找到
1087
篇与
heyuan
相关的结果
-
 Travel time ~= 750 * distance ^ 0.6 Travel time ~= 750 * distance ^ 0.62023 Apr 14 See all posts Travel time ~= 750 * distance ^ 0.6 As another exercise in using ChatGPT 3.5 to do weird things and seeing what happens, I decided to explore an interesting question: how does the time it takes to travel from point A to point B scale with distance, in the real world? That is to say, if you sample randomly from positions where people are actually at (so, for example, 56% of points you choose would be in cities), and you use public transportation, how does travel time scale with distance?Obviously, travel time would grow slower than linearly: the further you have to go, the more opportunity you have to resort to forms of transportation that are faster, but have some fixed overhead. Outside of a very few lucky cases, there is no practical way to take a bus to go faster if your destination is 170 meters away, but if your destination is 170 kilometers away, you suddenly get more options. And if it's 1700 kilometers away, you get airplanes.So I asked ChatGPT for the ingredients I would need: I went with the GeoLife dataset. I did notice that while it claims to be about users around the world, primarily it seems to focus on people in Seattle and Beijing, though they do occasionally visit other cities. That said, I'm not a perfectionist and I was fine with it. I asked ChatGPT to write me a script to interpret the dataset and extract a randomly selected coordinate from each file: Amazingly, it almost succeeded on the first try. It did make the mistake of assuming every item in the list would be a number (values = [float(x) for x in line.strip().split(',')]), though perhaps to some extent that was my fault: when I said "the first two values" it probably interpreted that as implying that the entire line was made up of "values" (ie. numbers).I fixed the bug manually. Now, I have a way to get some randomly selected points where people are at, and I have an API to get the public transit travel time between the points.I asked it for more coding help:Asking how to get an API key for the Google Maps Directions API (it gave an answer that seems to be outdated, but that succeeded at immediately pointing me to the right place) Writing a function to compute the straight-line distance between two GPS coordinates (it gave the correct answer on the first try) Given a list of (distance, time) pairs, drawing a scatter plot, with time and distance as axes, both axes logarithmically scaled (it gave the correct answer on the first try) Doing a linear regression on the logarithms of distance and time to try to fit the data to a power law (it bugged on the first try, succeeded on the second) This gave me some really nice data (this is filtered for distances under 500km, as above 500km the best path almost certainly includes flying, and the Google Maps directions don't take into account flights): The power law fit that the linear regression gave is: travel_time = 965.8020738916074 * distance^0.6138556361612214 (time in seconds, distance in km).Now, I needed travel time data for longer distances, where the optimal route would include flights. Here, APIs could not help me: I asked ChatGPT if there were APIs that could do such a thing, and it did not give a satisfactory answer. I resorted to doing it manually:I used the same script, but modified it slightly to only output pairs of points which were more than 500km apart from each other. I took the first 8 results within the United States, and the first 8 with at least one end outside the United States, skipping over results that represented a city pair that had already been covered. For each result I manually obtained: to_airport: the public transit travel time from the starting point to the nearest airport, using Google Maps outside China and Baidu Maps inside China. from_airport: the public transit travel time to the end point from the nearest airport flight_time: the flight time from the starting point to the end point. I used Google Flights) and always took the top result, except in cases where the top result was completely crazy (more than 2x the length of the shortest), in which case I took the shortest. I computed the travel time as (to_airport) * 1.5 + (90 if international else 60) + flight_time + from_airport. The first part is a fairly aggressive formula (I personally am much more conservative than this) for when to leave for the airport: aim to arrive 60 min before if domestic and 90 min before if international, and multiply expected travel time by 1.5x in case there are any mishaps or delays. This was boring and I was not interested in wasting my time to do more than 16 of these; I presume if I was a serious researcher I would already have an account set up on TaskRabbit or some similar service that would make it easier to hire other people to do this for me and get much more data. In any case, 16 is enough; I put my resulting data here.Finally, just for fun, I added some data for how long it would take to travel to various locations in space: the moon (I added 12 hours to the time to take into account an average person's travel time to the launch site), Mars, Pluto and Alpha Centauri. You can find my complete code here.Here's the resulting chart: travel_time = 733.002223593754 * distance^0.591980777827876 WAAAAAT?!?!! From this chart it seems like there is a surprisingly precise relationship governing travel time from point A to point B that somehow holds across such radically different transit media as walking, subways and buses, airplanes and (!!) interplanetary and hypothetical interstellar spacecraft. I swear that I am not cherrypicking; I did not throw out any data that was inconvenient, everything (including the space stuff) that I checked I put on the chart.ChatGPT 3.5 worked impressively well this time; it certainly stumbled and fell much less than my previous misadventure, where I tried to get it to help me convert IPFS bafyhashes into hex. In general, ChatGPT seems uniquely good at teaching me about libraries and APIs I've never heard of before but that other people use all the time; this reduces the barrier to entry between amateurs and professionals which seems like a very positive thing.So there we go, there seems to be some kind of really weird fractal law of travel time. Of course, different transit technologies could change this relationship: if you replace public transit with cars and commercial flights with private jets, travel time becomes somewhat more linear. And once we upload our minds onto computer hardware, we'll be able to travel to Alpha Centauri on much crazier vehicles like ultralight craft propelled by Earth-based lightsails) that could let us go anywhere at a significant fraction of the speed of light. But for now, it does seem like there is a strangely consistent relationship that puts time much closer to the square root of distance.
Travel time ~= 750 * distance ^ 0.6 Travel time ~= 750 * distance ^ 0.62023 Apr 14 See all posts Travel time ~= 750 * distance ^ 0.6 As another exercise in using ChatGPT 3.5 to do weird things and seeing what happens, I decided to explore an interesting question: how does the time it takes to travel from point A to point B scale with distance, in the real world? That is to say, if you sample randomly from positions where people are actually at (so, for example, 56% of points you choose would be in cities), and you use public transportation, how does travel time scale with distance?Obviously, travel time would grow slower than linearly: the further you have to go, the more opportunity you have to resort to forms of transportation that are faster, but have some fixed overhead. Outside of a very few lucky cases, there is no practical way to take a bus to go faster if your destination is 170 meters away, but if your destination is 170 kilometers away, you suddenly get more options. And if it's 1700 kilometers away, you get airplanes.So I asked ChatGPT for the ingredients I would need: I went with the GeoLife dataset. I did notice that while it claims to be about users around the world, primarily it seems to focus on people in Seattle and Beijing, though they do occasionally visit other cities. That said, I'm not a perfectionist and I was fine with it. I asked ChatGPT to write me a script to interpret the dataset and extract a randomly selected coordinate from each file: Amazingly, it almost succeeded on the first try. It did make the mistake of assuming every item in the list would be a number (values = [float(x) for x in line.strip().split(',')]), though perhaps to some extent that was my fault: when I said "the first two values" it probably interpreted that as implying that the entire line was made up of "values" (ie. numbers).I fixed the bug manually. Now, I have a way to get some randomly selected points where people are at, and I have an API to get the public transit travel time between the points.I asked it for more coding help:Asking how to get an API key for the Google Maps Directions API (it gave an answer that seems to be outdated, but that succeeded at immediately pointing me to the right place) Writing