bid could increase the annual fee to a maximum of $5 per year.Demand from external bids clearly provides some signal about how valuable a domain is (and therefore, to what extent an owner is excluding others by maintaining control over it). Hence, regardless of your views on what level of fees should be required to maintain a domain, I would argue that you should find some parameter choice for demand-based fees appealing.I will still make my case for why some superlinear \(f(n)\), a max annual fee that goes up over time, is a good idea. First, paying more for longer-term security is a common feature throughout the economy. Fixed-rate mortgages usually have higher interest rates than variable-rate mortgages. You can get higher interest by providing deposits that are locked up for longer periods of time; this is compensation the bank pays you for providing longer-term security to the bank. Similarly, longer-term government bonds typically have higher yields. Second, the annual fee should be able to eventually adjust to whatever the market value of the domain is; we just don't want that to happen too quickly.Superlinear \(f(n)\) values still make hard guarantees of ownership reasonably accessible over pretty long timescales: with the linear-fee-growth formula \(f(n) = p_0 * n + \fracn^2\), for only $6000 ($120 per year) you could ensure ownership of the domain for 25 years, and you would almost certainly pay much less. The ideal of "register and forget" for censorship-resistant services would still be very much available.From here to thereWeakening property norms, and increasing fees, is psychologically very unappealing to many people. This is true even when these fees make clear economic sense, and even when you can redirect fee revenue into a UBI and mathematically show that the majority of people would economically net-benefit from your proposal. Cities have a hard time adding congestion pricing, even when it's painfully clear that the only two choices are paying congestion fees in dollars and paying congestion fees in wasted time and weakened mental health driving in painfully slow traffic. Land value taxes, despite being in many ways one of the most effective and least harmful taxes out there, have a hard time getting adopted. Unstoppable Domains's loud and proud advertisement of "no renewal fees ever" is in my view very short-sighted, but it's clearly at least somewhat effective. So how could I possibly think that we have any chance of adding fees and conditions to domain name ownership?The crypto space is not going to solve deep challenges in human political psychology that humanity has failed at for centuries. But we do not have to. I see two possible answers that do have some realistic hope for success:Democratic legitimacy: come up with a compromise proposal that really is a sufficient compromise that it makes enough people happy, and perhaps even makes some existing domain name holders (not just potential domain name holders) better off than they are today.For example, we could implement demand-based annual fees (eg. setting the annual fee to 0.5% of the highest bid) with a fee cap of $640 per year for domains up to eight letters long, and $5 per year for longer domains, and let domain holders pay nothing if no one makes a bid. Many average users would save money under such a proposal. Market legitimacy: avoid the need to get legitimacy to overturn people's expectations in the existing system by instead creating a new system (or sub-system).In traditional DNS, this could be done just by creating a new TLD that would be as convenient as existing TLDs. In ENS, there is a stated desire to stick to .eth only to avoid conflicting with the existing domain name system. And using existing subdomains doesn't quite work: foo.bar.eth is much less nice than foo.eth. One possible middle route is for the ENS DAO to hand off single-letter domain names solely to projects that run some other kind of credibly-neutral marketplace for their subdomains, as long as they hand over at least 50% of the revenue to the ENS DAO.For example, perhaps x.eth could use one of my proposed pricing schemes for its subdomains, and t.eth could implement a mechanism where ENS DAO has the right to forcibly transfer subdomains for anti-fraud and trademark reasons. foo.x.eth just barely looks good enough to be sort-of a substitute for foo.eth; it will have to do. If making changes to ENS domain pricing itself are off the table, then the market-based approach of explicitly encouraging marketplaces with different rules in subdomains should be strongly considered.To me, the crypto space is not just about coins, and I admit my attraction to ENS does not center around some notion of unconditional and infinitely strict property-like ownership over domains. Rather, my interest in the space lies more in credible neutrality, and property rights that are strongly protected particularly against politically motivated censorship and arbitrary and targeted interference by powerful actors. That said, a high degree of guarantee of ownership is nevertheless very important for a domain name system to be able to function.The hybrid proposals I suggest above are my attempt at preserving total credible neutrality, continuing to provide a high degree of ownership guarantee, but at the same time increasing the cost of domain squatting, raising more revenue for the ENS DAO to be able to work on important public goods, and improving the chances that people who do not have the domain they want already will be able to get one.
-
What kind of layer 3s make sense? What kind of layer 3s make sense?2022 Sep 17 See all posts What kind of layer 3s make sense? Special thanks to Georgios Konstantopoulos, Karl Floersch and the Starkware team for feedback and review.One topic that often re-emerges in layer-2 scaling discussions is the concept of "layer 3s". If we can build a layer 2 protocol that anchors into layer 1 for security and adds scalability on top, then surely we can scale even more by building a layer 3 protocol that anchors into layer 2 for security and adds even more scalability on top of that?A simple version of this idea goes: if you have a scheme that can give you quadratic scaling, can you stack the scheme on top of itself and get exponential scaling? Ideas like this include my 2015 scalability paper, the multi-layer scaling ideas in the Plasma paper, and many more. Unfortunately, such simple conceptions of layer 3s rarely quite work out that easily. There's always something in the design that's just not stackable, and can only give you a scalability boost once - limits to data availability, reliance on L1 bandwidth for emergency withdrawals, or many other issues.Newer ideas around layer 3s, such as the framework proposed by Starkware, are more sophisticated: they aren't just stacking the same thing on top of itself, they're assigning the second layer and the third layer different purposes. Some form of this approach may well be a good idea - if it's done in the right way. This post will get into some of the details of what might and might not make sense to do in a triple-layered architecture.Why you can't just keep scaling by stacking rollups on top of rollupsRollups (see my longer article on them here) are a scaling technology that combines different techniques to address the two main scaling bottlenecks of running a blockchain: computation and data. Computation is addressed by either fraud proofs or SNARKs, which rely on a very small number of actors to process and verify each block, requiring everyone else to perform only a tiny amount of computation to check that the proving process was done correctly. These schemes, especially SNARKs, can scale almost without limit; you really can just keep making "a SNARK of many SNARKs" to scale even more computation down to a single proof.Data is different. Rollups use a collection of compression tricks to reduce the amount of data that a transaction needs to store on-chain: a simple currency transfer decreases from ~100 to ~16 bytes, an ERC20 transfer in an EVM-compatible chain from ~180 to ~23 bytes, and a privacy-preserving ZK-SNARK transaction could be compressed from ~600 to ~80 bytes. About 8x compression in all cases. But rollups still need to make data available on-chain in a medium that users are guaranteed to be able to access and verify, so that users can independently compute the state of the rollup and join as provers if existing provers go offline. Data can be compressed once, but it cannot be compressed again - if it can, then there's generally a way to put the logic of the second compressor into the first, and get the same benefit by compressing once. Hence, "rollups on top of rollups" are not something that can actually provide large gains in scalability - though, as we will see below, such a pattern can serve other purposes.So what's the "sane" version of layer 3s?Well, let's look at what Starkware, in their post on layer 3s, advocates. Starkware is made up of very smart cryptographers who are actually sane, and so if they are advocating for layer 3s, their version will be much more sophisticated than "if rollups compress data 8x, then obviously rollups on top of rollups will compress data 64x".Here's a diagram from Starkware's post: A few quotes:An example of such an ecosystem is depicted in Diagram 1. Its L3s include:A StarkNet with Validium data availability, e.g., for general use by applications with extreme sensitivity to pricing. App-specific StarkNet systems customized for better application performance, e.g., by employing designated storage structures or data availability compression. StarkEx systems (such as those serving dYdX, Sorare, Immutable, and DeversiFi) with Validium or Rollup data availability, immediately bringing battle-tested scalability benefits to StarkNet. Privacy StarkNet instances (in this example also as an L4) to allow privacy-preserving transactions without including them in public StarkNets. We can compress the article down into three visions of what "L3s" are for:L2 is for scaling, L3 is for customized functionality, for example privacy. In this vision there is no attempt to provide "scalability squared"; rather, there is one layer of the stack that helps applications scale, and then separate layers for customized functionality needs of different use cases. L2 is for general-purpose scaling, L3 is for customized scaling. Customized scaling might come in different forms: specialized applications that use something other than the EVM to do their computation, rollups whose data compression is optimized around data formats for specific applications (including separating "data" from "proofs" and replacing proofs with a single SNARK per block entirely), etc. L2 is for trustless scaling (rollups), L3 is for weakly-trusted scaling (validiums). Validiums are systems that use SNARKs to verify computation, but leave data availability up to a trusted third party or committee. Validiums are in my view highly underrated: in particular, many "enterprise blockchain" applications may well actually be best served by a centralized server that runs a validium prover and regularly commits hashes to chain. Validiums have a lower grade of security than rollups, but can be vastly cheaper. All three of these visions are, in my view, fundamentally reasonable. The idea that specialized data compression requires its own platform is probably the weakest of the claims - it's quite easy to design a layer 2 with a general-purpose base-layer compression scheme that users can automatically extend with application-specific sub-compressors - but otherwise the use cases are all sound. But this still leaves open one large question: is a three-layer structure the right way to accomplish these goals? What's the point of validiums, and privacy systems, and customized environments, anchoring into layer 2 instead of just anchoring into layer 1? The answer to this question turns out to be quite complicated. Which one is actually better? Does depositing and withdrawing become cheaper and easier within a layer 2's sub-tree?One possible argument for the three-layer model over the two-layer model is: a three-layer model allows an entire sub-ecosystem to exist within a single rollup, which allows cross-domain operations within that ecosystem to happen very cheaply, without needing to go through the expensive layer 1.But as it turns out, you can do deposits and withdrawals cheaply even between two layer 2s (or even layer 3s) that commit to the same layer 1! The key realization is that tokens and other assets do not have to be issued in the root chain. That is, you can have an ERC20 token on Arbitrum, create a wrapper of it on Optimism, and move back and forth between the two without any L1 transactions!Let us examine how such a system works. There are two smart contracts: the base contract on Arbitrum, and the wrapper token contract on Optimism. To move from Arbitrum to Optimism, you would send your tokens to the base contract, which would generate a receipt. Once Arbitrum finalizes, you can take a Merkle proof of that receipt, rooted in L1 state, and send it into the wrapper token contract on Optimism, which verifies it and issues you a wrapper token. To move tokens back, you do the same thing in reverse. Even though the Merkle path needed to prove the deposit on Arbitrum goes through the L1 state, Optimism only needs to read the L1 state root to process the deposit - no L1 transactions required. Note that because data on rollups is the scarcest resource, a practical implementation of such a scheme would use a SNARK or a KZG proof, rather than a Merkle proof directly, to save space. Such a scheme has one key weakness compared to tokens rooted on L1, at least on optimistic rollups: depositing also requires waiting the fraud proof window. If a token is rooted on L1, withdrawing from Arbitrum or Optimism back to L1 takes a week delay, but depositing is instant. In this scheme, however, both depositing and withdrawing take a week delay. That said, it's not clear that a three-layer architecture on optimistic rollups is better: there's a lot of technical complexity in ensuring that a fraud proof game happening inside a system that itself runs on a fraud proof game is safe.Fortunately, neither of these issues will be a problem on ZK rollups. ZK rollups do not require a week-long waiting window for security reasons, but they do still require a shorter window (perhaps 12 hours with first-generation technology) for two other reasons. First, particularly the more complex general-purpose ZK-EVM rollups need a longer amount of time to cover non-parallelizable compute time of proving a block. Second, there is the economic consideration of needing to submit proofs rarely to minimize the fixed costs associated with proof transactions. Next-gen ZK-EVM technology, including specialized hardware, will solve the first problem, and better-architected batch verification can solve the second problem. And it's precisely the issue of optimizing and batching proof submission that we will get into next.Rollups and validiums have a confirmation time vs fixed cost tradeoff. Layer 3s can help fix this. But what else can?The cost of a rollup per transaction is cheap: it's just 16-60 bytes of data, depending on the application. But rollups also have to pay a high fixed cost every time they submit a batch of transactions to chain: 21000 L1 gas per batch for optimistic rollups, and more than 400,000 gas for ZK rollups (millions of gas if you want something quantum-safe that only uses STARKs).Of course, rollups could simply choose to wait until there's 10 million gas worth of L2 transactions to submit a batch, but this would give them very long batch intervals, forcing users to wait much longer until they get a high-security confirmation. Hence, they have a tradeoff: long batch intervals and optimum costs, or shorter batch intervals and greatly increased costs.To give us some concrete numbers, let us consider a ZK rollup that has 600,000 gas per-batch costs and processes fully optimized ERC20 transfers (23 bytes), which cost 368 gas per transaction. Suppose that this rollup is in early to mid stages of adoption, and is averaging 5 TPS. We can compute gas per transaction vs batch intervals:Batch interval Gas per tx (= tx cost + batch cost / (TPS * batch interval)) 12s (one per Ethereum block) 10368 1 min 2368 10 min 568 1 h 401 If we're entering a world with lots of customized validiums and application-specific environments, then many of them will do much less than 5 TPS. Hence, tradeoffs between confirmation time and cost start to become a very big deal. And indeed, the "layer 3" paradigm does solve this! A ZK rollup inside a ZK rollup, even implemented naively, would have fixed costs of only ~8,000 layer-1 gas (500 bytes for the proof). This changes the table above to:Batch interval Gas per tx (= tx cost + batch cost / (TPS * batch interval)) 12s (one per Ethereum block) 501 1 min 394 10 min 370 1 h 368 Problem basically solved. So are layer 3s good? Maybe. But it's worth noticing that there is a different approach to solving this problem, inspired by ERC 4337 aggregate verification.The strategy is as follows. Today, each ZK rollup or validium accepts a state root if it receives a proof proving that \(S_ = STF(S_, D)\): the new state root must be the result of correctly processing the transaction data or state deltas on top of the old state root. In this new scheme, the ZK rollup would accept a message from a batch verifier contract that says that it has verified a proof of a batch of statements, where each of those statements is of the form \(S_ = STF(S_, D)\). This batch proof could be constructed via a recursive SNARK scheme or Halo aggregation. This would be an open protocol: any ZK-rollup could join, and any batch prover could aggregate proofs from any compatible ZK-rollup, and would get compensated by the aggregator with a transaction fee. The batch handler contract would verify the proof once, and then pass off a message to each rollup with the \((S_, S_, D)\) triple for that rollup; the fact that the triple came from the batch handler contract would be evidence that the transition is valid.The cost per rollup in this scheme could be close to 8000 if it's well-optimized: 5000 for a state write adding the new update, 1280 for the old and new root, and an extra 1720 for miscellaneous data juggling. Hence, it would give us the same savings. Starkware actually has something like this already, called SHARP, though it is not (yet) a permissionless open protocol.One response to this style of approach might be: but isn't this actually just another layer 3 scheme? Instead of base layer