a function to compute the straight-line distance between two GPS coordinates (it gave the correct answer on the first try) Given a list of (distance, time) pairs, drawing a scatter plot, with time and distance as axes, both axes logarithmically scaled (it gave the correct answer on the first try) Doing a linear regression on the logarithms of distance and time to try to fit the data to a power law (it bugged on the first try, succeeded on the second) This gave me some really nice data (this is filtered for distances under 500km, as above 500km the best path almost certainly includes flying, and the Google Maps directions don't take into account flights): The power law fit that the linear regression gave is: travel_time = 965.8020738916074 * distance^0.6138556361612214 (time in seconds, distance in km).Now, I needed travel time data for longer distances, where the optimal route would include flights. Here, APIs could not help me: I asked ChatGPT if there were APIs that could do such a thing, and it did not give a satisfactory answer. I resorted to doing it manually:I used the same script, but modified it slightly to only output pairs of points which were more than 500km apart from each other. I took the first 8 results within the United States, and the first 8 with at least one end outside the United States, skipping over results that represented a city pair that had already been covered. For each result I manually obtained: to_airport: the public transit travel time from the starting point to the nearest airport, using Google Maps outside China and Baidu Maps inside China. from_airport: the public transit travel time to the end point from the nearest airport flight_time: the flight time from the starting point to the end point. I used Google Flights) and always took the top result, except in cases where the top result was completely crazy (more than 2x the length of the shortest), in which case I took the shortest. I computed the travel time as (to_airport) * 1.5 + (90 if international else 60) + flight_time + from_airport. The first part is a fairly aggressive formula (I personally am much more conservative than this) for when to leave for the airport: aim to arrive 60 min before if domestic and 90 min before if international, and multiply expected travel time by 1.5x in case there are any mishaps or delays. This was boring and I was not interested in wasting my time to do more than 16 of these; I presume if I was a serious researcher I would already have an account set up on TaskRabbit or some similar service that would make it easier to hire other people to do this for me and get much more data. In any case, 16 is enough; I put my resulting data here.Finally, just for fun, I added some data for how long it would take to travel to various locations in space: the moon (I added 12 hours to the time to take into account an average person's travel time to the launch site), Mars, Pluto and Alpha Centauri. You can find my complete code here.Here's the resulting chart: travel_time = 733.002223593754 * distance^0.591980777827876 WAAAAAT?!?!! From this chart it seems like there is a surprisingly precise relationship governing travel time from point A to point B that somehow holds across such radically different transit media as walking, subways and buses, airplanes and (!!) interplanetary and hypothetical interstellar spacecraft. I swear that I am not cherrypicking; I did not throw out any data that was inconvenient, everything (including the space stuff) that I checked I put on the chart.ChatGPT 3.5 worked impressively well this time; it certainly stumbled and fell much less than my previous misadventure, where I tried to get it to help me convert IPFS bafyhashes into hex. In general, ChatGPT seems uniquely good at teaching me about libraries and APIs I've never heard of before but that other people use all the time; this reduces the barrier to entry between amateurs and professionals which seems like a very positive thing.So there we go, there seems to be some kind of really weird fractal law of travel time. Of course, different transit technologies could change this relationship: if you replace public transit with cars and commercial flights with private jets, travel time becomes somewhat more linear. And once we upload our minds onto computer hardware, we'll be able to travel to Alpha Centauri on much crazier vehicles like ultralight craft propelled by Earth-based lightsails) that could let us go anywhere at a significant fraction of the speed of light. But for now, it does seem like there is a strangely consistent relationship that puts time much closer to the square root of distance. -
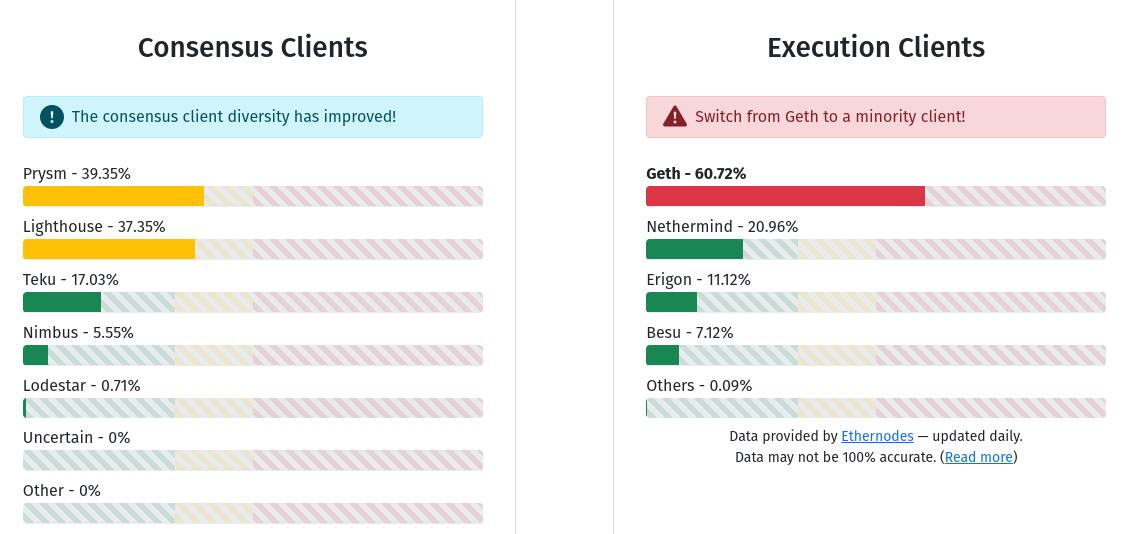
How will Ethereum's multi-client philosophy interact with ZK-EVMs? How will Ethereum's multi-client philosophy interact with ZK-EVMs?2023 Mar 31 See all posts How will Ethereum's multi-client philosophy interact with ZK-EVMs? Special thanks to Justin Drake for feedback and reviewOne underdiscussed, but nevertheless very important, way in which Ethereum maintains its security and decentralization is its multi-client philosophy. Ethereum intentionally has no "reference client" that everyone runs by default: instead, there is a collaboratively-managed specification (these days written in the very human-readable but very slow Python) and there are multiple teams making implementations of the spec (also called "clients"), which is what users actually run. Each Ethereum node runs a consensus client and an execution client. As of today, no consensus or execution client makes up more than 2/3 of the network. If a client with less than 1/3 share in its category has a bug, the network would simply continue as normal. If a client with between 1/3 and 2/3 share in its category (so, Prysm, Lighthouse or Geth) has a bug, the chain would continue adding blocks, but it would stop finalizing blocks, giving time for developers to intervene. One underdiscussed, but nevertheless very important, major upcoming transition in the way the Ethereum chain gets validated is the rise of ZK-EVMs. SNARKs proving EVM execution have been under development for years already, and the technology is actively being used by layer 2 protocols called ZK rollups. Some of these ZK rollups are active on mainnet today, with more coming soon. But in the longer term, ZK-EVMs are not just going to be for rollups; we want to use them to verify execution on layer 1 as well (see also: the Verge).Once that happens, ZK-EVMs de-facto become a third type of Ethereum client, just as important to the network's security as execution clients and consensus clients are today. And this naturally raises a question: how will ZK-EVMs interact with the multi-client philosophy? One of the hard parts is already done: we already have multiple ZK-EVM implementations that are being actively developed. But other hard parts remain: how would we actually make a "multi-client" ecosystem for ZK-proving correctness of Ethereum blocks? This question opens up some interesting technical challenges - and of course the looming question of whether or not the tradeoffs are worth it.What was the original motivation for Ethereum's multi-client philosophy?Ethereum's multi-client philosophy is a type of decentralization, and like decentralization in general, one can focus on either the technical benefits of architectural decentralization or the social benefits of political decentralization. Ultimately, the multi-client philosophy was motivated by both and serves both.Arguments for technical decentralizationThe main benefit of technical decentralization is simple: it reduces the risk that one bug in one piece of software leads to a catastrophic breakdown of the entire network. A historical situation that exemplifies this risk is the 2010 Bitcoin overflow bug. At the time, the Bitcoin client code did not check that the sum of the outputs of a transaction does not overflow (wrap around to zero by summing to above the maximum integer of \(2^ - 1\)), and so someone made a transaction that did exactly that, giving themselves billions of bitcoins. The bug was discovered within hours, and a fix was rushed through and quickly deployed across the network, but had there been a mature ecosystem at the time, those coins would have been accepted by exchanges, bridges and other structures, and the attackers could have gotten away with a lot of money. If there had been five different Bitcoin clients, it would have been very unlikely that all of them had the same bug, and so there would have been an immediate split, and the side of the split that was buggy would have probably lost.There is a tradeoff in using the multi-client approach to minimize the risk of catastrophic bugs: instead, you get consensus failure bugs. That is, if you have two clients, there is a risk that the clients have subtly different interpretations of some protocol rule, and while both interpretations are reasonable and do not allow stealing money, the disagreement would cause the chain to split in half. A serious split of that type happened once in Ethereum's history (there have been other much smaller splits where very small portions of the network running old versions of the code forked off). Defenders of the single-client approach point to consensus failures as a reason to not have multiple implementations: if there is only one client, that one client will not disagree with itself. Their model of how number of clients translates into risk might look something like this: I, of course, disagree with this analysis. The crux of my disagreement is that (i) 2010-style catastrophic bugs matter too, and (ii) you never actually have only one client. The latter point is made most obvious by the Bitcoin fork of 2013: a chain split occurred because of a disagreement between two different versions of the Bitcoin client, one of which turned out to have an accidental and undocumented limit on the number of objects that could be modified in a single block. Hence, one client in theory is often two clients in practice, and five clients in theory might be six or seven clients in practice - so we should just take the plunge and go on the right side of the risk curve, and have at least a few different clients.Arguments for political decentralizationMonopoly client developers are in a position with a lot of political power. If a client developer proposes a change, and users disagree, theoretically they could refuse to download the updated version, or create a fork without it, but in practice it's often difficult for users to do that. What if a disagreeable protocol change is bundled with a necessary security update? What if the main team threatens to quit if they don't get their way? Or, more tamely, what if the monopoly client team ends up being the only group with the greatest protocol expertise, leaving the rest of the ecosystem in a poor position to judge technical arguments that the client team puts forward, leaving the client team with a lot of room to push their own particular goals and values, which might not match with the broader community?Concern about protocol politics, particularly in the context of the 2013-14 Bitcoin OP_RETURN wars where some participants were openly in favor of discriminating against particular usages of the chain, was a significant contributing factor in Ethereum's early adoption of a multi-client philosophy, which was aimed to make it harder for a small group to make those kinds of decisions. Concerns specific to the Ethereum ecosystem - namely, avoiding concentration of power within the Ethereum Foundation itself - provided further support for this direction. In 2018, a decision was made to intentionally have the Foundation not make an implementation of the Ethereum PoS protocol (ie. what is now called a "consensus client"), leaving that task entirely to outside teams.How will ZK-EVMs come in on layer 1 in the future?Today, ZK-EVMs are used in rollups. This increases scaling by allowing expensive EVM execution to happen only a few times off-chain, with everyone else simply verifying SNARKs posted on-chain that prove that the EVM execution was computed correctly. It also allows some data (particularly signatures) to not be included on-chain, saving on gas costs. This gives us a lot of scalability benefits, and the combination of scalable computation with ZK-EVMs and scalable data with data availability sampling could let us scale very far.However, the Ethereum network today also has a different problem, one that no amount of layer 2 scaling can solve by itself: the layer 1 is difficult to verify, to the point where not many users run their own node. Instead, most users simply trust third-party providers. Light clients such as Helios and Succinct are taking steps toward solving the problem, but a light client is far from a fully verifying node: a light client merely verifies the signatures of a random subset of validators called the sync committee, and does not verify that the chain actually follows the protocol rules. To bring us to a world where users can actually verify that the chain follows the rules, we would have to do something different.Option 1: constrict layer 1, force almost all activity to move to layer 2We could over time reduce the layer 1 gas-per-block target down from 15 million to 1 million, enough for a block to contain a single SNARK and a few deposit and withdraw operations but not much else, and thereby force almost all user activity to move to layer 2 protocols. Such a design could still support many rollups committing in each block: we could use off-chain aggregation protocols run by customized builders to gather together SNARKs from multiple layer 2 protocols and combine them into a single SNARK. In such a world, the only function of layer 1 would be to be a clearinghouse for layer 2 protocols, verifying their proofs and occasionally facilitating large funds transfers between them. This approach could work, but it has several important weaknesses:It's de-facto backwards-incompatible, in the sense that many existing L1-based applications become economically nonviable. User funds up to hundreds or thousands of dollars could get stuck as fees become so high that they exceed the cost of emptying those accounts. This could be addressed by letting users sign messages to opt in to an in-protocol mass migration to an L2 of their choice (see some early implementation ideas here), but this adds complexity to the transition, and making it truly cheap enough would require some kind of SNARK at layer 1 anyway. I'm generally a fan of breaking backwards compatibility when it comes to things like the SELFDESTRUCT opcode, but in this case the tradeoff seems much less favorable. It might still not make verification cheap enough. Ideally, the Ethereum protocol should be easy to verify not just on laptops but also inside phones, browser extensions, and even inside other chains. Syncing the chain for the first time, or after a long time offline, should also be easy. A laptop node could verify 1 million gas in ~20 ms, but even that implies 54 seconds to sync after one day offline (assuming single slot finality increases slot times to 32s), and for phones or browser extensions it would take a few hundred milliseconds per block and might still be a non-negligible battery drain. These numbers are manageable, but they are not ideal. Even in an L2-first ecosystem, there are benefits to L1 being at least somewhat affordable. Validiums can benefit from a stronger security model if users can withdraw their funds if they notice that new state data is no longer being made available. Arbitrage becomes more efficient, especially for smaller tokens, if the minimum size of an economically viable cross-L2 direct transfer is smaller. Hence, it seems more reasonable to try to find a way to use ZK-SNARKs to verify the layer 1 itself.Option 2: SNARK-verify the layer 1A type 1 (fully Ethereum-equivalent) ZK-EVM can be used to verify the EVM execution of a (layer 1) Ethereum block. We could write more SNARK code to also verify the consensus side of a block. This would be a challenging engineering problem: today, ZK-EVMs take minutes to hours to verify Ethereum blocks, and generating proofs in real time would require one or more of (i) improvements to Ethereum itself to remove SNARK-unfriendly components, (ii) either large efficiency gains with specialized hardware, and (iii) architectural improvements with much more parallelization. However, there is no fundamental technological reason why it cannot be done - and so I expect that, even if it takes many years, it will be done.Here is where we see the intersection with the multi-client paradigm: if we use ZK-EVMs to verify layer 1, which ZK-EVM do we use?I see three options:Single ZK-EVM: abandon the multi-client paradigm, and choose a single ZK-EVM that we use to verify blocks. Closed multi ZK-EVM: agree on and enshrine in consensus a specific set of multiple ZK-EVMs, and have a consensus-layer protocol rule that a block needs proofs from more than half of the ZK-EVMs in that set to be considered valid. Open multi ZK-EVM: different clients have different ZK-EVM implementations, and each client waits for a proof that is compatible with its own implementation before accepting a block as valid. To me, (3) seems ideal, at least until and unless our technology improves to the point where we can formally prove that all of the ZK-EVM implementations are equivalent to each other, at which point we can just pick whichever one is most efficient. (1) would sacrifice the benefits of the multi-client paradigm, and (2) would close off the possibility of developing new clients and lead to a more centralized ecosystem. (3) has challenges, but those challenges seem smaller than the challenges of the other two options, at least for now.Implementing (3) would not be too hard: one might have a p2p sub-network for each type of proof, and a client that uses one type of proof would listen on the corresponding sub-network and wait until they receive a proof that their verifier recognizes as valid.The two main challenges of (3) are likely the following:The latency challenge: a malicious attacker could publish a block late, along with a proof valid for one client. It would realistically take a long time (even if eg. 15 