-
My 40-liter backpack travel guide My 40-liter backpack travel guide2022 Jun 20 See all posts My 40-liter backpack travel guide Special thanks to Liam Horne for feedback and review. I received no money from and have never even met any of the companies making the stuff I'm shilling here (with the sole exception of Unisocks); this is all just an honest listing of what works for me today.I have lived as a nomad for the last nine years, taking 360 flights travelling over 1.5 million kilometers (assuming flight paths are straight, ignoring layovers) during that time. During this time, I've considerably optimized the luggage I carry along with me: from a 60-liter shoulder bag with a separate laptop bag, to a 60-liter shoulder bag that can contain the laptop bag, and now to a 40-liter packpage that can contain the laptop bag along with all the supplies I need to live my life.The purpose of this post will be to go through the contents, as well as some of the tips that I've learned for how you too can optimize your travel life and never have to wait at a luggage counter again. There is no obligation to follow this guide in its entirety; if you have important needs that differ from mine, you can still get a lot of the benefits by going a hybrid route, and I will talk about these options too.This guide is focused on my own experiences; plenty of other people have made their own guides and you should look at them too. /r/onebag is an excellent subreddit for this. The backpack, with the various sub-bags laid out separately. Yes, this all fits in the backpack, and without that much effort to pack and unpack. As a point of high-level organization, notice the bag-inside-a-bag structure. I have a T-shirt bag, an underwear bag, a sock bag, a toiletries bag, a dirty-laundry bag, a medicine bag, a laptop bag, and various small bags inside the inner compartment of my backpack, which all fit into a 40-liter Hynes Eagle backpack. This structure makes it easy to keep things organized.It's like frugality, but for cm3 instead of dollarsThe general principle that you are trying to follow is that you're trying to stay within a "budget" while still making sure you have everything that you need - much like normal financial planning of the type that almost everyone, with the important exception of crypto participants during bull runs, is used to dealing with. A key difference here is that instead of optimizing for dollars, you're optimizing for cubic centimeters. Of course, none of the things that I recommend here are going to be particularly hard on your dollars either, but minimizing cm3 is the primary objective.What do I mean by this? Well, I mean getting items like this: Electric shaver. About 5cm long and 2.5cm wide at the top. No charger or handle is required: it's USBC pluggable, your phone is the charger and handle. Buy on Amazon here (told you it's not hard on your dollars!) And this: Charger for mobile phone and laptop (can charge both at the same time)! About 5x5x2.5 cm. Buy here. And there's more. Electric toothbrushes are normally known for being wide and bulky. But they don't have to be! Here is an electric toothbrush that is rechargeable, USBC-friendly (so no extra charging equipment required), only slightly wider than a regular toothbrush, and costs about $30, plus a couple dollars every few months for replacement brush heads. For connecting to various different continents' plugs, you can either use any regular reasonably small universal adapter, or get the Zendure Passport III which combines a universal adapter with a charger, so you can plug in USBC cables to charge your laptop and multiple other devices directly (!!).As you might have noticed, a key ingredient in making this work is to be a USBC maximalist. You should strive to ensure that every single thing you buy is USBC-friendly. Your laptop, your phone, your toothbrush, everything. This ensures that you don't need to carry any extra equipment beyond one charger and 1-2 charging cables. In the last ~3 years, it has become much easier to live the USBC maximalist life; enjoy it!Be a Uniqlo maximalistFor clothing, you have to navigate a tough tradeoff between price, cm3 and the clothing looking reasonably good. Fortunately, many of the more modern brands do a great job of fulfilling all three at the same time! My current strategy is to be a Uniqlo maximalist: altogether, about 70% of the clothing items in my bag are from Uniqlo.This includes:8 T-shirts, of which 6 are this type from Uniqlo 8 pairs of underwear, mostly various Uniqlo products 8 socks, of which none are Uniqlo (I'm less confident about what to do with socks than with other clothing items, more on this later) Heat-tech tights, from Uniqlo Heat-tech sweater, from Uniqlo Packable jacket, from Uniqlo Shorts that also double as a swimsuit, from.... ok fine, it's also Uniqlo. There are other stores that can give you often equally good products, but Uniqlo is easily accessible in many (though not all) of the regions I visit and does a good job, so I usually just start and stop there.SocksSocks are a complicated balancing act between multiple desired traits:Low cm3 Easy to put on Warm (when needed) Comfortable The ideal scenario is if you find low-cut or ankle socks comfortable to wear, and you never go to cold climates. These are very low on cm3, so you can just buy those and be happy. But this doesn't work for me: I sometimes visit cold areas, I don't find ankle socks comfortable and prefer something a bit longer, and I need to be comfortable for my long runs. Furthermore, my large foot size means that Uniqlo's one-size-fits-all approach does not work well for me: though I can put the socks on, it often takes a long time to do so (especially after a shower), and the socks rip often.So I've been exploring various brands to try to find a solution (recently trying CEP and DarnTough). I generally try to find socks that cover the ankle but don't go much higher than that, and I have one pair of long ones for when I go to the snowier places. My sock bag is currently larger than my underwear bag, and only a bit smaller than my T-shirt bag: both a sign of the challenge of finding good socks, and a testament to Uniqlo's amazing Airism T-shirts. Once you do find a pair of socks that you like, ideally you should just buy many copies of the same type. This removes the effort of searching for a matching pair in your bag, and it ensures that if one of your socks rips you don't have to choose between losing the whole pair and wearing mismatched socks.For shoes, you probably want to limit yourself to at most two: some heavier shoes that you can just wear, and some very cm3-light alternative, such as flip-flops.LayersThere is a key mathematical reason why dressing in layers is a good idea: it lets you cover many possible temperature ranges with fewer clothing items. Temperature (°C) Clothing 20° 13° + 7° + 0° + + You want to keep the T-shirt on in all cases, to protect the other layers from getting dirty. But aside from that, the general rule is: if you choose N clothing items, with levels of warmness spread out across powers of two, then you can be comfortable in \(2^N\) different temperature ranges by binary-encoding the expected temperature in the clothing you wear. For not-so-cold climates, two layers (sweater and jacket) are fine. For a more universal range of climates you'll want three layers: light sweater, heavy sweater and heavy jacket, which can cover \(2^3 = 8\) different temperature ranges all the way from summer to Siberian winter (of course, heavy winter jackets are not easily packable, so you may have to just wear it when you get on the plane).This layering principle applies not just to upper-wear, but also pants. I have a pair of thin pants plus Uniqlo tights, and I can wear the thin pants alone in warmer climates and put the Uniqlo tights under them in colder climates. The tights also double as pyjamas.My miscellaneous stuffThe internet constantly yells at me for not having a good microphone. I solved this problem by getting a portable microphone! My workstation, using the Apogee HypeMIC travel microphone (unfortunately micro-USB, not USBC). A toilet paper roll works great as a stand, but I've also found that having a stand is not really necessary and you can just let the microphone lie down beside your laptop. Next, my laptop stand. Laptop stands are great for improving your posture. I have two recommendations for laptop stands, one medium-effective but very light on cm3, and one very effective but heavier on cm3.The lighter one: Majextand The more powerful one: Nexstand Nexstand is the one in the picture above. Majextand is the one glued to the bottom of my laptop now: I have used both, and recommend both. In addition to this I also have another piece of laptop gear: a 20000 mAh laptop-friendly power bank. This adds even more to my laptop's already decent battery life, and makes it generally easy to live on the road.Now, my medicine bag: This contains a combination of various life-extension medicines (metformin, ashwagandha, and some vitamins), and covid defense gear: a CO2 meter (CO2 concentration minus 420 roughly gives you how much human-breathed-out air you're breathing in, so it's a good proxy for virus risk), masks, antigen tests and fluvoxamine. The tests were a free care package from the Singapore government, and they happened to be excellent on cm3 so I carry them around. Covid defense and life extension are both fields where the science is rapidly evolving, so don't blindly follow this static list; follow the science yourself or listen to the latest advice of an expert that you do trust. Air filters and far-UVC (especially 222 nm) lamps are also promising covid defense options, and portable versions exist for both.At this particular time I don't happen to have a first aid kit with me, but in general it's also recommended; plenty of good travel options exist, eg. this.Finally, mobile data. Generally, you want to make sure you have a phone that supports eSIM. These days, more and more phones do. Wherever you go, you can buy an eSIM for that place online. I personally use Airalo, but there are many options. If you are lazy, you can also just use Google Fi, though in my experience Google Fi's quality and reliability of service tends to be fairly mediocre.Have some fun!Not everything that you have needs to be designed around cm3 minimization. For me personally, I have four items that are not particularly cm3 optimized but that I still really enjoy having around. My laptop bag, bought in an outdoor market in Zambia. Unisocks. Sweatpants for indoor use, that are either fox-themed or Shiba Inu-themed depending on whom you ask. Gloves (phone-friendly): I bought the left one for $4 in Mong Kok and the right one for $5 in Chinatown, Toronto back in 2016. By coincidence, I lost different ones from each pair, so the remaining two match. I keep them around as a reminder of the time when money was much more scarce for me. The more you save space on the boring stuff, the more you can leave some space for a few special items that can bring the most joy to your life.How to stay sane as a nomadMany people find the nomad lifestyle to be disorienting, and report feeling comfort from having a "permanent base". I find myself not really having these feelings: I do feel disorientation when I change locations more than once every ~7 days, but as long as I'm in the same place for longer than that, I acclimate and it "feels like home". I can't tell how much of this is my unique difficult-to-replicate personality traits, and how much can be done by anyone. In general, some tips that I recommend are:Plan ahead: make sure you know where you'll be at least a few days in advance, and know where you're going to go when you land. This reduces feelings of uncertainty. Have some other regular routine: for me, it's as simple as having a piece of dark chocolate and a cup of tea every morning (I prefer Bigelow green tea decaf, specifically the 40-packs, both because it's the most delicious decaf green tea I've tried and because it's packaged in a four-teabag-per-bigger-bag format that makes it very convenient and at the same time cm3-friendly). Having some part of your lifestyle the same every day helps me feel grounded. The more digital your life is, the more you get this "for free" because you're staring into the same computer no matter what physical location you're in, though this does come at the cost of nomadding potentially providing fewer benefits. Your nomadding should be embedded in some community: if you're just being a lowest-common-denominator tourist, you're doing it wrong. Find people in the places you visit who have some key common interest (for me, of course, it's blockchains). Make friends in different cities. This helps you learn about the places you visit and gives you an understanding of the local culture in a way that "ooh look at the 800 year old statue of the emperor" never will. Finally, find other nomad friends, and make sure to intersect with them regularly. If home can't be a single place, home can be the people you jump places with. Have some semi-regular bases: you don't have to keep visiting a completely new location every time. Visiting a place that you have seen before reduces mental effort and adds to the feeling of regularity, and having places that you visit frequently gives you opportunities to put stuff down, and is important if you want your friendships and local cultural connections to actually develop. How to compromiseNot everyone can survive with just the items I have. You might have some need for heavier clothing that cannot fit inside one backpack. You might be a big nerd in some physical-stuff-dependent field: I know life extension nerds, covid defense nerds, and many more. You might really love your three monitors and keyboard. You might have children.The 40-liter backpack is in my opinion a truly ideal size if you can manage it: 40 liters lets you carry a week's worth of stuff, and generally all of life's basic necessities, and it's at the same time very carry-friendly: I have never had it rejected from carry-on in all the flights on many kinds of airplane that I have taken it, and when needed I can just barely stuff it under the seat in front of me in a way that looks legit to staff. Once you start going lower than 40 liters, the disadvantages start stacking up and exceeding the marginal upsides. But if 40 liters is not enough for you, there are two natural fallback options:A larger-than-40 liter backpack. You can find 50 liter backpacks, 60 liter backpacks or even larger (I highly recommend backpacks over shoulder bags for carrying friendliness). But the higher you go, the more tiring it is to carry, the more risk there is on your spine, and the more you incur the risk that you'll have a difficult situation bringing it as a carry-on on the plane and might even have to check it. Backpack plus mini-suitcase. There are plenty of carry-on suitcases that you can buy. You can often make it onto a plane with a backpack and a mini-suitcase. This depends on you: you may find this to be an easier-to-carry option than a really big backpack. That said, there is sometimes a risk that you'll have a hard time carrying it on (eg. if the plane is very full) and occasionally you'll have to check something. Either option can get you up to a respectable 80 liters, and still preserve a lot of the benefits of the 40-liter backpack lifestyle. Backpack plus mini-suitcase generally seems to be more popular than the big backpack route. It's up to you to decide which tradeoffs to take, and where your personal values lie!
-
What do I think about network states? What do I think about network states?2022 Jul 13 See all posts What do I think about network states? On July 4, Balaji Srinivasan released the first version of his long-awaited new book describing his vision for "network states": communities organized around a particular vision of how to run their own society that start off as online clubs, but then build up more and more of a presence over time and eventually become large enough to seek political autonomy or even diplomatic recognition.Network states can be viewed as an attempt at an ideological successor to libertarianism: Balaji repeatedly praises The Sovereign Individual (see my mini-review here) as important reading and inspiration, but also departs from its thinking in key ways, centering in his new work many non-individualistic and non-monetary aspects of social relations like morals and community. Network states can also be viewed as an attempt to sketch out a possible broader political narrative for the crypto space. Rather than staying in their own corner of the internet disconnected from the wider world, blockchains could serve as a centerpiece for a new way of organizing large chunks of human society.These are high promises. Can network states live up to them? Do network states actually provide enough benefits to be worth getting excited about? Regardless of the merits of network states, does it actually make sense to tie the idea together with blockchains and cryptocurrency? And on the other hand, is there anything crucially important that this vision of the world misses? This post represents my attempt to try to understand these questions.Table of contentsWhat is a network state? So what kinds of network states could we build? What is Balaji's megapolitical case for network states? Do you have to like Balaji's megapolitics to like network states? What does cryptocurrency have to do with network states? What aspects of Balaji's vision do I like? What aspects of Balaji's vision do I take issue with? Non-Balajian network states Is there a middle way? What is a network state?Balaji helpfully gives multiple short definitions of what a network state is. First, his definition in one sentence:A network state is a highly aligned online community with a capacity for collective action that crowdfunds territory around the world and eventually gains diplomatic recognition from pre-existing states.This so far seems uncontroversial. Create a new internet community online, once it grows big enough materialize it offline, and eventually try to negotiate for some kind of status. Someone of almost any political ideology could find some form of network state under this definition that they could get behind. But now, we get to his definition in a longer sentence:A network state is a social network with a moral innovation, a sense of national consciousness, a recognized founder, a capacity for collective action, an in-person level of civility, an integrated cryptocurrency, a consensual government limited by a social smart contract, an archipelago of crowdfunded physical territories, a virtual capital, and an on-chain census that proves a large enough population, income, and real-estate footprint to attain a measure of diplomatic recognition.Here, the concept starts to get opinionated: we're not just talking about the general concept of online communities that have collective agency and eventually try to materialize on land, we're talking about a specific Balajian vision of what network states should look like. It's completely possible to support network states in general, but have disagreements with the Balajian view of what properties network states should have. If you're not already a "crypto convert", it's hard to see why an "integrated cryptocurrency" is such a fundamental part of the network state concept, for example - though Balaji does later on in the book defend his choices.Finally, Balaji expands on this conception of a Balajian network state in longer-form, first in "a thousand words" (apparently, Balajian network states use base 8, as the actual word count is exactly \(512 = 8^3\)) and then an essay, and at the very end of the book a whole chapter. And, of course, an image. One key point that Balaji stresses across many chapters and pages is the unavoidable moral ingredient required for any successful new community. As Balaji writes:The quick answer comes from Paul Johnson at the 11:00 mark of this talk, where he notes that early America's religious colonies succeeded at a higher rate than its for-profit colonies, because the former had a purpose. The slightly longer answer is that in a startup society, you're not asking people to buy a product (which is an economic, individualistic pitch) but to join a community (which is a cultural, collective pitch).The commitment paradox of religious communes is key here: counterintuitively, it's the religious communes that demand the most of their members that are the most long-lasting. This is where Balajism explicitly diverges from the more traditional neoliberal-capitalist ideal of the defanged, apolitical and passion-free consumerist "last man". Unlike the strawman libertarian, Balaji does not believe that everything can "merely be a consumer product". Rather, he stresses greatly the importance of social norms for cohesion, and a literally religious attachment to the values that make a particular network state distinct from the world outside. As Balaji says in this podcast at 18:20, most current libertarian attempts at micronations are like "Zionism without Judaism", and this is a key part of why they fail.This recognition is not a new one. Indeed, it's at the core of Antonio Garcia Martinez's criticism of Balaji's earlier sovereign-individual ideas (see this podcast at ~27:00), praising the tenacity of Cuban exiles in Miami who "perhaps irrationally, said this is our new homeland, this is our last stand". And in Fukuyama's The End of History:This city, like any city, has foreign enemies and needs to be defended from outside attack. It therefore needs a class of guardians who are courageous and public-spirited, who are willing to sacrifice their material desires and wants for the sake of the common good. Socrates does not believe that courage and public-spiritedness can arise out of a calculation of enlightened self-interest. Rather, they must be rooted in thymos, in the just pride of the guardian class in themselves and in their own city, and their potentially irrational anger against those who threaten it.Balaji's argument in The Network State, as I am interpreting it, is as follows. While we do need political collectives bound not just by economic interest but also by moral force, we don't need to stick with the specific political collectives we have today, which are highly flawed and increasingly unrepresentative of people's values. Rather, we can, and should, create new and better collectives - and his seven-step program tells us how.So what kinds of network states could we build?Balaji outlines a few ideas for network states, which I will condense into two key directions: lifestyle immersion and pro-tech regulatory innovation.Balaji's go-to example for lifestyle immersion is a network state organized around health:Next, let's do an example which requires a network archipelago (with a physical footprint) but not a full network state (with diplomatic recognition). This is Keto Kosher, the sugar-free society.Start with a history of the horrible USDA Food Pyramid, the grain-heavy monstrosity that gave cover to the corporate sugarification of the globe and the obesity epidemic. ... Organize a community online that crowdfunds properties around the world, like apartment buildings and gyms, and perhaps eventually even culdesacs and small towns. You might take an extreme sugar teeotaler approach, literally banning processed foods and sugar at the border, thereby implementing a kind of "Keto Kosher".You can imagine variants of this startup society that are like "Carnivory Communities" or "Paleo People". These would be competing startup societies in the same broad area, iterations on a theme. If successful, such a society might not stop at sugar. It could get into setting cultural defaults for fitness and exercise. Or perhaps it could bulk purchase continuous glucose meters for all members, or orders of metformin.This, strictly speaking, does not require any diplomatic recognition or even political autonomy - though perhaps, in the longer-term future, such enclaves could negotiate for lower health insurance fees and medicare taxes for their members. What does require autonomy? Well, how about a free zone for medical innovation?Now let's do a more difficult example, which will require a full network state with diplomatic recognition. This is the medical sovereignty zone, the FDA-free society.You begin your startup society with Henninger's history of FDA-caused drug lag and Tabarrok's history of FDA interference with so-called "off label" prescription. You point out how many millions were killed by its policies, hand out t-shirts like ACT-UP did, show Dallas Buyers Club to all prospective residents, and make clear to all new members why your cause of medical sovereignty is righteous ...For the case of doing it outside the US, your startup society would ride behind, say, the support of the Malta's FDA for a new biomedical regime. For the case of doing it within the US, you'd need a governor who'd declare a sanctuary state for biomedicine. That is, just like a sanctuary city declares that it won't enforce federal immigration law, a sanctuary state for biomedicine would not enforce FDA writ.One can think up of many more examples for both categories. One could have a zone where it's okay to walk around naked, both securing your legal right to do so and helping you feel comfortable by creating an environment where many other people are naked too. Alternatively, you could have a zone where everyone can only wear basic plain-colored clothing, to discourage what's perceived as a zero-sum status competition of expending huge effort to look better than everyone else. One could have an intentional community zone for cryptocurrency users, requiring every store to accept it and demanding an NFT to get in the zone at all. Or one could build an enclave that legalizes radical experiments in transit and drone delivery, accepting higher risks to personal safety in exchange for the privilege of participating in a technological frontier that will hopefully set examples for the world as a whole.What is common about all of these examples is the value of having a physical region, at least of a few hectares, where the network state's unique rules are enforced. Sure, you could individually insist on only eating at healthy restaurants, and research each restaurant carefully before you go there. But it's just so much easier to have a defined plot of land where you have an assurance that anywhere you go within that plot of land will meet your standards. Of course, you could lobby your local government to tighten health and safety regulations. But if you do that, you risk friction with people who have radically different preferences on tradeoffs, and you risk shutting poor people out of the economy. A network state offers a moderate approach.What is Balaji's megapolitical case for network states?One of the curious features of the book that a reader will notice almost immediately is that it sometimes feels like two books in one: sometimes, it's a book about the concept of network states, and at other times it's an exposition of Balaji's grand megapolitical theory.Balaji's grand megapolitical theory is pretty out-there and fun in a bunch of ways. Near the beginning of the book, he entices readers with tidbits like... ok fine, I'll just quote:Germany sent Vladimir Lenin into Russia, potentially as part of a strategy to destabilize their then-rival in war. Antony Sutton's books document how some Wall Street bankers apparently funded the Russian Revolution (and how other Wall Street bankers funded the Nazis years later). Leon Trotsky spent time in New York prior to the revolution, and propagandistic reporting from Americans like John Reed aided Lenin and Trotsky in their revolution. Indeed, Reed was so useful to the Soviets — and so misleading as to the nature of the revolution — that he was buried at the base of the Kremlin Wall. Surprise: the Russian Revolution wasn't done wholly by Russians, but had significant foreign involvement from Germans and Americans. The Ochs-Sulzberger family, which owns The New York Times Company, owned slaves but didn't report that fact in their 1619 coverage. New York Times correspondent Walter Duranty won a Pulitzer Prize for helping the Soviet Union starve Ukraine into submission, 90 years before the Times decided to instead "stand with Ukraine". You can find a bunch more juicy examples in the chapter titled, appropriately, "If the News is Fake, Imagine History". These examples seem haphazard, and indeed, to some extent they are so intentionally: the goal is first and foremost to shock the reader out of their existing world model so they can start downloading Balaji's own.But pretty soon, Balaji's examples do start to point to some particular themes: a deep dislike of the "woke" US left, exemplified by the New York Times, a combination of strong discomfort with the Chinese Communist Party's authoritarianism with an understanding of why the CCP often justifiably fears the United States, and an appreciation of the love of freedom of the US right (exemplified by Bitcoin maximalists) combined with a dislike of their hostility toward cooperation and order.Next, we get Balaji's overview of the political realignments in recent history, and finally we get to his core model of politics in the present day: NYT, CCP, BTC. Team NYT basically runs the US, and its total lack of competence means that the US is collapsing. Team BTC (meaning, both actual Bitcoin maximalists and US rightists in general) has some positive values, but their outright hostility to collective action and order means that they are incapable of building anything. Team CCP can build, but they are building a dystopian surveillance state that much of the world would not want to live in. And all three teams are waaay too nationalist: they view things from the perspective of their own country, and ignore or exploit everyone else. Even when the teams are internationalist in theory, their specific ways of interpreting their values make them unpalatable outside of a small part of the world.Network states, in Balaji's view, are a "de-centralized center" that could create a better alternative. They combine the love of freedom of team BTC with the moral energy of team NYT and the organization of team CCP, and give us the best benefits of all three (plus a level of international appeal greater than any of the three) and avoid the worst parts.This is Balajian megapolitics in a nutshell. It is not trying to justify network states using some abstract theory (eg. some Dunbar's number or concentrated-incentive argument that the optimal size of a political body is actually in the low tens of thousands). Rather, it is an argument that situates network states as a response to the particular political situation of the world at its current place and time. Balaji's helical theory of history: yes, there are cycles, but there is also ongoing progress. Right now, we're at the part of the cycle where we need to help the sclerotic old order die, but also seed a new and better one. Do you have to agree with Balaji's megapolitics to like network states?Many aspects of Balajian megapolitics will not be convincing to many readers. If you believe that "wokeness" is an important movement that protects the vulnerable, you may not appreciate the almost off-handed dismissal that it is basically just a mask for a professional elite's will-to-power. If you are worried about the plight of smaller countries such as Ukraine who are threatened by aggressive neighbors and desperately need outside support, you will not be convinced by Balaji's plea that "it may instead be best for countries to rearm, and take on their own defense".I do think that you can support network states while disagreeing with some of Balaji's reasoning for them (and vice versa). But first, I should explain why I think Balaji feels that his view of the problem and his view of the solution are connected. Balaji has been passionate about roughly the same problem for a long time; you can see a similar narrative outline of defeating US institutional sclerosis through a technological and exit-driven approach in his speech on "the ultimate exit" from 2013. Network states are the latest iteration of his proposed solution.There are a few reasons why talking about the problem is important:To show that network states are the only way to protect freedom and capitalism, one must show why the US cannot. If the US, or the "democratic liberal order", is just fine, then there is no need for alternatives; we should just double down on global coordination and rule of law. But if the US is in an irreversible decline, and its rivals are ascending, then things look quite different. Network states can "maintain liberal values in an illiberal world"; hegemony thinking that assumes "the good guys are in charge" cannot. Many of Balaji's intended readers are not in the US, and a world of network states would inherently be globally distributed - and that includes lots of people who are suspicious of America. Balaji himself is Indian, and has a large Indian fan base. Many people in India, and elsewhere, view the US not as a "guardian of the liberal world order", but as something much more hypocritical at best and sinister at worst. Balaji wants to make it clear that you do not have to be pro-American to be a liberal (or at least a Balaji-liberal). Many parts of US left-leaning media are increasingly hostile to both cryptocurrency and the tech sector. Balaji expects that the "authoritarian left" parts of "team NYT" will be hostile to network states, and he explains this by pointing out that the media are not angels and their attacks are often self-interested. But this is not the only way of looking at the broader picture. What if you do believe in the importance of role of social justice values, the New York Times, or America? What if you value governance innovation, but have more moderate views on politics? Then, there are two ways you could look at the issue:Network states as a synergistic strategy, or at least as a backup. Anything that happens in US politics in terms of improving equality, for example, only benefits the ~4% of the world's population that lives in the United States. The First Amendment does not apply outside US borders. The governance of many wealthy countries is sclerotic, and we do need some way to try more governance innovation. Network states could fill in the gaps. Countries like the United States could host network states that attract people from all over the world. Successful network states could even serve as a policy model for countries to adopt. Alternatively, what if the Republicans win and secure a decades-long majority in 2024, or the United States breaks down? You want there to be an alternative. Exit to network states as a distraction, or even a threat. If everyone's first instinct when faced with a large problem within their country is to exit to an enclave elsewhere, there will be no one left to protect and maintain the countries themselves. Global infrastructure that ultimately network states depend on will suffer. Both perspectives are compatible with a lot of disagreement with Balajian megapolitics. Hence, to argue for or against Balajian network states, we will ultimately have to talk about network states. My own view is friendly to network states, though with a lot of caveats and different ideas about how network states could work.What does cryptocurrency have to do with network states?There are two kinds of alignment here: there is the spiritual alignment, the idea that "Bitcoin becomes the flag of technology", and there is the practical alignment, the specific ways in which network states could use blockchains and cryptographic tokens. In general, I agree with both of these arguments - though I think Balaji's book could do much more to spell them out more explicitly.The spiritual alignmentCryptocurrency in 2022 is a key standard-bearer for internationalist liberal values that are difficult to find in any other social force that still stands strong today. Blockchains and cryptocurrencies are inherently global. Most Ethereum developers are outside the US, living in far-flung places like Europe, Taiwan and Australia. NFTs have given unique opportunities to artists in Africa and elsewhere in the Global South. Argentinians punch above their weight in projects like Proof of Humanity, Kleros and Nomic Labs.Blockchain communities continue to stand for openness, freedom, censorship resistance and credible neutrality, at a time where many geopolitical actors are increasingly only serving their own interests. This enhances their international appeal further: you don't have to love US hegemony to love blockchains and the values that they stand for. And this all makes blockchains an ideal spiritual companion for the network state vision that Balaji wants to see.The practical alignmentBut spiritual alignment means little without practical use value for blockchains to go along with it. Balaji gives plenty of blockchain use cases. One of Balaji's favorite concepts is the idea of the blockchain as a "ledger of record": people can timestamp events on-chain, creating a global provable log of humanity's "microhistory". He continues with other examples:Zero-knowledge technology like ZCash, Ironfish, and Tornado Cash allow on-chain attestation of exactly what people want to make public and nothing more. Naming systems like the Ethereum Name Service (ENS) and Solana Name Service (SNS) attach identity to on-chain transactions. Incorporation systems allow the on-chain representation of corporate abstractions above the level of a mere transaction, like financial statements or even full programmable company-equivalents like DAOs. Cryptocredentials, Non-Fungible Tokens (NFTs), Non-Transferable Fungibles (NTFs), and Soulbounds allow the representation of non-financial data on chain, like diplomas or endorsements. But how does this all relate to network states? I could go into specific examples in the vein of crypto cities: issuing tokens, issuing CityDAO-style citizen NFTs, combining blockchains with zero-knowledge cryptography to do secure privacy-preserving voting, and a lot more. Blockchains are the Lego of crypto-finance and crypto-governance: they are a very effective tool for implementing transparent in-protocol rules to govern common resources, assets and incentives.But we also need to go a level deeper. Blockchains and network states have the shared property that they are both trying to "create a new root". A corporation is not a root: if there is a dispute inside a corporation, it ultimately gets resolved by a national court system. Blockchains and network states, on the other hand, are trying to be new roots. This does not mean some absolute "na na no one can catch me" ideal of sovereignty that is perhaps only truly accessible to the ~5 countries that have highly self-sufficient national economies and/or nuclear weapons. Individual blockchain participants are of course vulnerable to national regulation, and enclaves of network states even more so. But blockchains are the only infrastructure system that at least attempts to do ultimate dispute resolution at the non-state level (either through on-chain smart contract logic or through the freedom to fork). This makes them an ideal base infrastructure for network states.What aspects of Balaji's vision do I like?Given that a purist "private property rights only" libertarianism inevitably runs into large problems like its inability to fund public goods, any successful pro-freedom program in the 21st century has to be a hybrid containing at least