seconds) to generate proofs valid for other clients. This time would be long enough to potentially create a temporary fork and disrupt the chain for a few slots. Data inefficiency: one benefit of ZK-SNARKs is that data that is only relevant to verification (sometimes called "witness data") could be removed from a block. For example, once you've verified a signature, you don't need to keep the signature in a block, you could just store a single bit saying that the signature is valid, along with a single proof in the block confirming that all of the valid signatures exist. However, if we want it to be possible to generate proofs of multiple types for a block, the original signatures would need to actually be published. The latency challenge could be addressed by being careful when designing the single-slot finality protocol. Single-slot finality protocols will likely require more than two rounds of consensus per slot, and so one could require the first round to include the block, and only require nodes to verify proofs before signing in the third (or final) round. This ensures that a significant time window is always available between the deadline for publishing a block and the time when it's expected for proofs to be available.The data efficiency issue would have to be addressed by having a separate protocol for aggregating verification-related data. For signatures, we could use BLS aggregation, which ERC-4337 already supports. Another major category of verification-related data is ZK-SNARKs used for privacy. Fortunately, these often tend to have their own aggregation protocols.It is also worth mentioning that SNARK-verifying the layer 1 has an important benefit: the fact that on-chain EVM execution no longer needs to be verified by every node makes it possible to greatly increase the amount of EVM execution taking place. This could happen either by greatly increasing the layer 1 gas limit, or by introducing enshrined rollups, or both.ConclusionsMaking an open multi-client ZK-EVM ecosystem work well will take a lot of work. But the really good news is that much of this work is happening or will happen anyway:We have multiple strong ZK-EVM implementations already. These implementations are not yet type 1 (fully Ethereum-equivalent), but many of them are actively moving in that direction. The work on light clients such as Helios and Succinct may eventually turn into a more full SNARK-verification of the PoS consensus side of the Ethereum chain. Clients will likely start experimenting with ZK-EVMs to prove Ethereum block execution on their own, especially once we have stateless clients and there's no technical need to directly re-execute every block to maintain the state. We will probably get a slow and gradual transition from clients verifying Ethereum blocks by re-executing them to most clients verifying Ethereum blocks by checking SNARK proofs. The ERC-4337 and PBS ecosystems are likely to start working with aggregation technologies like BLS and proof aggregation pretty soon, in order to save on gas costs. On BLS aggregation, work has already started. With these technologies in place, the future looks very good. Ethereum blocks would be smaller than today, anyone could run a fully verifying node on their laptop or even their phone or inside a browser extension, and this would all happen while preserving the benefits of Ethereum's multi-client philosophy.In the longer-term future, of course anything could happen. Perhaps AI will super-charge formal verification to the point where it can easily prove ZK-EVM implementations equivalent and identify all the bugs that cause differences between them. Such a project may even be something that could be practical to start working on now. If such a formal verification-based approach succeeds, different mechanisms would need to be put in place to ensure continued political decentralization of the protocol; perhaps at that point, the protocol would be considered "complete" and immutability norms would be stronger. But even if that is the longer-term future, the open multi-client ZK-EVM world seems like a natural stepping stone that is likely to happen anyway.In the nearer term, this is still a long journey. ZK-EVMs are here, but ZK-EVMs becoming truly viable at layer 1 would require them to become type 1, and make proving fast enough that it can happen in real time. With enough parallelization, this is doable, but it will still be a lot of work to get there. Consensus changes like raising the gas cost of KECCAK, SHA256 and other hash function precompiles will also be an important part of the picture. That said, the first steps of the transition may happen sooner than we expect: once we switch to Verkle trees and stateless clients, clients could start gradually using ZK-EVMs, and a transition to an "open multi-ZK-EVM" world could start happening all on its own.
-
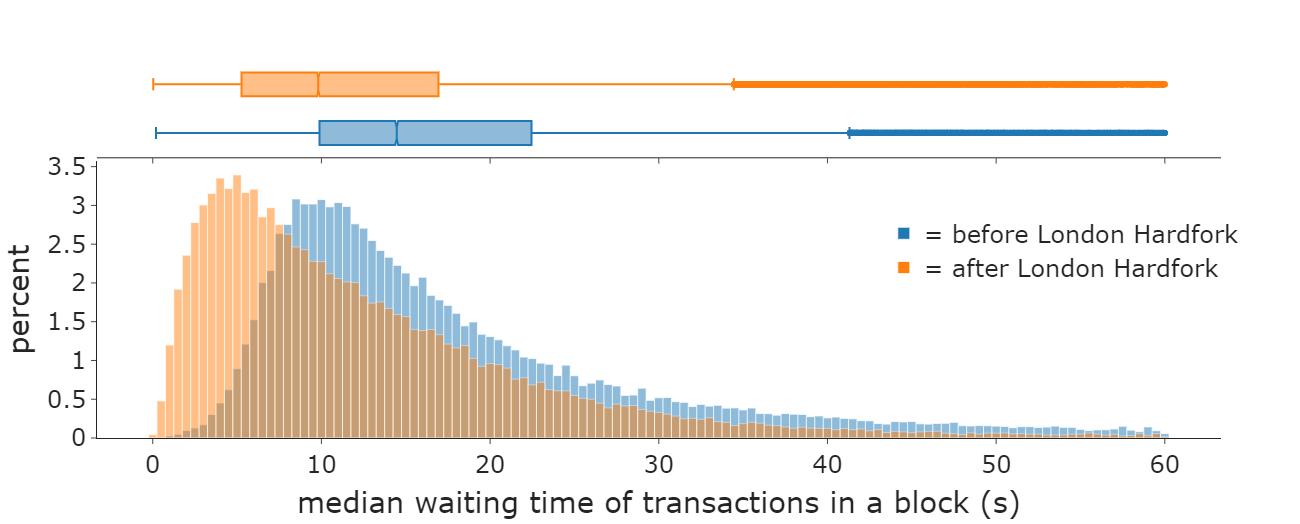
Some personal user experiences Some personal user experiences2023 Feb 28 See all posts Some personal user experiences In 2013, I went to a sushi restaurant beside the Internet Archive in San Francisco, because I had heard that it accepted bitcoin for payments and I wanted to try it out. When it came time to pay the bill, I asked to pay in BTC. I scanned the QR code, and clicked "send". To my surprise, the transaction did not go through; it appeared to have been sent, but the restaurant was not receiving it. I tried again, still no luck. I soon figured out that the problem was that my mobile internet was not working well at the time. I had to walk over 50 meters toward the Internet Archive nearby to access its wifi, which finally allowed me to send the transaction.Lesson learned: internet is not 100% reliable, and customer internet is less reliable than merchant internet. We need in-person payment systems to have some functionality (NFC, customer shows a QR code, whatever) to allow customers to transfer their transaction data directly to the merchant if that's the best way to get it broadcasted.In 2021, I attempted to pay for tea for myself and my friends at a coffee shop in Argentina. In their defense, they did not intentionally accept cryptocurrency: the owner simply recognized me, and showed me that he had an account at a cryptocurrency exchange, so I suggested to pay in ETH (using cryptocurrency exchange accounts as wallets is a standard way to do in-person payments in Latin America). Unfortunately, my first transaction of 0.003 ETH did not get accepted, probably because it was under the exchange's 0.01 ETH deposit minimum. I sent another 0.007 ETH. Soon, both got confirmed. (I did not mind the 3x overpayment and treated it as a tip).In 2022, I attempted to pay for tea at a different location. The first transaction failed, because the default transaction from my mobile wallet sent with only 21000 gas, and the receiving account was a contract that required extra gas to process the transfer. Attempts to send a second transaction failed, because a UI glitch in my phone wallet made it not possible to scroll down and edit the field that contained the gas limit.Lesson learned: simple-and-robust UIs are better than fancy-and-sleek ones. But also, most users don't even know what gas limits are, so we really just need to have better defaults.Many times, there has been a surprisingly long time delay between my transaction getting accepted on-chain, and the service acknowledging the transaction, even as "unconfirmed". Some of those times, I definitely got worried that there was some glitch with the payment system on their side.Many times, there has been a surprisingly long and unpredictable time delay between sending a transaction, and that transaction getting accepted in a block. Sometimes, a transaction would get accepted in a few seconds, but other times, it would take minutes or even hours. Recently, EIP-1559 significantly improved this, ensuring that most transactions get accepted into the next block, and even more recently the Merge improved things further by stabilizing block times. Diagram from this report by Yinhong (William) Zhao and Kartik Nayak. However, outliers still remain. If you send a transaction at the same time as when many others are sending transactions and the base fee is spiking up, you risk the base fee going too high and your transaction not getting accepted. Even worse, wallet UIs suck at showing this. There are no big red flashing alerts, and very little clear indication of what you're supposed to do to solve this problem. Even to an expert, who knows that in this case you're supposed to "speed up" the transaction by publishing a new transaction with identical data but a higher max-basefee, it's often not clear where the button to do that actually is.Lesson learned: UX around transaction inclusion needs to be improved, though there are fairly simple fixes. Credit to the Brave wallet team for taking my suggestions on this topic seriously, and first increasing the max-basefee tolerance from 12.5% to 33%, and more recently exploring ways to make stuck transactions more obvious in the UI.In 2019, I was testing out one of the earliest wallets that was attempting to