one Big Compromise Idea that solves at least 80% of the problems, so that independent individual initiative can take care of the rest. This could be some stringent measures against economic power and wealth concentration (maybe charge annual Harberger taxes on everything), it could be an 85% Georgist land tax, it could be a UBI, it could be mandating that sufficiently large companies become democratic internally, or one of any other proposals. Not all of these work, but you need something that drastic to have any shot at all.Generally, I am used to the Big Compromise Idea being a leftist one: some form of equality and democracy. Balaji, on the other hand, has Big Compromise Ideas that feel more rightist: local communities with shared values, loyalty, religion, physical environments structured to encourage personal discipline ("keto kosher") and hard work. These values are implemented in a very libertarian and tech-forward way, organizing not around land, history, ethnicity and country, but around the cloud and personal choice, but they are rightist values nonetheless. This style of thinking is foreign to me, but I find it fascinating, and important. Stereotypical "wealthy white liberals" ignore this at their peril: these more "traditional" values are actually quite popular even among some ethnic minorities in the United States, and even more so in places like Africa and India, which is exactly where Balaji is trying to build up his base.But what about this particular baizuo that's currently writing this review? Do network states actually interest me?The "Keto Kosher" health-focused lifestyle immersion network state is certainly one that I would want to live in. Sure, I could just spend time in cities with lots of healthy stuff that I can seek out intentionally, but a concentrated physical environment makes it so much easier. Even the motivational aspect of being around other people who share a similar goal sounds very appealing.But the truly interesting stuff is the governance innovation: using network states to organize in ways that would actually not be possible under existing regulations. There are three ways that you can interpret the underlying goal here:Creating new regulatory environments that let their residents have different priorities from the priorities preferred by the mainstream: for example, the "anyone can walk around naked" zone, or a zone that implements different tradeoffs between safety and convenience, or a zone that legalizes more psychoactive substances. Creating new regulatory institutions that might be more efficient at serving the same priorities as the status quo. For example, instead of improving environmental friendliness by regulating specific behaviors, you could just have a Pigovian tax. Instead of requiring licenses and regulatory pre-approval for many actions, you could require mandatory liability insurance. You could use quadratic voting for governance and quadratic funding to fund local public goods. Pushing against regulatory conservatism in general, by increasing the chance that there's some jurisdiction that will let you do any particular thing. Institutionalized bioethics, for example, is a notoriously conservative enterprise, where 20 people dead in a medical experiment gone wrong is a tragedy, but 200000 people dead from life-saving medicines and vaccines not being approved quickly enough is a statistic. Allowing people to opt into network states that accept higher levels of risk could be a successful strategy for pushing against this. In general, I see value in all three. A large-scale institutionalization of [1] could make the word simultaneously more free while making people comfortable with higher levels of restriction of certain things, because they know that if they want to do something disallowed there are other zones they could go to do it. More generally, I think there is an important idea hidden in [1]: while the "social technology" community has come up with many good ideas around better governance, and many good ideas around better public discussion, there is a missing emphasis on better social technology for sorting. We don't just want to take existing maps of social connections as given and find better ways to come to consensus within them. We also want to reform the webs of social connections themselves, and put people closer to other people that are more compatible with them to better allow different ways of life to maintain their own distinctiveness.[2] is exciting because it fixes a major problem in politics: unlike startups, where the early stage of the process looks somewhat like a mini version of the later stage, in politics the early stage is a public discourse game that often selects for very different things than what actually work in practice. If governance ideas are regularly implemented in network states, then we would move from an extrovert-privileging "talker liberalism" to a more balanced "doer liberalism" where ideas rise and fall based on how well they actually do on a small scale. We could even combine [1] and [2]: have a zone for people who want to automatically participate in a new governance experiment every year as a lifestyle.[3] is of course a more complicated moral question: whether you view paralysis and creep toward de-facto authoritarian global government as a bigger problem or someone inventing an evil technology that dooms us all as a bigger problem. I'm generally in the first camp; I am concerned about the prospect of both the West and China settling into a kind of low-growth conservatism, I love how imperfect coordination between nation states limits the enforceability of things like global copyright law, and I'm concerned about the possibility that, with future surveillance technology, the world as a whole will enter a highly self-enforcing but terrible political equilibrium that it cannot get out of. But there are specific areas (cough cough, unfriendly AI risk) where I am in the risk-averse camp ... but here we're already getting into the second part of my reaction.What aspects of Balaji's vision do I take issue with?There are four aspects that I am worried about the most:The "founder" thing - why do network states need a recognized founder to be so central? What if network states end up only serving the wealthy? "Exit" alone is not sufficient to stabilize global politics. So if exit is everyone's first choice, what happens? What about global negative externalities more generally? The "founder" thingThroughout the book, Balaji is insistent on the importance of "founders" in a network state (or rather, a startup society: you found a startup society, and become a network state if you are successful enough to get diplomatic recognition). Balaji explicitly describes startup society founders as being "moral entrepreneurs":These presentations are similar to startup pitch decks. But as the founder of a startup society, you aren't a technology entrepreneur telling investors why this new innovation is better, faster, and cheaper. You are a moral entrepreneur telling potential future citizens about a better way of life, about a single thing that the broader world has gotten wrong that your community is setting right.Founders crystallize moral intuitions and learnings from history into a concrete philosophy, and people whose moral intuitions are compatible with that philosophy coalesce around the project. This is all very reasonable at an early stage - though it is definitely not the only approach for how a startup society could emerge. But what happens at later stages? Mark Zuckerberg being the centralized founder of facebook the startup was perhaps necessary. But Mark Zuckerberg being in charge of a multibillion-dollar (in fact, multibillion-user) company is something quite different. Or, for that matter, what about Balaji's nemesis: the fifth-generation hereditary white Ochs-Sulzberger dynasty running the New York Times?Small things being centralized is great, extremely large things being centralized is terrifying. And given the reality of network effects, the freedom to exit again is not sufficient. In my view, the problem of how to settle into something other than founder control is important, and Balaji spends too little effort on it. "Recognized founder" is baked into the definition of what a Balajian network state is, but a roadmap toward wider participation in governance is not. It should be.What about everyone who is not wealthy?Over the last few years, we've seen many instances of governments around the world becoming explicitly more open to "tech talent". There are 42 countries offering digital nomad visas, there is a French tech visa, a similar program in Singapore, golden visas for Taiwan, a program for Dubai, and many others. This is all great for skilled professionals and rich people. Multimillionaires fleeing China's tech crackdowns and covid lockdowns (or, for that matter, moral disagreements with China's other policies) can often escape the world's systemic discrimination against Chinese and other low-income-country citizens by spending a few hundred thousand dollars on buying another passport. But what about regular people? What about the Rohingya minority facing extreme conditions in Myanmar, most of whom do not have a way to enter the US or Europe, much less buy another passport?Here, we see a potential tragedy of the network state concept. On the one hand, I can really see how exit can be the most viable strategy for global human rights protection in the twenty first century. What do you do if another country is oppressing an ethnic minority? You could do nothing. You could sanction them (often ineffective and ruinous to the very people you're trying to help). You could try to invade (same criticism but even worse). Exit is a more humane option. People suffering human rights atrocities could just pack up and leave for friendlier pastures, and coordinating to do it in a group would mean that they could leave without sacrificing the communities they depend on for friendship and economic livelihood. And if you're wrong and the government you're criticizing is actually not that oppressive, then people won't leave and all is fine, no starvation or bombs required. This is all beautiful and good. Except... the whole thing breaks down because when the people try to exit, nobody is there to take them.What is the answer? Honestly, I don't see one. One point in favor of network states is that they could be based in poor countries, and attract wealthy people from abroad who would then help the local economy. But this does nothing for people in poor countries who want to get out. Good old-fashioned political action within existing states to liberalize immigration laws seems like the only option.Nowhere to runIn the wake of Russia's invasion of Ukraine on Feb 24, Noah Smith wrote an important post on the moral clarity that the invasion should bring to our thought. A particularly striking section is titled "nowhere to run". Quoting:But while exit works on a local level — if San Francisco is too dysfunctional, you can probably move to Austin or another tech town — it simply won't work at the level of nations. In fact, it never really did — rich crypto guys who moved to countries like Singapore or territories like Puerto Rico still depended crucially on the infrastructure and institutions of highly functional states. But Russia is making it even clearer that this strategy is doomed, because eventually there is nowhere to run. Unlike in previous eras, the arm of the great powers is long enough to reach anywhere in the world.If the U.S. collapses, you can't just move to Singapore, because in a few years you'll be bowing to your new Chinese masters. If the U.S. collapses, you can't just move to Estonia, because in a few years (months?) you'll be bowing to your new Russian masters. And those masters will have extremely little incentive to allow you to remain a free individual with your personal fortune intact ... Thus it is very very important to every libertarian that the U.S. not collapse.One possible counter-argument is: sure, if Ukraine was full of people whose first instinct was exit, Ukraine would have collapsed. But if Russia was also more exit-oriented, everyone in Russia would have pulled out of the country within a week of the invasion. Putin would be left standing alone in the fields of the Luhansk oblast facing Zelensky a hundred meters away, and when Putin shouts his demand for surrender, Zelensky would reply: "you and what army"? (Zelensky would of course win a fair one-on-one fight)But things could go a different way. The risk is that exitocracy becomes recognized as the primary way you do the "freedom" thing, and societies that value freedom will become exitocratic, but centralized states will censor and suppress these impulses, adopt a militaristic attitude of national unconditional loyalty, and run roughshod over everyone else.So what about those negative externalities?If we have a hundred much-less-regulated innovation labs everywhere around the world, this could lead to a world where harmful things are more difficult to prevent. This raises a question: does believing in Balajism require believing in a world where negative externalities are not too big a deal? Such a viewpoint would be the opposite of the Vulnerable World Hypothesis (VWH), which suggests that are technology progresses, it gets easier and easier for one or a few crazy people to kill millions, and global authoritarian surveillance might be required to prevent extreme suffering or even extinction.One way out might be to focus on self-defense technology. Sure, in a network state world, we could not feasibly ban gain-of-function research, but we could use network states to help the world along a path to adopting really good HEPA air filtering, far-UVC light, early detection infrastructure and a very rapid vaccine development and deployment pipeline that could defeat not only covid, but far worse viruses too. This 80,000 hours episode outlines the bull case for bioweapons being a solvable problem. But this is not a universal solution for all technological risks: at the very least, there is no self-defense against a super-intelligent unfriendly AI that kills us all.Self-defense technology is good, and is probably an undervalued funding focus area. But it's not realistic to rely on that alone. Transnational cooperation to, for example, ban slaughterbots, would be required. And so we do want a world where, even if network states have more sovereignty than intentional communities today, their sovereignty is not absolute.Non-Balajian network statesReading The Network State reminded me of a different book that I read ten years ago: David de Ugarte's Phyles: Economic Democracy in the Twenty First Century. Phyles talks about similar ideas of transnational communities organized around values, but it has a much more left-leaning emphasis: it assumes that these communities will be democratic, inspired by a combination of 2000s-era online communities and nineteenth and twentieth-century ideas of cooperatives and workplace democracy.We can see the differences most clearly by looking at de Ugarte's theory of formation. Since I've already spent a lot of time quoting Balaji, I'll give de Ugarte a fair hearing with a longer quote:The very blogosphere is an ocean of identities and conversation in perpetual cross-breeding and change from among which the great social digestion periodically distils stable groups with their own contexts and specific knowledge.These conversational communities which crystallise, after a certain point in their development, play the main roles in what we call digital Zionism: they start to precipitate into reality, to generate mutual knowledge among their members, which makes them more identitarially important to them than the traditional imaginaries of the imagined communities to which they are supposed to belong (nation, class, congregation, etc.) as if it were a real community (group of friends, family, guild, etc.)Some of these conversational networks, identitarian and dense, start to generate their own economic metabolism, and with it a distinct demos – maybe several demoi – which takes the nurturing of the autonomy of the community itself as its own goal. These are what we call Neo-Venetianist networks. Born in the blogosphere, they are heirs to the hacker work ethic, and move in the conceptual world, which tends to the economic democracy which we spoke about in the first part of this book.Unlike traditional cooperativism, as they do not spring from real proximity-based communities, their local ties do not generate identity. In the Indianos' foundation, for instance, there are residents in two countries and three autonomous regions, who started out with two companies founded hundreds of kilometres away from each other.We see some very Balajian ideas: shared collective identities, but formed around values rather than geography, that start off as discussion communities in the cloud but then materialize into taking over large portions of economic life. De Ugarte even uses the exact same metaphor ("digital Zionism") that Balaji does!But we also see a key difference: there is no single founder. Rather than a startup society being formed by an act of a single individual combining together intuitions and strands of thought into a coherent formally documented philosophy, a phyle starts off as a conversational network in the blogosphere, and then directly turns into a group that does more and more over time - all while keeping its democratic and horizontal nature. The whole process is much more organic, and not at all guided by a single person's intention.Of course, the immediate challenge that I can see is the incentive issues inherent to such structures. One way to perhaps unfairly summarize both Phyles and The Network State is that The Network State seeks to use 2010s-era blockchains as a model for how to reorganize human society, and Phyles seeks to use 2000s-era open source software communities and blogs as a model for how to reorganize human society. Open source has the failure mode of not enough incentives, cryptocurrency has the failure mode of excessive and overly concentrated incentives. But what this does suggest is that some kind of middle way should be possible.Is there a middle way?My judgement so far is that network states are great, but they are far from being a viable Big Compromise Idea that can actually plug all the holes needed to build the kind of world I and most of my readers would want to see in the 21st century. Ultimately, I do think that we need to bring in more democracy and large-scale-coordination oriented Big Compromise Ideas of some kind to make network states truly successful.Here are some significant adjustments to Balajism that I would endorse:Founder to start is okay (though not the only way), but we really need a baked-in roadmap to exit-to-communityMany founders want to eventually retire or start something new (see: basically half of every crypto project), and we need to prevent network states from collapsing or sliding into mediocrity when that happens. Part of this process is some kind of constitutional exit-to-community guarantee: as the network state enters higher tiers of maturity and scale, more input from community members is taken into account automatically.Prospera attempted something like this. As Scott Alexander summarizes:Once Próspera has 100,000 residents (so realistically a long time from now, if the experiment is very successful), they can hold a referendum where 51% majority can change anything about the charter, including kicking HPI out entirely and becoming a direct democracy, or rejoining the rest of Honduras, or anythingBut I would favor something even more participatory than the residents having an all-or-nothing nuclear option to kick the government out.Another part of this process, and one that I've recognized in the process of Ethereum's growth, is explicitly encouraging broader participation in the moral and philosophical development of the community. Ethereum has its Vitalik, but it also has its Polynya: an internet anon who has recently entered the scene unsolicited and started providing high-quality thinking on rollups and scaling technology. How will your startup society recruit its first ten Polynyas?Network states should be run by something that's not coin-driven governanceCoin-driven governance is plutocratic and vulnerable to attacks; I have written about this many times, but it's worth repeating. Ideas like Optimism's soulbound and one-per-person citizen NFTs are key here. Balaji already acknowledges the need for non-fungibility (he supports coin lockups), but we should go further and more explicit in supporting governance that's not just shareholder-driven. This will also have the beneficial side effect that more democratic governance is more likely to be aligned with the outside world.Network states commit to making themselves friendly through outside representation in governanceOne of the fascinating and under-discussed ideas from the rationalist and friendly-AI community is functional decision theory. This is a complicated concept, but the powerful core idea is that AIs could coordinate better than humans, solving prisoner's dilemmas where humans often fail, by making verifiable public commitments about their source code. An AI could rewrite itself to have a module that prevents it from cheating other AIs that have a similar module. Such AIs would all cooperate with each other in prisoner's dilemmas.As I pointed out years ago, DAOs could potentially do the same thing. They could have governance mechanisms that are explicitly more charitable toward other DAOs that have a similar mechanism. Network states would be run by DAOs, and this would apply to network states too. They could even commit to governance mechanisms that promise to take wider public interests into account (eg. 20% of the votes could go to a randomly selected set of residents of the host city or country), without the burden of having to follow specific complicated regulations of how they should take those interests into account. A world where network states do such a thing, and where countries adopt policies that are explicitly more friendly to network states that do it, could be a better one.ConclusionI want to see startup societies along these kinds of visions exist. I want to see immersive lifestyle experiments around healthy living. I want to see crazy governance experiments where public goods are funded by quadratic funding, and all zoning laws are replaced by a system where every building's property tax floats between zero and five percent per year based on what percentage of nearby residents express approval or disapproval in a real-time blockchain and ZKP-based voting system. And I want to see more technological experiments that accept higher levels of risk, if the people taking those risks consent to it. And I think blockchain-based tokens, identity and reputation systems and DAOs could be a great fit.At the same time, I worry that the network state vision in its current form risks only satisfying these needs for those wealthy enough to move and desirable enough to attract, and many people lower down the socioeconomic ladder will be left in the dust. What can be said in network states' favor is their internationalism: we even have the Africa-focused Afropolitan. Inequalities between countries are responsible for two thirds of global inequality and inequalities within countries are only one third. But that still leaves a lot of people in all countries that this vision doesn't do much for. So we need something else too - for the global poor, for Ukrainians that want to keep their country and not just squeeze into Poland for a decade until Poland gets invaded too, and everyone else that's not in a position to move to a network state tomorrow or get accepted by one.Network states, with some modifications that push for more democratic governance and positive relationships with the communities that surround them, plus some other way to help everyone else? That is a vision that I can get behind.
-
The different types of ZK-EVMs The different types of ZK-EVMs2022 Aug 04 See all posts The different types of ZK-EVMs Special thanks to the PSE, Polygon Hermez, Zksync, Scroll, Matter Labs and Starkware teams for discussion and review.There have been many "ZK-EVM" projects making flashy announcements recently. Polygon open-sourced their ZK-EVM project, ZKSync released their plans for ZKSync 2.0, and the relative newcomer Scroll announced their ZK-EVM recently. There is also the ongoing effort from the Privacy and Scaling Explorations team, Nicolas Liochon et al's team, an alpha compiler from the EVM to Starkware's ZK-friendly language Cairo, and certainly at least a few others I have missed.The core goal of all of these projects is the same: to use ZK-SNARK technology to make cryptographic proofs of execution of Ethereum-like transactions, either to make it much easier to verify the Ethereum chain itself or to build ZK-rollups that are (close to) equivalent to what Ethereum provides but are much more scalable. But there are subtle differences between these projects, and what tradeoffs they are making between practicality and speed. This post will attempt to describe a taxonomy of different "types" of EVM equivalence, and what are the benefits and costs of trying to achieve each type.Overview (in chart form)Type 1 (fully Ethereum-equivalent)Type 1 ZK-EVMs strive to be fully and uncompromisingly Ethereum-equivalent. They do not change any part of the Ethereum system to make it easier to generate proofs. They do not replace hashes, state trees, transaction trees, precompiles or any other in-consensus logic, no matter how peripheral.Advantage: perfect compatibilityThe goal is to be able to verify Ethereum blocks as they are today - or at least, verify the execution-layer side (so, beacon chain consensus logic is not included, but all the transaction execution and smart contract and account logic is included).Type 1 ZK-EVMs are what we ultimately need make the Ethereum layer 1 itself more scalable. In the long term, modifications to Ethereum tested out in Type 2 or Type 3 ZK-EVMs might be introduced into Ethereum proper, but such a re-architecting comes with its own complexities.Type 1 ZK-EVMs are also ideal for rollups, because they allow rollups to re-use a lot of infrastructure. For example, Ethereum execution clients can be used as-is to generate and process rollup blocks (or at least, they can be once withdrawals are implemented and that functionality can be re-used to support ETH being deposited into the rollup), so tooling such as block explorers, block production, etc is very easy to re-use.Disadvantage: prover timeEthereum was not originally designed around ZK-friendliness, so there are many parts of the Ethereum protocol that take a large amount of computation to ZK-prove. Type 1 aims to replicate Ethereum exactly, and so it has no way of mitigating these inefficiencies. At present, proofs for Ethereum blocks take many hours to produce. This can be mitigated either by clever engineering to massively parallelize the prover or in the longer term by ZK-SNARK ASICs.Who's building it?The ZK-EVM Community Edition (bootstrapped by community contributors including Privacy and Scaling Explorations, the Scroll team, Taiko and others) is a Tier 1 ZK-EVM.Type 2 (fully EVM-equivalent)Type 2 ZK-EVMs strive to be exactly EVM-equivalent, but not quite Ethereum-equivalent. That is, they look exactly like Ethereum "from within", but they have some differences on the outside, particularly in data structures like the block structure and state tree.The goal is to be fully compatible with existing applications, but make some minor modifications to Ethereum to make development easier and to make proof generation faster.Advantage: perfect equivalence at the VM levelType 2 ZK-EVMs make changes to data structures that hold things like the Ethereum state. Fortunately, these are structures that the EVM itself cannot access directly, and so applications that work on Ethereum would almost always still work on a Type 2 ZK-EVM rollup. You would not be able to use Ethereum execution clients as-is, but you could use them with some modifications, and you would still be able to use EVM debugging tools and most other developer infrastructure.There are a small number of exceptions. One incompatibility arises for applications that verify Merkle proofs of historical Ethereum blocks to verify claims about historical transactions, receipts or state (eg. bridges sometimes do this). A ZK-EVM that replaces Keccak with a different hash function would break these proofs. However, I usually recommend against building applications this way anyway, because future Ethereum changes (eg. Verkle trees) will break such applications even on Ethereum itself. A better alternative would be for Ethereum itself to add future-proof history access precompiles.Disadvantage: improved but still slow prover timeType 2 ZK-EVMs provide faster prover times than Type 1 mainly by removing parts of the Ethereum stack that rely on needlessly complicated and ZK-unfriendly cryptography. Particularly, they might change Ethereum's Keccak and RLP-based Merkle Patricia tree and perhaps the block and receipt structures. Type 2 ZK-EVMs might instead use a different hash function, eg. Poseidon. Another natural modification is modifying the state tree to store the code hash and keccak, removing the need to verify hashes to process the EXTCODEHASH and EXTCODECOPY opcodes.These modifications significantly improve prover times, but they do not solve every problem. The slowness from having to prove the EVM as-is, with all of the inefficiencies and ZK-unfriendliness inherent to the EVM, still remains. One simple example of this is memory: because an MLOAD can read any 32 bytes, including "unaligned" chunks (where the start and end are not multiples of 32), an MLOAD can't simply be interpreted as reading one chunk; rather, it might require reading two consecutive chunks and performing bit operations to combine the result.Who's building it?Scroll's ZK-EVM project is building toward a Type 2 ZK-EVM, as is Polygon Hermez. That said, neither project is quite there yet; in particular, a lot of the more complicated precompiles have not yet been implemented. Hence, at the moment both projects are better considered Type 3.Type 2.5 (EVM-equivalent, except for gas costs)One way to significantly improve worst-case prover times is to greatly increase the gas costs of specific operations in the EVM that are very difficult to ZK-prove. This might involve precompiles, the KECCAK opcode, and possibly specific patterns of calling contracts or accessing memory or storage or reverting.Changing gas costs may reduce developer tooling compatibility and break a few applications, but it's generally considered less risky than "deeper" EVM changes. Developers should take care to not require more gas in a transaction than fits into a block, to never make calls with hard-coded amounts of gas (this has already been standard advice for developers for a long time).An alternative way to manage resource constraints is to simply set hard limits on the number of times each operation can be called. This is easier to implement in circuits, but plays much less nicely with EVM security assumptions. I would call this approach Type 3 rather than Type 2.5.Type 3 (almost EVM-equivalent)Type 3 ZK-EVMs are almost EVM-equivalent, but make a few sacrifices to exact equivalence to further improve prover times and make the EVM easier to develop.Advantage: easier to build, and faster prover timesType 3 ZK-EVMs might remove a few features that are exceptionally hard to implement in a ZK-EVM implementation. Precompiles are often at the top of the list here;. Additionally, Type 3 ZK-EVMs sometimes also have minor differences in how they treat contract code, memory or stack.Disadvantage: more incompatibilityThe goal of a Type 3 ZK-EVM is to be compatible with most applications, and require only minimal re-writing for the rest. That said, there will be some applications that would need to be rewritten either because they use pre-compiles that the Type 3 ZK-EVM removes or because of subtle dependencies on edge cases that the VMs treat differently.Who's building it?Scroll and Polygon are both Type 3 in their current forms, though they're expected to improve compatibility over time. Polygon has a unique design where they are ZK-verifying their own internal language called zkASM, and they interpret ZK-EVM code using the zkASM implementation. Despite this implementation detail, I would still call this a genuine Type 3 ZK-EVM; it can still verify EVM code, it just uses some different internal logic to do it.Today, no ZK-EVM team wants to be a Type 3; Type 3 is simply a transitional stage until the complicated work of adding precompiles is finished and the project can move to Type 2.5. In the future, however, Type 1 or Type 2 ZK-EVMs may become Type 3 ZK-EVMs voluntarily, by adding in new ZK-SNARK-friendly precompiles that provide functionality for developers with low prover times and gas costs.Type 4 (high-level-language equivalent)A Type 4 system works by taking smart contract source code written in a high-level language (eg. Solidity, Vyper, or some intermediate that both compile to) and compiling that to some language that is explicitly designed to be ZK-SNARK-friendly.Advantage: very fast prover timesThere is a lot of overhead that you can avoid by not ZK-proving all the different parts of each EVM execution step, and starting from the higher-level code directly.I'm only describing this advantage with one sentence in this post (compared to a big bullet point list below for compatibility-related disadvantages), but that should not be interpreted as a value judgement! Compiling from high-level languages directly really can greatly reduce costs and help decentralization by making it easier to be a prover.Disadvantage: more incompatibilityA "normal" application written in Vyper or Solidity can be compiled down and it would "just work", but there are some important ways in which very many applications are not "normal":Contracts may not have the same addresses in a Type 4 system as they do in the EVM, because CREATE2 contract addresses depend on the exact bytecode. This breaks applications that rely on not-yet-deployed "counterfactual contracts", ERC-4337 wallets, EIP-2470 singletons and many other applications. Handwritten EVM bytecode is more difficult to use. Many applications use handwritten EVM bytecode in some parts for efficiency. Type 4 systems may not support it, though there are ways to implement limited EVM bytecode support to satisfy these use cases without going through the effort of becoming a full-on Type 3 ZK-EVM. Lots of debugging infrastructure cannot be carried over, because such infrastructure runs over the EVM bytecode. That said, this disadvantage is mitigated by the greater access to debugging infrastructure from "traditional" high-level or intermediate languages (eg. LLVM). Developers should be mindful of these issues.Who's building it?ZKSync is a Type 4 system, though it may add compatibility for EVM bytecode over time. Nethermind's Warp project is building a compiler from Solidity to Starkware's Cairo, which will turn StarkNet into a de-facto Type 4 system.The future of ZK-EVM typesThe types are not unambiguously "better" or "worse" than other types. Rather, they are different points on the tradeoff space: lower-numbered types are more compatible with existing infrastructure but slower, and higher-numbered types are less compatible with existing infrastructure but faster. In general, it's healthy for the space that all of these types are being explored.Additionally, ZK-EVM projects can easily start at higher-numbered types and jump to lower-numbered types (or vice versa) over time. For example:A ZK-EVM could start as Type 3, deciding not to include some features that are especially hard to ZK-prove. Later, they can add those features over time, and move to Type 2. A ZK-EVM could start as Type 2, and later become a hybrid Type 2 / Type 1 ZK-EVM, by providing the possibility of operating either in full Ethereum compatibility mode or with a modified state tree that can be proven faster. Scroll is considering moving in this direction. What starts off as a Type 4 system could become Type 3 over time by adding the ability to process EVM code later on (though developers would still be encouraged to compile direct from high-level languages to reduce fees and prover times) A Type 2 or Type 3 ZK-EVM can become a Type 1 ZK-EVM if Ethereum itself adopts its modifications in an effort to become more ZK-friendly. A Type 1 or Type 2 ZK-EVM can become a Type 3 ZK-EVM by adding a precompile for verifying code in a very ZK-SNARK-friendly language. This would give developers a choice between Ethereum compatibility and speed. This would be Type 3, because it breaks perfect EVM equivalence, but for practical intents and purposes it would have a lot of the benefits of Type 1 and 2. The main downside might be that some developer tooling would not understand the ZK-EVM's custom precompiles, though this could be fixed: developer tools could add universal precompile support by supporting a config format that includes an EVM code equivalent implementation of the precompile. Personally, my hope is that everything becomes Type 1 over time, through a combination of improvements in ZK-EVMs and improvements to Ethereum itself to make it more ZK-SNARK-friendly. In such a future, we would have multiple ZK-EVM implementations which could be used both for ZK rollups and to verify the Ethereum chain itself. Theoretically, there is no need for Ethereum to standardize on a single ZK-EVM implementation for L1 use; different clients could use different proofs, so we continue to benefit from code redundancy.However, it is going to take quite some time until we get to such a future. In the meantime, we are going to see a lot of innovation in the different paths to scaling Ethereum and Ethereum-based ZK-rollups.