provide social recovery. Unlike my preferred approach, which is smart-contract-based, their approach was to use Shamir's secret sharing to split up the private key to the account into five pieces, in such a way that any three of those pieces could be used to recover the private key. Users were expected to choose five friends ("guardians" in modern lingo), convince them to download a separate mobile application, and provide a confirmation code that would be used to create an encrypted connection from the user's wallet to the friend's application through Firebase and send them their share of the key.This approach quickly ran into problems for me. A few months later, something happened to my wallet and I needed to actually use the recovery procedure to recover it. I asked my friends to perform the recovery procedure with me through their apps - but it did not go as planned. Two of them lost their key shards, because they switched phones and forgot to move the recovery application over. For a third, the Firebase connection mechanism did not work for a long time. Eventually, we figured out how to fix the issue, and recover the key. A few months after that, however, the wallet broke again. This time, a regular software update somehow accidentally reset the app's storage and deleted its key. But I had not added enough recovery partners, because the Firebase connection mechanism was too broken and was not letting me successfully do that. I ended up losing a small amount of BTC and ETH.Lesson learned: secret-sharing-based off-chain social recovery is just really fragile and a bad idea unless there are no other options. Your recovery guardians should not have to download a separate application, because if you have an application only for an exceptional situation like recovery, it's too easy to forget about it and lose it. Additionally, requiring separate centralized communication channels comes with all kinds of problems. Instead, the way to add guardians should be to provide their ETH address, and recovery should be done by smart contract, using ERC-4337 account abstraction wallets. This way, the guardians would only need to not lose their Ethereum wallets, which is something that they already care much more about not losing for other reasons.In 2021, I was attempting to save on fees when using Tornado Cash, by using the "self-relay" option. Tornado Cash uses a "relay" mechanism where a third party pushes the transaction on-chain, because when you are withdrawing you generally do not yet have coins in your withdrawal address, and you don't want to pay for the transaction with your deposit address because that creates a public link between the two addresses, which is the whole problem that Tornado Cash is trying to prevent. The problem is that the relay mechanism is often expensive, with relays charging a percentage fee that could go far above the actual gas fee of the transaction.To save costs, one time I used the relay for a first small withdrawal that would charge lower fees, and then used the "self-relay" feature in Tornado Cash to send a second larger withdrawal myself without using relays. The problem is, I screwed up and accidentally did this while logged in to my deposit address, so the deposit address paid the fee instead of the withdrawal address. Oops, I created a public link between the two.Lesson learned: wallet developers should start thinking much more explicitly about privacy. Also, we need better forms of account abstraction to remove the need for centralized or even federated relays, and commoditize the relaying role.Miscellaneous stuffMany apps still do not work with the Brave wallet or the Status browser; this is likely because they didn't do their homework properly and rely on Metamask-specific APIs. Even Gnosis Safe did not work with these wallets for a long time, leading me to have to write my own mini Javascript dapp to make confirmations. Fortunately, the latest UI has fixed this issue. The ERC20 transfers pages on Etherscan (eg. https://etherscan.io/address/0xd8da6bf26964af9d7eed9e03e53415d37aa96045#tokentxns) are very easy to spam with fakes. Anyone can create a new ERC20 token with logic that can issue a log that claims that I or any other specific person sent someone else tokens. This is sometimes used to trick people into thinking that I support some scam token when I actually have never even heard of it. Uniswap used to offer the functionality of being able to swap tokens and have the output sent to a different address. This was really convenient for when I have to pay someone in USDC but I don't have any already on me. Now, the interface doesn't offer that function, and so I have to convert and then send in a separate transaction, which is less convenient and wastes more gas. I have since learned that Cowswap and Paraswap offer the functionality, though Paraswap... currently does not seem to work with the Brave wallet. Sign in with Ethereum is great, but it's still difficult to use if you are trying to sign in on multiple devices, and your Ethereum wallet is only available on one device. ConclusionsGood user experience is not about the average case, it is about the worst case. A UI that is clean and sleek, but does some weird and unexplainable thing 0.723% of the time that causes big problems, is worse than a UI that exposes more gritty details to the user but at least makes it easier to understand what's going on and fix any problem that does arise.Along with the all-important issue of high transaction fees due to scaling not yet being fully solved, user experience is a key reason why many Ethereum users, especially in the Global South, often opt for centralized solutions instead of on-chain decentralized alternatives that keep power in the hands of the user and their friends and family or local community. User experience has made great strides over the years - in particular, going from an average transaction taking minutes to get included before EIP-1559 to an average transaction taking seconds to get included after EIP-1559 and the merge, has been a night-and-day change to how pleasant it is to use Ethereum. But more still needs to be done.
-
An incomplete guide to stealth addresses An incomplete guide to stealth addresses2023 Jan 20 See all posts An incomplete guide to stealth addresses Special thanks to Ben DiFrancesco, Matt Solomon, Toni Wahrstätter and Antonio Sanso for feedback and reviewOne of the largest remaining challenges in the Ethereum ecosystem is privacy. By default, anything that goes onto a public blockchain is public. Increasingly, this means not just money and financial transactions, but also ENS names, POAPs, NFTs, soulbound tokens, and much more. In practice, using the entire suite of Ethereum applications involves making a significant portion of your life public for anyone to see and analyze.Improving this state of affairs is an important problem, and this is widely recognized. So far, however, discussions on improving privacy have largely centered around one specific use case: privacy-preserving transfers (and usually self-transfers) of ETH and mainstream ERC20 tokens. This post will describe the mechanics and use cases of a different category of tool that could improve the state of privacy on Ethereum in a number of other contexts: stealth addresses.What is a stealth address system?Suppose that Alice wants to send Bob an asset. This could be some quantity of cryptocurrency (eg. 1 ETH, 500 RAI), or it could be an NFT. When Bob receives the asset, he does not want the entire world to know that it was he who got it. Hiding the fact that a transfer happened is impossible, especially if it's an NFT of which there is only one copy on-chain, but hiding who is the recipient may be much more viable. Alice and Bob are also lazy: they want a system where the payment workflow is exactly the same as it is today. Bob sends Alice (or registers on ENS) some kind of "address" encoding how someone can pay him, and that information alone is enough for Alice (or anyone else) to send him the asset.Note that this is a different kind of privacy than what is provided by eg. Tornado Cash. Tornado Cash can hide transfers of mainstream fungible assets such as ETH or major ERC20s (though it's most easily useful for privately sending to yourself), but it's very weak at adding privacy to transfers of obscure ERC20s, and it cannot add privacy to NFT transfers at all. The ordinary workflow of making a payment with cryptocurrency. We want to add privacy (no one can tell that it was Bob who received the asset), but keep the workflow the same. Stealth addresses provide such a scheme. A stealth address is an address that can be generated by either Alice or Bob, but which can only be controlled by Bob. Bob generates and keeps secret a spending key, and uses this key to generate a stealth meta-address. He passes this meta-address to Alice (or registers it on ENS). Alice can perform a computation on this meta-address to generate a stealth address belonging to Bob. She can then send any assets she wants to send to this address, and Bob will have full control over them. Along with the transfer, she publishes some extra cryptographic data (an ephemeral pubkey) on-chain that helps Bob discover that this address belongs to him.Another way to look at it is: stealth addresses give the same privacy properties as Bob generating a fresh address for each transaction, but without requiring any interaction from Bob.The full workflow of a stealth address scheme can be viewed as follows:Bob generates his root spending key (m) and stealth meta-address (M). Bob adds an ENS record to register M as the stealth meta-address for bob.eth. We assume Alice knows that Bob is bob.eth. Alice looks up his stealth meta-address M on ENS. Alice generates an ephemeral key that only she knows, and that she only uses once (to generate this specific stealth address). Alice uses an algorithm that combines her ephemeral key and Bob's meta-address to generate a stealth address. She can now send assets to this address. Alice also generates her ephemeral public key, and publishes it to the ephemeral public key registry (this can be done in the same transaction as the first transaction sending assets to this stealth address). For Bob to discover stealth addresses belonging to him, Bob needs to scan the ephemeral public key registry for the entire list of ephemeral public keys published by anyone for any reason since the last time he did the scan. For each ephemeral public key, Bob attempts to combine it with his root spending key to generate a stealth address, and checks if there are any assets in that address. If there are, Bob computes the spending key for that address and remembers it. This all relies on two uses of cryptographic trickery. First, we need a pair of algorithms to generate a shared secret: one algorithm which uses Alice's secret thing (her ephemeral key) and Bob's public thing (his meta-address), and another algorithm which uses Bob's secret thing (his root spending key) and Alice's public thing (her ephemeral public key). This can be done in many ways; Diffie-Hellman key exchange was one of the results that founded the field of modern cryptography, and it accomplishes exactly this.But a shared secret by itself is not enough: if we just generate a private key from the shared secret, then Alice and Bob could both spend from this address. We could leave it at that, leaving it up to Bob to move the funds to a new address, but this is inefficient and needlessly reduces security. So we also add a key blinding mechanism: a pair of algorithms where Bob can combine the shared secret with his root spending key, and Alice can combine the shared secret with Bob's meta-address, in such a way that Alice can generate the stealth address, and Bob can generate the spending key for that stealth address, all without creating a public link between the stealth address and Bob's meta-address (or between one stealth address and another).Stealth addresses with elliptic curve cryptographyStealth addresses using elliptic curve cryptography were originally introduced in the context of Bitcoin by Peter Todd in 2014. This technique works as follows (this assumes prior knowledge of basic elliptic curve cryptography; see here, here and here for some tutorials):Bob generates a key m, and computes M = G * m, where G is a commonly-agreed generator point for the elliptic curve. The stealth meta-address is an encoding of M. Alice generates an ephemeral key r, and publishes the ephemeral public key R = G * r. Alice can compute a shared secret S = M * r, and Bob can compute the same shared secret S = m * R. In general, in both Bitcoin and Ethereum (including correctly-designed ERC-4337 accounts), an address is a hash containing the public key used to verify transactions from that address. So you can compute the address if you compute the public key. To compute the public key, Alice or Bob can compute P = M + G * hash(S) To compute the private key for that address, Bob (and Bob alone) can compute p = m + hash(S) This satisfies all of our requirements above, and is remarkably simple!There is even an EIP trying to define a stealth address standard for Ethereum today, that both supports this approach and gives space for users to develop other approaches (eg. that support Bob having separate spending and viewing keys, or that use different cryptography for quantum-resistant security). Now you might think: stealth addresses are not too difficult, the theory is already solid, and getting them adopted is just an implementation detail. The problem is, however, that there are some pretty big implementation details that a truly effective implementation would need to get through.Stealth addresses and paying transaction feesSuppose that someone sends you an NFT. Mindful of your privacy, they send it to a stealth address that you control. After scanning the ephem pubkeys on-chain, your wallet automatically discovers this address. You can now freely prove ownership of the NFT or transfer it to someone else. But there's a problem! That account has 0 ETH in it, and so there is no way to pay transaction fees. Even ERC-4337 token paymasters won't work, because those only work for fungible ERC20 tokens. And you can't send ETH into it from your main wallet, because then you're creating a publicly visible link. Inserting memes of 2017-era (or older) crypto scams is an important technique that writers can use to signal erudition and respectableness, because it shows that they have been around for a long time and have refined tastes, and are not easily swayed by current-thing scam figures like SBF. There is one "easy" way to solve the problem: just use ZK-SNARKs to transfer funds to pay for the fees! But this costs a lot of gas, an extra hundreds of thousands of gas just for a single transfer.Another clever approach involves trusting specialized transaction aggregators ("searchers" in MEV lingo). These aggregators would allow users to pay once to purchase a set of "tickets" that can be used to pay for transactions on-chain. When a user needs to spend an NFT in a stealth address that contains nothing else, they provide the aggregator with one of the tickets, encoded using a Chaumian blinding scheme. This is the original protocol that was used in centralized privacy-preserving e-cash schemes that were proposed in the 1980s and 1990s. The searcher accepts the ticket, and repeatedly includes the transaction in their bundle for free until the transaction is successfully accepted in a block. Because the quantity of funds involved is low, and it can only be used to pay for transaction fees, trust and regulatory issues are much lower than a "full" implementation of this kind of centralized privacy-preserving e-cash.Stealth addresses and separating spending and viewing keysSuppose that instead of Bob just having a single master "root spending key" that can do everything, Bob wants to have a separate root spending key and viewing key. The viewing key can see all of Bob's stealth addresses, but cannot spend from them.In the elliptic curve world, this can be solved using a very simple cryptographic trick:Bob's meta-address M is now of the form (K, V), encoding G * k and G * v, where k is the spending key and v is the viewing key. The shared secret is now S = V * r = v * R, where r is still Alice's ephemeral key and R is still the ephemeral public key that Alice publishes. The stealth address's public key is P = K + G * hash(S) and the private key is p = k + hash(S). Notice that the first clever cryptographic step (generating the shared secret) uses the viewing key, and the second clever cryptographic step (Alice and Bob's parallel algorithms to generate the stealth address and its private key) uses the root spending key.This has many use cases. For example, if Bob wants to receive POAPs, then Bob could give his POAP wallet (or even a not-very-secure web interface) his viewing key to scan the chain and see all of his POAPs, without giving this interface the power to spend those POAPs.Stealth addresses and easier scanningTo make it easier to scan the total set of ephemeral public keys, one technique is to add a view tag to each ephemeral public key. One way to do this in the above mechanism is to make the view tag be one byte of the shared secret (eg. the x-coordinate of S modulo 256, or the first byte of hash(S)).This way, Bob only needs to do a single elliptic curve multiplication for each ephemeral public key to compute the shared secret, and only 1/256 of the time would Bob need to do more complex calculation to generate and check the full address.Stealth addresses and quantum-resistant securityThe above scheme depends on elliptic curves, which are great but are unfortunately vulnerable to quantum computers. If quantum computers become an issue, we would need to switch to quantum-resistant algorithms. There are two natural candidates for this: elliptic curve isogenies and lattices.Elliptic curve isogenies are a very different mathematical construction based on elliptic curves, that has the linearity properties that let us do similar cryptographic tricks to what we did above, but cleverly avoids constructing cyclic groups that might be vulnerable to discrete logarithm attacks with quantum computers.The main weakness of