-
Where to use a blockchain in non-financial applications? Where to use a blockchain in non-financial applications?2022 Jun 12 See all posts Where to use a blockchain in non-financial applications? Special thanks to Shrey Jain and Puja Ohlhaver for substantial feedback and reviewRecently, there has been a growing amount of interest in using blockchains for not-just-financial applications. This is a trend that I have been strongly in favor of, for various reasons. In the last month, Puja Ohlhaver, Glen Weyl and I collaborated on a paper describing a more detailed vision for what could be done with a richer ecosystem of soulbound tokens making claims describing various kinds of relationships. This has led to some discussion, particularly focused on whether or not it makes any sense to use a blockchain in a decentralized identity ecosystem:Kate Sills argues for off-chain signed claims Puja Ohlhaver responds to Kate Sills Evin McMullen and myself have a podcast debating on-chain vs off-chain attestations Kevin Yu writes a technical overview bringing up the on-chain versus off-chain question Molly White argues a pessimistic case against self-sovereign identity Shrey Jain makes a meta-thread containing the above and many other Twitter discussions It's worth zooming out and asking a broader question: where does it make sense, in general, to use a blockchain in non-financial applications? Should we move toward a world where even decentralized chat apps work by every message being an on-chain transaction containing the encrypted message? Or, alternatively, are blockchains only good for finance (say, because network effects mean that money has a unique need for a "global view"), with all other applications better done using centralized or more local systems?My own view tends to be, like with blockchain voting, far from the "blockchain everywhere" viewpoint, but also far from a "blockchain minimalist". I see the value of blockchains in many situations, sometimes for really important goals like trust and censorship resistance but sometimes purely for convenience. This post will attempt to describe some types of situations where blockchains might be useful, especially in the context of identity, and where they are not. This post is not a complete list and intentionally leaves many things out. The goal is rather to elucidate some common categories.User account key changes and recoveryOne of the biggest challenges in a cryptographic account system is the issue of key changes. This can happen in a few cases:You're worried that your current key might get lost or stolen, and you want to switch to a different key You want to switch to a different cryptographic algorithm (eg. because you're worried quantum computers will come soon and you want to upgrade to post-quantum) Your key got lost, and you want to regain access to your account Your key got stolen, and you want to regain exclusive access to your account (and you don't want the thief to be able to do the same) [1] and [2] are relatively simple in that they can be done in a fully self-sovereign way: you control key X, you want to switch to key Y, so you publish a message signed with X saying "Authenticate me with Y from now on", and everyone accepts that.But notice that even for these simpler key change scenarios, you can't just use cryptography. Consider the following sequence of events:You are worried that key A might get stolen, so you sign a message with A saying "I use B now" A year later, a hacker actually does steal key A. They sign a message saying with A saying "I use C now", where C is their own key From the point of view of someone coming in later who just receives these two messages, they see that A is no longer used, but they don't know whether "replace A with B" or "replace A with C" has higher priority. This is equivalent to the famous double-spend problem in designing decentralized currencies, except instead of the goal being to prevent a previous owner of a coin from being able to send it again, here the goal is to prevent the previous key controlling an account from being able to change the key. Just like creating a decentralized currency, doing account management in a decentralized way requires something like a blockchain. A blockchain can timestamp the key change messages, providing common knowledge over whether B or C came first.[3] and [4] are harder. In general, my own preferred solution is multisig and social recovery wallets, where a group of friends, family members and other contacts can transfer control of your account to a new key if it gets lost or stolen. For critical operations (eg. transferring large quantities of funds, or signing an important contract), participation of this group can also be required.But this too requires a blockchain. Social recovery using secret sharing is possible, but it is more difficult in practice: if you no longer trust some of your contacts, or if they want to change their own keys, you have no way to revoke access without changing your key yourself. And so we're back to requiring some form of on-chain record.One subtle but important idea in the DeSoc paper is that to preserve non-transferability, social recovery (or "community recovery") of profiles might actually need to be mandatory. That is, even if you sell your account, you can always use community recovery to get the account back. This would solve problems like not-actually-reputable drivers buying verified accounts on ride sharing platforms. That said, this is a speculative idea and does not have to be fully implemented to get the other benefits of blockchain-based identity and reputation systems.Note that so far this is a limited use-case of blockchains: it's totally okay to have accounts on-chain but do everything else off-chain. There's a place for these kinds of hybrid visions; Sign-in With Ethereum is good simple example of how this could be done in practice.Modifying and revoking attestationsAlice goes to Example College and gets a degree in example studies. She gets a digital record certifying this, signed with Example College's keys. Unfortunately, six months later, Example College discovers that Alice had committed a large amount of plagiarism, and revokes her degree. But Alice continues to use her old digital record to go around claiming to various people and institutions that she has a degree. Potentially, the attestation could even carry permissions - for example, the right to log in to the college's online forum - and Alice might try to inappropriately access that too. How do we prevent this?The "blockchain maximalist" approach would be to make the degree an on-chain NFT, so Example College can then issue an on-chain transaction to revoke the NFT. But perhaps this is needlessly expensive: issuance is common, revocation is rare, and we don't want to require Example College to issue transactions and pay fees for every issuance if they don't have to. So instead we can go with a hybrid solution: make initial degree an off-chain signed message, and do revocations on-chain. This is the approach that OpenCerts uses.The fully off-chain solution, and the one advocated by many off-chain verifiable credentials proponents, is that Example College runs a server where they publish a full list of their revocations (to improve privacy, each attestation can come with an attached nonce and the revocation list can just be a list of nonces).For a college, running a server is not a large burden. But for any smaller organization or individual, managing "yet another server script" and making sure it stays online is a significant burden for IT people. If we tell people to "just use a server" out of blockchain-phobia, then the likely outcome is that everyone outsources the task to a centralized provider. Better to keep the system decentralized and just use a blockchain - especially now that rollups, sharding and other techniques are finally starting to come online to make the cost of a blockchain cheaper and cheaper.Negative reputationAnother important area where off-chain signatures do not suffice is negative reputation - that is, attestations where the person or organization that you're making attestations about might not want you to see them. I'm using "negative reputation" here as a technical term: the most obvious motivating use case is attestations saying bad things about someone, like a bad review or a report that someone acted abusively in some context, but there are also use cases where "negative" attestations don't imply bad behavior - for example, taking out a loan and wanting to prove that you have not taken out too many other loans at the same time.With off-chain claims, you can do positive reputation, because it's in the interest of the recipient of a claim to show it to appear more reputable (or make a ZK-proof about it), but you can't do negative reputation, because someone can always choose to only show the claims that make them look good and leave out all the others.Here, making attestations on-chain actually does fix things. To protect privacy, we can add encryption and zero knowledge proofs: an attestation can just be an on-chain record with data encrypted to the recipient's public key, and users could prove lack of negative reputation by running a zero knowledge proof that walks over the entire history of records on chain. The proofs being on-chain and the verification process being blockchain-aware makes it easy to verify that the proof actually did walk over the whole history and did not skip any records. To make this computationally feasible, a user could use incrementally verifiable computation (eg. Halo) to maintain and prove a tree of records that were encrypted to them, and then reveal parts of the tree when needed.Negative reputation and revoking attestations are in some sense equivalent problems: you can revoke an attestation by adding another negative-reputation attestation saying "this other attestation doesn't count anymore", and you can implement negative reputation with revocation by piggybacking on positive reputation: Alice's degree at Example College could be revoked and replaced with a degree saying "Alice got a degree in example studies, but she took out a loan".Is negative reputation a good idea?One critique of negative reputation that we sometimes hear is: but isn't negative reputation a dystopian scheme of "scarlet letters", and shouldn't we try our best to do things with positive reputation instead?Here, while I support the goal of avoiding unlimited negative reputation, I disagree with the idea of avoiding it entirely. Negative reputation is important for many use cases. Uncollateralized lending, which is highly valuable for improving capital efficiency within the blockchain space and outside, clearly benefits from it. Unirep Social shows a proof-of-concept social media platform that combines a high level of anonymity with a privacy-preserving negative reputation system to limit abuse.Sometimes, negative reputation can be empowering and positive reputation can be exclusionary. An online forum where every unique human gets the right to post until they get too many "strikes" for misbehavior is more egalitarian than a forum that requires some kind of "proof of good character" to be admitted and allowed to speak in the first place. Marginalized people whose lives are mostly "outside the system", even if they actually are of good character, would have a hard time getting such proofs.Readers of the strong civil-libertarian persuasion may also want to consider the case of an anonymous reputation system for clients of sex workers: you want to protect privacy, but you also might want a system where if a client mistreats a sex worker, they get a "black mark" that encourages other workers to be more careful or stay away. In this way, negative reputation that's hard to hide can actually empower the vulnerable and protect safety. The point here is not to defend some specific scheme for negative reputation; rather, it's to show that there's very real value that negative reputation unlocks, and a successful system needs to support it somehow.Negative reputation does not have to be unlimited negative reputation: I would argue that it should always be possible to create a new profile at some cost (perhaps sacrificing a lot or all of your existing positive reputation). There is a balance between too little accountability and too much accountability. But having some technology that makes negative reputation possible in the first place is a prerequisite for unlocking this design space.Committing to scarcityAnother example of where blockchains are valuable is issuing attestations that have a provably limited quantity. If I want to make an endorsement for someone (eg. one might imagine a company looking for jobs or a government visa program looking at such endorsements), the third party looking at the endorsement would want to know whether I'm careful with endorsements or if I give them off to pretty much whoever is friends with me and asks nicely.The ideal solution to this problem would be to make endorsements public, so that endorsements become incentive-aligned: if I endorse someone who turns out to do something wrong, everyone can discount my endorsements in the future. But often, we also want to preserve privacy. So instead what I could do is publish hashes of each endorsement on-chain, so that anyone can see how many I have given out.An even more effective usecase is many-at-a-time issuance: if an artists wants to issue N copies of a "limited-edition" NFT, they could publish on-chain a single hash containing the Merkle root of the NFTs that they are issuing. The single issuance prevents them from issuing more after the fact, and you can publish the number (eg. 100) signifying the quantity limit along with the Merkle root, signifying that only the leftmost 100 Merkle branches are valid. By publishing a single Merkle root and max count on-chain, you can commit issue a limited quantity of attestations. In this example, there are only five possible valid Merkle branches that could satisfy the proof check. Astute readers may notice a conceptual similarity to Plasma chains. Common knowledgeOne of the powerful properties of blockchains is that they create common knowledge: if I publish something on-chain, then Alice can see it, Alice can see that Bob can see it, Charlie can see that Alice can see that Bob can see it, and so on.Common knowledge is often important for coordination. For example, a group of people might want to speak out about an issue, but only feel comfortable doing so if there's enough of them speaking out at the same time that they have safety in numbers. One possible way to do this is for one person to start a "commitment pool" around a particular statement, and invite others to publish hashes (which are private at first) denoting their agreement. Only if enough people participate within some period of time, all participants would be required to have their next on-chain message publicly reveal their position.A design like this could be accomplished with a combination of zero knowledge proofs and blockchains (it could be done without blockchains, but that requires either witness encryption, which is not yet available, or trusted hardware, which has deeply problematic security assumptions). There is a large design space around these kinds of ideas that is very underexplored today, but could easily start to grow once the ecosystem around blockchains and cryptographic tools grows further.Interoperability with other blockchain applicationsThis is an easy one: some things should be on-chain to better interoperate with other on-chain applications. Proof of humanity being an on-chain NFT makes it easier for projects to automatically airdrop or give governance rights to accounts that have proof of humanity profiles. Oracle data being on-chain makes it easier for defi projects to read. In all of these cases, the blockchain does not remove the need for trust, though it can house structures like DAOs that manage the trust. But the main value that being on-chain provides is simply being in the same place as the stuff that you're interacting with, which needs a blockchain for other reasons.Sure, you could run an oracle off-chain and require the data to be imported only when it needs to be read, but in many cases that would actually be more expensive, and needlessly impose complexity and costs on developers.Open-source metricsOne key goal of the Decentralized Society paper is the idea that it should be possible to make calculations over the graph of attestations. A really important one is measuring decentralization and diversity. For example, many people seem to agree that an ideal voting mechanism would somehow keep diversity in mind, giving greater weight to projects that are supported not just by the largest number of coins or even humans, but by the largest number of truly distinct perspectives. Quadratic funding as implemented in Gitcoin Grants also includes some explicitly diversity-favoring logic to mitigate attacks.Another natural place where measurements and scores are going to be valuable is reputation systems. This already exists in a centralized form with ratings, but it can be done in a much more decentralized way where the algorithm is transparent while at the same time preserving more user privacy.Aside from tightly-coupled use cases like this, where attempts to measure to what extent some set of people is connected and feed that directly into a mechanism, there's also broader use case of helping a community understand itself. In the case of measuring decentralization, this might be a matter of identifying areas where concentration is getting too high, which might require a response. In all of these cases, running computerized algorithms over large bodies of attestations and commitments and doing actually important things with the outputs is going to be unavoidable.We should not try to abolish quantified metrics, we should try to make better onesKate Sills expressed her skepticism of the goal of making calculations over reputation, an argument that applies both for public analytics and for individuals ZK-proving over their reputation (as in Unirep Social):The process of evaluating a claim is very subjective and context-dependent. People will naturally disagree about the trustworthiness of other people, and trust depends on the context ... [because of this] we should be extremely skeptical of any proposal to "calculate over" claims to get objective results.I this case, I agree with the importance of subjectivity and context, but I would disagree with the more expansive claim that avoiding calculations around reputation entirely is the right goal to be aiming towards. Pure individualized analysis does not scale far beyond Dunbar's number, and any complex society that is attempting to support large-scale cooperation has to rely on aggregations and simplifications to some extent.That said, I would argue that an open-participation ecosystem of attestations (as opposed to the centralized one we have today) can get us the best of both worlds by opening up space for better metrics. Here are some principles that such designs could follow:Inter-subjectivity: eg. a reputation should not be a single global score; instead, it should be a more subjective calculation involving the person or entity being evaluated but also the viewer checking the score, and potentially even other aspects of the local context. Credible neutrality: the scheme should clearly not leave room for powerful elites to constantly manipulate it in their own favor. Some possible ways to achieve this are maximum transparency and infrequent change of the algorithm. Openness: the ability to make meaningful inputs, and to audit other people's outputs by running the check yourself, should be open to anyone, and not just restricted to a small number of powerful groups. If we don't create good large-scale aggregates of social data, then we risk ceding market share to opaque and centralized social credit scores instead.Not all data should be on-chain, but making some data public in a common-knowledge way can help increase a community's legibility to itself without creating data-access disparities that could be abused to centralize control.As a data storeThis is the really controversial use case, even among those who accept most of the others. There is a common viewpoint in the blockchain space that blockchains should only be used in those cases where they are truly needed and unavoidable, and everywhere else we should use other tools.This attitude makes sense in a world where transaction fees are very expensive, and blockchains are uniquely incredibly inefficient. But it makes less sense in a world where blockchains have rollups and sharding and transaction fees have dropped down to a few cents, and the difference in redundancy between a blockchain and non-blockchain decentralized storage might only be 100x.Even in such a world, it would not make sense to store all data on-chain. But small text records? Absolutely. Why? Because blockchains are just a really convenient place to store stuff. I maintain a copy of this blog on IPFS. But uploading to IPFS often takes an hour, it requires centralized gateways for users to access it with anything close to website levels of latency, and occasionally files drop off and no longer become visible. Dumping the entire blog on-chain, on the other hand, would solve that problem completely. Of course, the blog is too big to actually be dumped on-chain, even post-sharding, but the same principle applies to smaller records.Some examples of small cases where putting data on-chain just to store it may be the right decision include:Augmented secret sharing: splitting your password into N pieces where any M = N-R of the pieces can recover the password, but in a way where you can choose the contents of all N of the pieces. For example, the pieces could all be hashes of passwords, secrets generated through some other tool, or answers to security questions. This is done by publishing an extra R pieces (which are random-looking) on-chain, and doing N-of-(N+R) secret sharing on the whole set. ENS optimization. ENS could be made more efficient by combining all records into a single hash, only publishing the hash on-chain, and requiring anyone accessing the data to get the full data off of IPFS. But this would significantly increase complexity, and add yet another software dependency. And so ENS keeps data on-chain even if it is longer than 32 bytes. Social metadata - data connected to your account (eg. for sign-in-with-Ethereum purposes) that you want to be public and that is very short in length. This is generally not true for larger data like profile pictures (though if the picture happens to be a small SVG file it could be!), but it is true for text records. Attestations and access permissions. Especially if the data being stored is less than a few hundred bytes long, it might be more convenient to store the data on-chain than put the hash on-chain and the data off-chain. In a lot of these cases, the tradeoff isn't just cost but also privacy in those edge cases where keys or cryptography break. Sometimes, privacy is only somewhat important, and the occasional loss of privacy from leaked keys or the faraway specter of quantum computing revealing everything in 30 years is less important than having a very high degree of certainty that the data will remain accessible. After all, off-chain data stored in your "data wallet" can get hacked too.But sometimes, data is particularly sensitive, and that can be another argument against putting it on-chain, and keeping it stored locally as a second layer of defense. But note that in those cases, that privacy need is an argument not just against blockchains, but against all decentralized storage.ConclusionsOut of the above list, the two I am personally by far the most confident about are interoperability with other blockchain applications and account management. The first is on-chain already, and the second is relatively cheap (need to use the chain once per user, and not once per action), the case for it is clear, and there really isn't a good non-blockchain-based solution.Negative reputation and revocations are also important, though they are still relatively early-stage use cases. A lot can be done with reputation by relying on off-chain positive reputation only, but I expect that the case for revocation and negative reputation will become more clear over time. I expect there to be attempts to do it with centralized servers, but over time it should become clear that blockchains are the only way to avoid a hard choice between inconvenience and centralization.Blockchains as data stores for short text records may be marginal or may be significant, but I do expect at least some of that kind of usage to keep happening. Blockchains really are just incredibly convenient for cheap and reliable data retrieval, where data continues to be retrievable whether the application has two users or two million. Open-source metrics are still a very early-stage idea, and it remains to see just how much can be done and made open without it becoming exploitable (as eg. online reviews, social media karma and the like get exploited all the time). And common knowledge games require convincing people to accept entirely new workflows for socially important things, so of course that is an early-stage idea too.I have a large degree of uncertainty in exactly what level of non-financial blockchain usage in each of these categories makes sense, but it seems clear that blockchains as an enabling tool in these areas should not be dismissed.
-
Some ways to use ZK-SNARKs for privacy Some ways to use ZK-SNARKs for privacy2022 Jun 15 See all posts Some ways to use ZK-SNARKs for privacy Special thanks to Barry Whitehat and Gubsheep for feedback and review.ZK-SNARKs are a powerful cryptographic tool, and an increasingly important part of the applications that people are building both in the blockchain space and beyond. But they are complicated, both in terms of how they work, and in terms of how you can use them.My previous post explaining ZK-SNARKs focused on the first question, attempting to explain the math behind ZK-SNARKs in a way that's reasonably understandable but still theoretically complete. This post will focus on the second question: how do ZK-SNARKs fit into existing applications, what are some examples of what they can do, what can't they do, and what are some general guidelines for figuring out whether or not ZK-SNARKing some particular application is possible?In particular, this post focuses on applications of ZK-SNARKs for preserving privacy.What does a ZK-SNARK do?Suppose that you have a public input \(x\), a private input \(w\), and a (public) function \(f(x, w) \rightarrow \\) that performs some kind of verification on the inputs. With a ZK-SNARK, you can prove that you know an \(w\) such that \(f(x, w) = True\) for some given \(f\) and \(x\), without revealing what \(w\) is. Additionally, the verifier can verify the proof much faster than it would take for them to compute \(f(x, w)\) themselves, even if they know \(w\). This gives the ZK-SNARK its two properties: privacy and scalability. As mentioned above, in this post our examples will focus on privacy.Proof of membershipSuppose that you have an Ethereum wallet, and you want to prove that this wallet has a proof-of-humanity registration, without revealing which registered human you are. We can mathematically describe the function as follows:The private input (\(w\)): your address \(A\), and the private key \(k\) to your address The public input (\(x\)): the set of all addresses with verified proof-of-humanity profiles \(\\) The verification function \(f(x, w)\): Interpret \(w\) as the pair \((A, k)\), and \(x\) as the list of valid profiles \(\\) Verify that \(A\) is one of the addresses in \(\\) Verify that \(privtoaddr(k) = A\) Return \(True\) if both verifications pass, \(False\) if either verification fails The prover generates their address \(A\) and the associated key \(k\), and provides \(w = (A, k)\) as the private input to \(f\). They take the public input, the current set of verified proof-of-humanity profiles \(\\), from the chain. They run the ZK-SNARK proving algorithm, which (assuming the inputs are correct) generates the proof. The prover sends the proof to the verifier and they provide the block height at which they obtained the list of verified profiles.The verifier also reads the chain, gets the list \(\\) at the height that the prover specified, and checks the proof. If the check passes, the verifier is convinced that the prover has some verified proof-of-humanity profile.Before we move on to more complicated examples, I highly recommend you go over the above example until you understand every bit of what is going on.Making the proof-of-membership more efficientOne weakness in the above proof system is that the verifier needs to know the whole set of profiles \(\\), and they need to spend \(O(n)\) time "inputting" this set into the ZK-SNARK mechanism.We can solve this by instead passing in as a public input an on-chain Merkle root containing all profiles (this could just be the state root). We add another private input, a Merkle proof \(M\) proving that the prover's account \(A\) is in the relevant part of the tree. Advanced readers: A very new and more efficient alternative to Merkle proofs for ZK-proving membership is Caulk. In the future, some of these use cases may migrate to Caulk-like schemes.ZK-SNARKs for coinsProjects like Zcash and Tornado.cash allow you to have privacy-preserving currency. Now, you might think that you can take the "ZK proof-of-humanity" above, but instead of proving access of a proof-of-humanity profile, use it to prove access to a coin. But we have a problem: we have to simultaneously solve privacy and the double spending problem. That is, it should not be possible to spend the coin twice.Here's how we solve this. Anyone who has a coin has a private secret \(s\). They locally compute the "leaf" \(L = hash(s, 1)\), which gets published on-chain and becomes part of the state, and \(N = hash(s, 2)\), which we call the nullifier. The state gets stored in a Merkle tree. To spend a coin, the sender must make a ZK-SNARK where:The public input contains a nullifier \(N\), the current or recent Merkle root \(R\), and a new leaf \(L'\) (the intent is that recipient has a secret \(s'\), and passes to the sender \(L' = hash(s', 1)\)) The private input contains a secret \(s\), a leaf \(L\) and a Merkle branch \(M\) The verification function checks that: \(M\) is a valid Merkle branch proving that \(L\) is a leaf in a tree with root \(R\), where \(R\) is the current Merkle root of the state \(hash(s, 1) = L\) \(hash(s, 2) = N\) The transaction contains the nullifier \(N\) and the new leaf \(L'\). We don't actually prove anything about \(L'\), but we "mix it in" to the proof to prevent \(L'\) from being modified by third parties when the transaction is in-flight.To verify the transaction, the chain checks the ZK-SNARK, and additionally checks that \(N\) has not been used in a previous spending transaction. If the transaction succeeds, \(N\) is added to the spent nullifier set, so that it cannot be spent again. \(L'\) is added to the Merkle tree.What is going on here? We are using a zk-SNARK to relate two values, \(L\) (which goes on-chain when a coin is created) and \(N\) (which goes on-chain when a coin is spent), without revealing which \(L\) is connected to which \(N\). The connection between \(L\) and \(N\) can only be discovered if you know the secret \(s\) that generates both. Each coin that gets created can only be spent once (because for each \(L\) there is only one valid corresponding \(N\)), but which coin is being spent at a particular time is kept hidden.This is also an important primitive to understand. Many of the mechanisms we describe below will be based on a very similar "privately spend only once" gadget, though for different purposes.Coins with arbitrary balancesThe above can easily be extended to coins of arbitrary balances. We keep the concept of "coins", except each coin has a (private) balance attached. One simple way to do this is have the chain store for each coin not just the leaf \(L\) but also an encrypted balance.Each transaction would consume two coins and create two new coins, and it would add two (leaf, encrypted balance) pairs to the state. The ZK-SNARK would also check that the sum of the balances coming in equals the sum of the balances going out, and that the two output balances are both non-negative.ZK anti-denial-of-serviceAn interesting anti-denial-of-service gadget. Suppose that you have some on-chain identity that is non-trivial to create: it could be a proof-of-humanity profile, it could be a validator with 32 ETH, or it could just be an account that has a nonzero ETH balance. We could create a more DoS resistant peer-to-peer network by only accepting a message if it comes with a proof that the message's sender has such a profile. Every profile would be allowed to send up to 1000 messages per hour, and a sender's profile would be removed from the list if the sender cheats. But how do we make this privacy-preserving?First, the setup. Let \(k\) be the private key of a user; \(A = privtoaddr(k)\) is the corresponding address. The list of valid addresses is public (eg. it's a registry on-chain). So far this is similar to the proof-of-humanity example: you have to prove that you have the private key to one address without revealing which one. But here, we don't just want a proof that you're in the list. We want a protocol that lets you prove you're in the list but prevents you from making too many proofs. And so we need to do some more work.We'll divide up time into epochs; each epoch lasts 3.6 seconds (so, 1000 epochs per hour). Our goal will be to allow each user to send only one message per epoch; if the user sends two messages in the same epoch, they will get caught. To allow users to send occasional bursts of messages, they are allowed to use epochs in the recent past, so if some user has 500 unused epochs they can use those epochs to send 500 messages all at once.The protocolWe'll start with a simple version: we use nullifiers. A user generates a nullifier with \(N = hash(k, e)\), where \(k\) is their key and \(e\) is the epoch number, and publishes it along with the message \(m\). The ZK-SNARK once again mixes in \(hash(m)\) without verifying anything about \(m\), so that the proof is bound to a single message. If a user makes two proofs bound to two different messages with the same nullifier, they can get caught.Now, we'll move on to the more complex version. Instead of just making it easy to prove if someone used the same epoch twice, this next protocol will actually reveal their private key in that case. Our core technique will rely on the "two points make a line" trick: if you reveal one point on a line, you've revealed little, but if you reveal two points on a line, you've revealed the whole line.For each epoch \(e\), we take the line \(L_e(x) = hash(k, e) * x + k\). The slope of the line is \(hash(k, e)\), and the y-intercept is \(k\); neither is known to the public. To make a certificate for a message \(m\), the sender provides \(y = L_e(hash(m)) =\) \(hash(k, e) * hash(m) + k\), along with a ZK-SNARK proving that \(y\) was computed correctly. To recap, the ZK-SNARK here is as follows:Public input: \(\\), the list of valid accounts \(m\), the message that the certificate is verifying \(e\), the epoch number used for the certificate \(y\), the line function evaluation Private input: \(k\), your private key Verification function: Check that \(privtoaddr(k)\) is in \(\\) Check that \(y = hash(k, e) * hash(m) + k\) But what if someone uses a single epoch twice? That means they published two values \(m_1\) and \(m_2\) and the corresponding certificate values \(y_1 = hash(k, e) * hash(m_1) + k\) and \(y_2 = hash(k, e) * hash(m_2) + k\). We can use the two points to recover the line, and hence the y-intercept (which is the private key): \(k = y_1 - hash(m_1) * \frac\) So if someone reuses an epoch, they leak out their private key for everyone to see. Depending on the circumstance, this could imply stolen funds, a slashed validator, or simply the private key getting broadcasted and included into a smart contract, at which point the corresponding address would get removed from the set.What have we accomplished here? A viable off-chain, anonymous anti-denial-of-service system useful for systems like blockchain peer-to-peer networks, chat applications, etc, without requiring any proof of work. The RLN (rate limiting nullifier) project is currently building essentially this idea, though with minor modifications (namely, they do both the nullifier and the two-points-on-a-line technique, using the nullifier to make it easier to catch double-use of an epoch).ZK negative reputationSuppose that we want to build 0chan, an internet forum which provides full anonymity like 4chan (so you don't even have persistent names), but has a reputation system to encourage more quality content. This could be a system where some moderation DAO can flag posts as violating the rules of the system and institutes a three-strikes-and-you're-out mechanism, it could be users being able to upvote and downvote posts; there are lots of configurations.The reputation system could support positive or negative reputation; however, supporting negative reputation requires extra infrastructure to require the user to take into account all reputation messages in their proof, even the negative ones. It's this harder use case, which is similar to what is being implemented with Unirep Social, that we'll focus on.Chaining posts: the basicsAnyone can make a post by publishing a message on-chain that contains the post, and a ZK-SNARK proving that either (i) you own some scarce external identity, eg. proof-of-humanity, that entitles you to create an account, or (ii) that you made some specific previous post. Specifically, the ZK-SNARK is as follows:Public inputs: The nullifier \(N\) A recent blockchain state root \(R\) The post contents ("mixed in" to the proof to bind it to the post, but we don't do any computation on it) Private inputs: Your private key \(k\) Either an external identity (with address \(A\)), or the nullifier \(N_\) used by the previous post A Merkle proof \(M\) proving inclusion of \(A\) or \(N_\) on-chain The number \(i\) of posts that you have previously made with this account Verification function: Check that \(M\) is a valid Merkle branch proving that (either \(A\) or \(N_\), whichever is provided) is a leaf in a tree with root \(R\) Check that \(N = enc(i, k)\), where \(enc\) is an encryption function (eg. AES) If \(i = 0\), check that \(A = privtoaddr(k)\), otherwise check that \(N_ = enc(i-1, k)\) In addition to verifying the proof, the chain also checks that (i) \(R\) actually is a recent state root, and (ii) the nullifier \(N\) has not yet been used. So far, this is like the privacy-preserving coin introduced earlier, but we add a procedure for "minting" a new account, and we remove the ability to "send" your account to a different key - instead, all nullifiers are generated using your original key.We use \(enc\) instead of \(hash\) here to make the nullifiers reversible: if you have \(k\), you can decrypt any specific nullifier you see on-chain and if the result is a valid index and not random junk (eg. we could just check \(dec(N) < 2^\)), then you know that nullifier was generated using \(k\).Adding reputationReputation in this scheme is on-chain and in the clear: some smart contract has a method addReputation, which takes as input (i) the nullifier published along with the post, and (ii) the number of reputation units to add and subtract.We extend the on-chain data stored per post: instead of just storing the nullifier \(N\), we store \(\, \bar\}\), where:\(\bar = hash(h, r)\) where \(h\) is the block height of the state root that was referenced in the proof \(\bar = hash(u, r)\) where \(u\) is the account's reputation score (0 for a fresh account) \(r\) here is simply a random value, added to prevent \(h\) and \(u\) from being uncovered by brute-force search (in cryptography jargon, adding \(r\) makes the hash a hiding commitment).Suppose that a post uses a root \(R\) and stores \(\, \bar\}\). In the proof, it links to a previous post, with stored data \(\, \bar_, \bar_\}\). The post's proof is also required to walk over all the reputation entries that have been published between \(h_\) and \(h\). For each nullifier \(N\), the verification function would decrypt \(N\) using the user's key \(k\), and if the decryption outputs a valid index it would apply the reputation update. If the sum of all reputation updates is \(\delta\), the proof would finally check \(u = u_ + \delta\). If we want a "three strikes and you're out" rule, the ZK-SNARK would also check \(u > -3\). If we want a rule where a post can get a special "high-reputation poster" flag if the poster has \(\ge 100\) rep, we can accommodate that by adding "is \(u \ge 100\)?" as a public input. Many kinds of such rules can be accommodated.To increase the scalability of the scheme, we could split it up into two kinds of messages: posts and reputation update acknowledgements (RCAs). A post would be off-chain, though it would be required to point to an RCA made in the past week. RCAs would be on-chain, and an RCA would walk through all the reputation updates since that poster's previous RCA. This way, the on-chain load is reduced to one transaction per poster per week plus one transaction per reputation message (a very low level if reputation updates are rare, eg. they're only used for moderation actions or perhaps "post of the day" style prizes).Holding centralized parties accountableSometimes, you need to build a scheme that has a central "operator" of some kind. This could be for many reasons: sometimes it's for scalability, and sometimes it's for privacy - specifically, the privacy of data held by the operator.The MACI coercion-resistant voting system, for example, requires voters to submit their votes on-chain encrypted to a secret key held by a central operator. The operator would decrypt all the votes on-chain, count them up, and reveal the final result, along with a ZK-SNARK proving that they did everything correctly. This extra complexity is necessary to ensure a strong privacy property (called coercion-resistance): that users cannot prove to others how they voted even if they wanted to.Thanks to blockchains and ZK-SNARKs, the amount of trust in the operator can be kept very low. A malicious operator could still break coercion resistance, but because votes are published on the blockchain, the operator cannot cheat by censoring votes, and because the operator must provide a ZK-SNARK, they cannot cheat by mis-calculating the result.Combining ZK-SNARKs with MPCA more advanced use of ZK-SNARKs involves making proofs over computations where the inputs are split between two or more parties, and we don't want each party to learn the other parties' inputs. You can satisfy the privacy requirement with garbled circuits in the 2-party case, and more complicated multi-party computation protocols in the N-party case. ZK-SNARKs can be combined with these protocols to do verifiable multi-party computation.This could enable more advanced reputation systems where multiple participants can perform joint computations over their private inputs, it could enable privacy-preserving but authenticated data markets, and many other applications. That said, note that the math for doing this efficiently is still relatively in its infancy.What can't we make private?ZK-SNARKs are generally very effective for creating systems where users have private state. But ZK-SNARKs cannot hold private state that nobody knows. To make a proof about a piece of information, the prover has to know that piece of information in cleartext.A simple example of what can't (easily) be made private is Uniswap. In Uniswap, there is a single logically-central "thing", the market maker account, which belongs to no one, and every single trade on Uniswap is trading against the market maker account. You can't hide the state of the market maker account, because then someone would have to hold the state in cleartext to make proofs, and their active involvement would be necessary in every single transaction.You could make a centrally-operated, but safe and private, Uniswap with ZK-SNARKed garbled circuits, but it's not clear that the benefits of doing this are worth the costs. There may not even be any real benefit: the contract would need to be able to tell users what the prices of the assets are, and the block-by-block changes in the prices tell a lot about what the trading activity is.Blockchains can make state information global, ZK-SNARKs can make state information private, but we don't really have any good way to make state information global and private at the same time.Edit: you can use multi-party computation to implement shared private state. But this requires an honest-majority threshold assumption, and one that's likely unstable in practice because (unlike eg. with 51% attacks) a malicious majority could collude to break the privacy without ever being detected.Putting the primitives togetherIn the sections above, we've seen some examples that are powerful and useful tools by themselves, but they are also intended to serve as building blocks in other applications. Nullifiers, for example, are important for currency, but it turns out that they pop up again and again in all kinds of use cases.The "forced chaining" technique used in the negative reputation section is very broadly applicable. It's effective for many applications where users have complex "profiles" that change in complex ways over time, and you want to force the users to follow the rules of the system while preserving privacy so no one sees which user is performing which action. Users could even be required to have entire private Merkle trees representing their internal "state". The "commitment pool" gadget proposed in this post could be built with ZK-SNARKs. And if some application can't be entirely on-chain and must have a centralized operator, the exact same techniques can be used to keep the operator honest too.ZK-SNARKs are a really powerful tool for combining together the benefits of accountability and privacy. They do have their limits, though in some cases clever application design can work around those limits. I expect to see many more applications using ZK-SNARKs, and eventually applications combining ZK-SNARKs with other forms of cryptography, to be built in the years to come.