isogeny-based cryptography is its highly complicated underlying mathematics, and the risk that possible attacks are hidden under this complexity. Some isogeny-based protocols were broken last year, though others remain safe. The main strength of isogenies is the relatively small key sizes, and the ability to port over many kinds of elliptic curve-based approaches directly. A 3-isogeny in CSIDH, source here. Lattices are a very different cryptographic construction that relies on far simpler mathematics than elliptic curve isogenies, and is capable of some very powerful things (eg. fully homomorphic encryption). Stealth address schemes could be built on lattices, though designing the best one is an open problem. However, lattice-based constructions tend to have much larger key sizes. Fully homomorphic encryption, an application of lattices. FHE could also be used to help stealth address protocols in a different way: to help Bob outsource the computation of checking the entire chain for stealth addresses containing assets without revealing his view key. A third approach is to construct a stealth address scheme from generic black-box primitives: basic ingredients that lots of people need for other reasons. The shared secret generation part of the scheme maps directly to key exchange, a, errr... important component in public key encryption systems. The harder part is the parallel algorithms that let Alice generate only the stealth address (and not the spending key) and let Bob generate the spending key.Unfortunately, you cannot build stealth addresses out of ingredients that are simpler than what is required to build a public-key encryption system. There is a simple proof of this: you can build a public-key encryption system out of a stealth address scheme. If Alice wants to encrypt a message to Bob, she can send N transactions, each transaction going to either a stealth address belonging to Bob or to a stealth address belonging to herself, and Bob can see which transactions he received to read the message. This is important because there are mathematical proofs that you can't do public key encryption with just hashes, whereas you can do zero-knowledge proofs with just hashes - hence, stealth addresses cannot be done with just hashes.Here is one approach that does use relatively simple ingredients: zero knowledge proofs, which can be made out of hashes, and (key-hiding) public key encryption. Bob's meta-address is a public encryption key plus a hash h = hash(x), and his spending key is the corresponding decryption key plus x. To create a stealth address, Alice generates a value c, and publishes as her ephemeral pubkey an encryption of c readable by Bob. The address itself is an ERC-4337 account whose code verifies transactions by requiring them to come with a zero-knowledge proof proving ownership of values x and c such that k = hash(hash(x), c) (where k is part of the account's code). Knowing x and c, Bob can reconstruct the address and its code himself. The encryption of c tells no one other than Bob anything, and k is a hash, so it reveals almost nothing about c. The wallet code itself only contains k, and c being private means that k cannot be traced back to h.However, this requires a STARK, and STARKs are big. Ultimately, I think it is likely that a post-quantum Ethereum world will involve many applications using many starks, and so I would advocate for an aggregation protocol like that described here to combine all of these STARKs into a single recursive STARK to save space.Stealth addresses and social recovery and multi-L2 walletsI have for a long time been a fan of social recovery wallets: wallets that have a multisig mechanism with keys shared between some combination of institutions, your other devices and your friends, where some supermajority of those keys can recover access to your account if you lose your primary key.However, social recovery wallets do not mix nicely with stealth addresses: if you have to recover your account (meaning, change which private key controls it), you would also have to perform some step to change the account verification logic of your N stealth wallets, and this would require N transactions, at a high cost to fees, convenience and privacy.A similar concern exists with the interaction of social recovery and a world of multiple layer-2 protocols: if you have an account on Optimism, and on Arbitrum, and on Starknet, and on Scroll, and on Polygon, and possibly some of these rollups have a dozen parallel instances for scaling reasons and you have an account on each of those, then changing keys may be a really complex operation. Changing the keys to many accounts across many chains is a huge effort. One approach is to bite the bullet and accept that recoveries are rare and it's okay for them to be costly and painful. Perhaps you might have some automated software transfer the assets out into new stealth addresses at random intervals over a two-week time span to reduce the effectiveness of time-based linking. But this is far from perfect. Another approach is to secret-share the root key between the guardians instead of using smart contract recovery. However, this removes the ability to de-activate a guardian's power to help recover your account, and so is long-run risky.A more sophisticated approach involves zero-knowledge proofs. Consider the ZKP-based scheme above, but modifying the logic as follows. Instead of the account holding k = hash(hash(x), c) directly, the account would hold a (hiding) commitment to the location of k on the chain. Spending from that account would then require providing a zero-knowledge proof that (i) you know the location on the chain that matches that commitment, and (ii) the object in that location contains some value k (which you're not revealing), and that you have some values x and c that satisfy k = hash(hash(x), c).This allows many accounts, even across many layer-2 protocols, to be controlled by a single k value somewhere (on the base chain or on some layer-2), where changing that one value is enough to change the ownership of all your accounts, all without revealing the link between your accounts and each other.ConclusionsBasic stealth addresses can be implemented fairly quickly today, and could be a significant boost to practical user privacy on Ethereum. They do require some work on the wallet side to support them. That said, it is my view that wallets should start moving toward a more natively multi-address model (eg. creating a new address for each application you interact with could be one option) for other privacy-related reasons as well.However, stealth addresses do introduce some longer-term usability concerns, such as difficulty of social recovery. It is probably okay to simply accept these concerns for now, eg. by accepting that social recovery will involve either a loss of privacy or a two-week delay to slowly release the recovery transactions to the various assets (which could be handled by a third-party service). In the longer term, these problems can be solved, but the stealth address ecosystem of the long term is looking like one that would really heavily depend on zero-knowledge proofs.
-
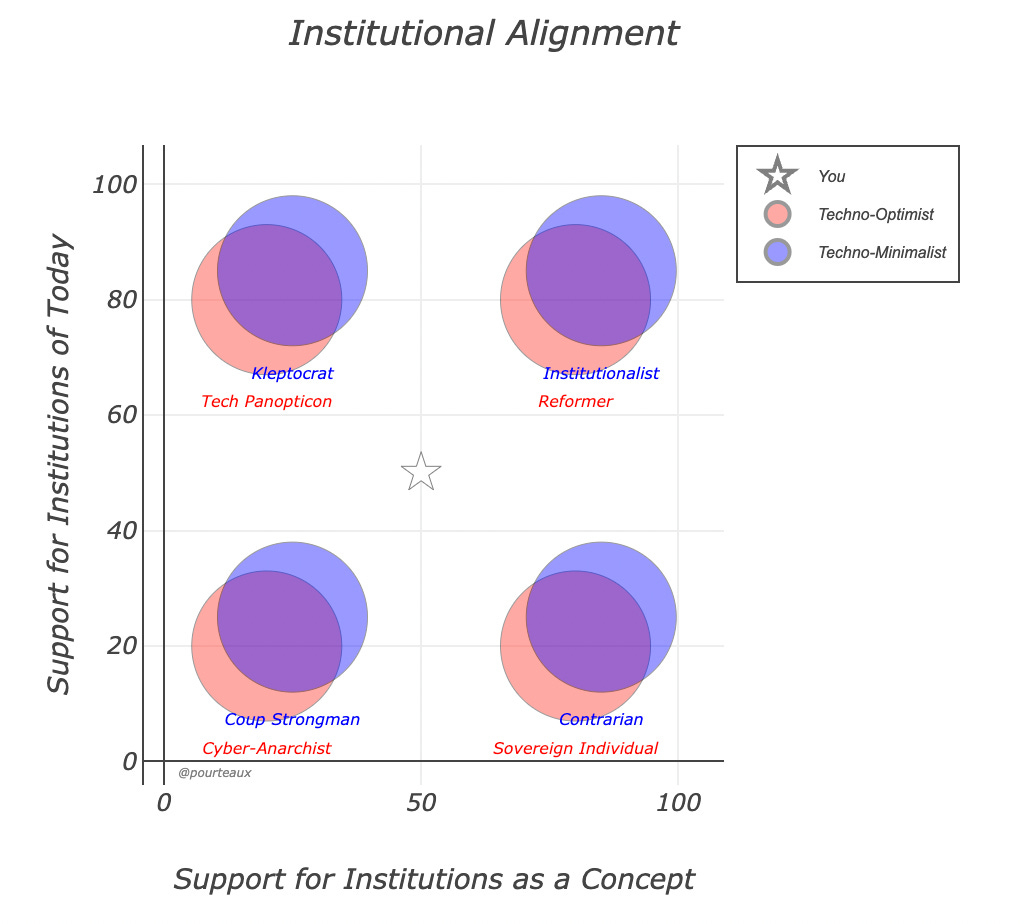
What even is an institution? What even is an institution?2022 Dec 30 See all posts What even is an institution? Special thanks to Dennis Pourteaux and Tina Zhen for discussion that led to this post.A recent alternative political compass proposed by Dennis Pourteaux proposes that the most important political divide of our present time is not liberty vs authoritarianism or left vs right, but rather how we think about "institutions". Are the institutions that society runs on today good or bad, and is the solution to work incrementally to improve them, replace them with radically different institutions, or do away with institutions altogether? This, however, raises a really important question: what even is an "institution" anyway?The word "institution" in political discourse brings to mind things like national governments, the New York Times, universities and maybe the local public library. But the word also gets used to describe other kinds of things. The phrase "the institution of marriage" is common in English-language discourse, and gets over two million search results on Google. If you ask Google point-blank, "is family an institution", it answers yes. ChatGPT agrees: If we take ChatGPT's definition that "a social institution is a pattern of behaviors and norms that exist within a society and are thought to be essential to its functioning" seriously, then the New York Times is not an institution - no one argues that it's literally essential, and many people consider it to be actively harmful! And on the other side, we can think of examples of things that maybe are institutions that Pourteaux's "anti-institutionalists" would approve of!Twitter The Bitcoin or Ethereum blockchains The English language Substack Markets Standards organizations dealing with international shipping This leads us to two related, but also somewhat separate, questions:What is really the dividing line that makes some things "institutions" in