-
The roads not taken The roads not taken2022 Mar 29 See all posts The roads not taken The Ethereum protocol development community has made a lot of decisions in the early stages of Ethereum that have had a large impact on the project's trajectory. In some cases, Ethereum developers made conscious decisions to improve in some place where we thought that Bitcoin erred. In other places, we were creating something new entirely, and we simply had to come up with something to fill in a blank - but there were many somethings to choose from. And in still other places, we had a tradeoff between something more complex and something simpler. Sometimes, we chose the simpler thing, but sometimes, we chose the more complex thing too.This post will look at some of these forks-in-the-road as I remember them. Many of these features were seriously discussed within core development circles; others were barely considered at all but perhaps really should have been. But even still, it's worth looking at what a different Ethereum might have looked like, and what we can learn from this going forward.Should we have gone with a much simpler version of proof of stake?The Gasper proof of stake that Ethereum is very soon going to merge to is a complex system, but a very powerful system. Some of its properties include:Very strong single-block confirmations - as soon as a transaction gets included in a block, usually within a few seconds that block gets solidified to the point that it cannot be reverted unless either a large fraction of nodes are dishonest or there is extreme network latency. Economic finality - once a block gets finalized, it cannot be reverted without the attacker having to lose millions of ETH to being slashed. Very predictable rewards - validators reliably earn rewards every epoch (6.4 minutes), reducing incentives to pool Support for very high validator count - unlike most other chains with the above features, the Ethereum beacon chain supports hundreds of thousands of validators (eg. Tendermint offers even faster finality than Ethereum, but it only supports a few hundred validators) But making a system that has these properties is hard. It took years of research, years of failed experiments, and generally took a huge amount of effort. And the final output was pretty complex. If our researchers did not have to worry so much about consensus and had more brain cycles to spare, then maybe, just maybe, rollups could have been invented in 2016. This brings us to a question: should we really have had such high standards for our proof of stake, when even a much simpler and weaker version of proof of stake would have been a large improvement over the proof of work status quo?Many have the misconception that proof of stake is inherently complex, but in reality there are plenty of proof of stake algorithms that are almost as simple as Nakamoto PoW. NXT proof of stake existed since 2013 and would have been a natural candidate; it had issues but those issues could easily have been patched, and we could have had a reasonably well-working proof of stake from 2017, or even from the beginning. The reason why Gasper is more complex than these algorithms is simply that it tries to accomplish much more than they do. But if we had been more modest at the beginning, we could have focused on achieving a more limited set of objectives first.Proof of stake from the beginning would in my opinion have been a mistake; PoW was helpful in expanding the initial issuance distribution and making Ethereum accessible, as well as encouraging a hobbyist community. But switching to a simpler proof of stake in 2017, or even 2020, could have led to much less environmental damage (and anti-crypto mentality as a result of environmental damage) and a lot more research talent being free to think about scaling. Would we have had to spend a lot of resources on making a better proof of stake eventually? Yes. But it's increasingly looking like we'll end up doing that anyway.The de-complexification of shardingEthereum sharding has been on a very consistent trajectory of becoming less and less complex since the ideas started being worked on in 2014. First, we had complex sharding with built-in execution and cross-shard transactions. Then, we simplified the protocol by moving more responsibilities to the user (eg. in a cross-shard transaction, the user would have to separately pay for gas on both shards). Then, we switched to the rollup-centric roadmap where, from the protocol's point of view, shards are just blobs of data. Finally, with danksharding, the shard fee markets are merged into one, and the final design just looks like a non-sharded chain but where some data availability sampling magic happens behind the scenes to make sharded verification happen. Sharding in 2015 Sharding in 2022 But what if we had gone the opposite path? Well, there actually are Ethereum researchers who heavily explored a much more sophisticated sharding system: shards would be chains, there would be fork choice rules where child chains depend on parent chains, cross-shard messages would get routed by the protocol, validators would be rotated between shards, and even applications would get automatically load-balanced between shards!The problem with that approach: those forms of sharding are largely just ideas and mathematical models, whereas Danksharding is a complete and almost-ready-for-implementation spec. Hence, given Ethereum's circumstances and constraints, the simplification and de-ambitionization of sharding was, in my opinion, absolutely the right move. That said, the more ambitious research also has a very important role to play: it identifies promising research directions, even the very complex ideas often have "reasonably simple" versions of those ideas that still provide a lot of benefits, and there's a good chance that it will significantly influence Ethereum's protocol development (or even layer-2 protocols) over the years to come.More or less features in the EVM?Realistically, the specification of the EVM was basically, with the exception of security auditing, viable for launch by mid-2014. However, over the next few months we continued actively exploring new features that we felt might be really important for a decentralized application blockchain. Some did not go in, others did.We considered adding a POST opcode, but decided against it. The POST opcode would have made an asynchronous call, that would get executed after the rest of the transaction finishes. We considered adding an ALARM opcode, but decided against it. ALARM would have functioned like POST, except executing the asynchronous call in some future block, allowing contracts to schedule operations. We added logs, which allow contracts to output records that do not touch the state, but could be interpreted by dapp interfaces and wallets. Notably, we also considered making ETH transfers emit a log, but decided against it - the rationale being that "people will soon switch to smart contract wallets anyway". We considered expanding SSTORE to support byte arrays, but decided against it, because of concerns about complexity and safety. We added precompiles, contracts which execute specialized cryptographic operations with native implementations at a much cheaper gas cost than can be done in the EVM. In the months right after launch, state rent was considered again and again, but was never included. It was just too complicated. Today, there are much better state expiry schemes being actively explored, though stateless verification and proposer/builder separation mean that it is now a much lower priority. Looking at this today, most of the decisions to not add more features have proven to be very good decisions. There was no obvious reason to add a POST opcode. An ALARM opcode is actually very difficult to implement safely: what happens if everyone in blocks 1...99999 sets an ALARM to execute a lot of code at block 100000? Will that block take hours to process? Will some scheduled operations get pushed back to later blocks? But if that happens, then what guarantees is ALARM even preserving? SSTORE for byte arrays is difficult to do safely, and would have greatly expanded worst-case witness sizes.The state rent issue is more challenging: had we actually implemented some kind of state rent from day 1, we would not have had a smart contract ecosystem evolve around a normalized assumption of persistent state. Ethereum would have been harder to build for, but it could have been more scalable and sustainable. At the same time, the state expiry schemes we had back then really were much worse than what we have now. Sometimes, good ideas just take years to arrive at and there is no better way around that.Alternative paths for LOGLOG could have been done differently in two different ways:We could have made ETH transfers auto-issue a LOG. This would have saved a lot of effort and software bug issues for exchanges and many other users, and would have accelerated everyone relying on logs that would have ironically helped smart contract wallet adoption. We could have not bothered with a LOG opcode at all, and instead made it an ERC: there would be a standard contract that has a function submitLog and uses the technique from the Ethereum deposit contract to compute a Merkle root of all logs in that block. Either EIP-2929 or block-scoped storage (equivalent to TSTORE but cleared after the block) would have made this cheap. We strongly considered (1), but rejected it. The main reason was simplicity: it's easier for logs to just come from the LOG opcode. We also (very wrongly!) expected most users to quickly migrate to smart contract wallets, which could have logged transfers explicitly using the opcode.was not considered, but in retrospect it was always an option. The main downside of (2) would have been the lack of a Bloom filter mechanism for quickly scanning for logs. But as it turns out, the Bloom filter mechanism is too slow to be user-friendly for dapps anyway, and so these days more and more people use TheGraph for querying anyway. On the whole, it seems very possible that either one of these approaches would have been superior to the status quo. Keeping LOG outside the protocol would have kept things simpler, but if it was inside the protocol auto-logging all ETH transfers would have made it more useful.Today, I would probably favor the eventual abolition of the LOG opcode from the EVM.What if the EVM was something totally different?There were two natural very different paths that the EVM could have taken:Make the EVM be a higher-level language, with built-in constructs for variables, if-statements, loops, etc. Make the EVM be a copy of some existing VM (LLVM, WASM, etc) The first path was never really considered. The attraction of this path is that it could have made compilers simpler, and allowed more developers to code in EVM directly. It could have also made ZK-EVM constructions simpler. The weakness of the path is that it would have made EVM code structurally more complicated: instead of being a simple list of opcodes in a row, it would have been a more complicated data structure that would have had to be stored somehow. That said, there was a missed opportunity for a best-of-both-worlds: some EVM changes could have given us a lot of those benefits while keeping the basic EVM structure roughly as is: ban dynamic jumps and add some opcodes designed to support subroutines (see also: EIP-2315), allow memory access only on 32-byte word boundaries, etc.The second path was suggested many times, and rejected many times. The usual argument for it is that it would allow programs to compile from existing languages (C, Rust, etc) into the EVM. The argument against has always been that given Ethereum's unique constraints it would not actually provide any benefits:Existing compilers from high-level languages tend to not care about total code size, whereas blockchain code must optimize heavily to cut down every byte of code size We need multiple implementations of the VM with a hard requirement that two implementations never process the same code differently. Security-auditing and verifying this on code that we did not write would be much harder. If the VM specification changes, Ethereum would have to either always update along with it or fall more and more out-of-sync. Hence, there probably was never a viable path for the EVM that's radically different from what we have today, though there are lots of smaller details (jumps, 64 vs 256 bit, etc) that could have led to much better outcomes if they were done differently.Should the ETH supply have been distributed differently?The current ETH supply is approximately represented by this chart from Etherscan: About half of the ETH that exists today was sold in an open public ether sale, where anyone could send BTC to a standardized bitcoin address, and the initial ETH supply distribution was computed by an open-source script that scans the Bitcoin blockchain for transactions going to that address. Most of the remainder was mined. The slice at the bottom, the 12M ETH marked "other", was the "premine" - a piece distributed between the Ethereum Foundation and ~100 early contributors to the Ethereum protocol.There are two main criticisms of this process:The premine, as well as the fact that the Ethereum Foundation received the sale funds, is not credibly neutral. A few recipient addresses were hand-picked through a closed process, and the Ethereum Foundation had to be trusted to not take out loans to recycle funds received furing the sale back into the sale to give itself more ETH (we did not, and no one seriously claims that we have, but even the requirement to be trusted at all offends some). The premine over-rewarded very early contributors, and left too little for later contributors. 75% of the premine went to rewarding contributors for their work before launch, and post-launch the Ethereum Foundation only had 3 million ETH left. Within 6 months, the need to sell to financially survive decreased that to around 1 million ETH. In a way, the problems were related: the desire to minimize perceptions of centralization contributed to a smaller premine, and a smaller premine was exhausted more quickly.This is not the only way that things could have been done. Zcash has a different approach: a constant 20% of the block reward goes to a set of recipients hard-coded in the protocol, and the set of recipients gets re-negotiated every 4 years (so far this has happened once). This would have been much more sustainable, but it would have been much more heavily criticized as centralized (the Zcash community seems to be more openly okay with more technocratic leadership than the Ethereum community).One possible alternative path would be something similar to the "DAO from day 1" route popular among some defi projects today. Here is a possible strawman proposal:We agree that for 2 years, a block reward of 2 ETH per block goes into a dev fund. Anyone who purchases ETH in the ether sale could specify a vote for their preferred distribution of the dev fund (eg. "1 ETH per block to the Ethereum Foundation, 0.4 ETH to the Consensys research team, 0.2 ETH to Vlad Zamfir...") Recipients that got voted for get a share from the dev fund equal to the median of everyone's votes, scaled so that the total equals 2 ETH per block (median is to prevent self-dealing: if you vote for yourself you get nothing unless you get at least half of other purchasers to mention you) The sale could be run by a legal entity that promises to distribute the bitcoin received during the sale along the same ratios as the ETH dev fund (or burned, if we really wanted to make bitcoiners happy). This probably would have led to the Ethereum Foundation getting a lot of funding, non-EF groups also getting a lot of funding (leading to more ecosystem decentralization), all without breaking credible neutrality one single bit. The main downside is of course that coin voting really sucks, but pragmatically we could have realized that 2014 was still an early and idealistic time and the most serious downsides of coin voting would only start coming into play long after the sale ends.Would this have been a better idea and set a better precedent? Maybe! Though realistically even if the dev fund had been fully credibly neutral, the people who yell about Ethereum's premine today may well have just started yelling twice as hard about the DAO fork instead.What can we learn from all this?In general, it sometimes feels to me like Ethereum's biggest challenges come from balancing between two visions - a pure and simple blockchain that values safety and simplicity, and a highly performant and functional platform for building advanced applications. Many of the examples above are just aspects of this: do we have fewer features and be more Bitcoin-like, or more features and be more developer-friendly? Do we worry a lot about making development funding credibly neutral and be more Bitcoin-like, or do we just worry first and foremost about making sure devs are rewarded enough to make Ethereum great?My personal dream is to try to achieve both visions at the same time - a base layer where the specification becomes smaller each year than the year before it, and a powerful developer-friendly advanced application ecosystem centered around layer-2 protocols. That said, getting to such an ideal world takes a long time, and a more explicit realization that it would take time and we need to think about the roadmap step-by-step would have probably helped us a lot.Today, there are a lot of things we cannot change, but there are many things that we still can, and there is still a path solidly open to improving both functionality and simplicity. Sometimes the path is a winding one: we need to add some more complexity first to enable sharding, which in turn enables lots of layer-2 scalability on top. That said, reducing complexity is possible, and Ethereum's history has already demonstrated this:EIP-150 made the call stack depth limit no longer relevant, reducing security worries for contract developers. EIP-161 made the concept of an "empty account" as something separate from an account whose fields are zero no longer exist. EIP-3529 removed part of the refund mechanism and made gas tokens no longer viable. Ideas in the pipeline, like Verkle trees, reduce complexity even further. But the question of how to balance the two visions better in the future is one that we should start more actively thinking about.