people's eyes and others not? What kind of world do people who consider themselves anti-institutionalists actually want to see? And what should an anti-institutionalist in today's world be doing? A survey experimentOver the past week, I made a series of polls on Mastodon where I provided many examples of different objects, practices and social structures, and asked: is this an institution or not? In some cases, I made different spins on the same concept to see the effects of changing some specific variables. There were some fascinating results.Here are a few examples:And:And:And, of course:There's more fun ones: NYT vs Russia Today vs Bitcoin Magazine, the solar system vs what if we started re-engineering it, prediction markets, various social customs, and a lot more.Here, we can already start to see some common factors. Marriage is more institution-y than romantic relationships, likely because of its official stamp of recognition, and more mainstream relationship styles are more institution-y than less mainstream styles (a pattern that repeats itself when comparing NYT vs Russia Today vs Bitcoin Magazine). Systems with clearly visible human beings making decisions are more institution-y than more impersonal algorithmic structures, even if their outputs are ultimately entirely a function of human-provided inputs.To try to elucidate things further, I decided to do a more systematic analysis.What are some common factors?Robin Hanson recently made a post in which he argued that:At least on prestigious topics, most people want relevant institutions to take the following ideal form:Masses recognize elites, who oversee experts, who pick details.This seemed to me to be an important and valuable insight, though in a somewhat different direction: yes, that is the style of institution that people find familiar and are not weirded out by (as they might when they see many of the "alternative institutions" that Hanson likes to propose), but it's also exactly the style of institutions that anti-institutionalists tend to most strongly rail against! Mark Zuckerberg's very institution-y oversight board certainly followed the "masses recognize elites who oversee experts" template fairly well, but it did not really make a lot of people happy.I decided to give this theory of institution-ness, along with some other theories, a test. I identified seven properties that seemed to me possible important characteristics of institutions, with the goal of identifying which ones are most strongly correlated to people thinking of something as being an institution:Does it have a "masses recognize elites" pattern? Does it have a "elites oversee experts" pattern? Is it mainstream? Is it logically centralized? Does it involve interaction between people? (eg. intermittent fasting doesn't, as everyone just chooses whether or not to do it separately, but a government does) Does it have a specific structure that has a lot of intentional design behind it? (eg. corporations do, friendship doesn't) Does it have roles that take on a life independent of the individuals that fill them? (eg. democratically elected governments do, after all they even call the leader "Mr. President", but a podcast which is named after its sole host does not at all) I went through the list and personally graded the 35 maybe-institutions from my polls on these categories. For example, Tesla got:25% on "masses recognize elites" (because it's run by Elon Musk, who does in practice have a lot of recognition and support as a celebrity, but this isn't a deeply intrinsic feature of Tesla, Elon won't get kicked out of Tesla if he loses legitimacy, etc) 100% on "elites oversee experts" (all large corporations follow this pattern) 75% on "is mainstream" (almost everyone knows about it, lots of people have them, but it's not quite a New York Times-level household name) 100% on "logical centralization" (most things get 100% on this score; as a counterexample, "dating sites" get 50% because there are many dating sites and "intermittent fasting" gets 0%) 100% on "involves interaction between people" (Tesla produces products that it sells to people, and it hires employees, has investors, etc) 75% on "intentional structure" (Tesla definitely has a deep structure with shareholders, directors, management, etc, but that structure isn't really part of its identity in the way that, say, proof of stake consensus is for Ethereum or voting and congress are for a government) 50% for "roles independent of individuals" (while roles in companies are generally interchangeable, Tesla does get large gains from being part of the Elon-verse specifically) The full data is here. I know that many people will have many disagreements over various individual rankings I make, and readers could probably convince me that a few of my scores are wrong; I am mainly hoping that I've included a sufficient number of diverse maybe-instiutions in the list that individual disagreement or errors get roughly averaged out.Here's the table of correlations:Masses recognize elites 0.491442156943094 Elites oversee experts 0.697483431580409 Is mainstream 0.477135770662517 Logical centralization 0.406758324754985 Interaction between people 0.570201749796132 Intelligently designed structure 0.365640100778201 Roles independent of individuals 0.199412937985826 But as it turns out, the correlations are misleading. "Interaction between people" turns out to be an almost unquestionably necessary property for something to have to be an institution. The correlation of 0.57 kind of shows it, but it understates the strength of the relationship: Literally every thing that I labeled as clearly involving interaction had a higher percentage of people considering it an institution than every thing I labeled as not involving interaction. The single dot in the center is my hypothetical example of an island where people with odd-numbered birthdays are not allowed to eat meat before 12:00; I didn't want to give it 100% because the not-meat-eating is a private activity, but the question still strongly implies some social or other pressure to follow the rule so it's also not really 0%. This is a place where Spearman's coefficient outperforms Pearson's, but rather than spurting out exotic numbers I'd rather just show the charts. Here are the other six:The most surprising finding for me is that "roles independent of individuals" is by far the weakest correlation. Twitter run by a democracy is the most institution-y of all, but Twitter run by a pay-to-govern scheme is as institution-y as Twitter that's just run by Elon directly. Roles being independent of individuals adds a guarantee of stability, but roles being independent of individuals in the wrong way feels too unfamiliar, or casual, or otherwise not institution-like. Dating sites are more independent of individuals than professional matchmaking agencies, and yet it's the matchmaking agencies that are seen as more institution-like. Attempts at highly role-driven and mechanistic credibly-neutral media, (eg. this contraption, which I actually think would be really cool) just feel alien - perhaps in a bad way, but also perhaps in a good way, if you find the institutions of today frustrating and you're open-minded about possible alternatives.Correlations with "masses recognize elites" and "elites oversee experts" were high; higher for the second than the first, though perhaps Hanson and I had different meanings in mind for "recognize". The "intentional structure" chart has an empty bottom-right corner but a full top-left corner, suggesting that intentional structure is necessary but not sufficient for something to be an institution.That said, my main conclusion is probably that the term "institution" is a big mess. Rather than the term "institution" referring to a single coherent cluster of concepts (as eg. "high modernism" does), the term seems to have a number of different definitions at play:A structure that fits the familiar pattern of "masses recognize elites who oversee experts" Any intentionally designed large-scale structure that mediates human interaction (including things like financial markets, social media platforms and dating sites) Widely spread and standardized social customs in general I suspect that anti-institutionalists focus their suspicion on (1), and especially instances of (1) that have been captured by the wrong tribe. Whether a structure is personalistic or role-driven does not seem to be very important to anti-institutionalists: both personalities ("Klaus Schwab") and bureaucracies ("woke academics") are equally capable of coming from the wrong tribe. Anti-institutionalists generally do not oppose (3), and indeed in many cases want to see (3) replace (1) as much as possible.Support for (2) probably maps closely to Pourteaux's "techno-optimist" vs "techno-minimalist" distinction. Techno-minimalists don't see things like Twitter, Substack, Bitcoin, Ethereum, etc as part of the solution, though there are "Bitcoin minimalists" who see the Bitcoin blockchain as a narrow exception and otherwise want to see a world where things like family decide more of the outcomes. "Techno-optimist anti-institutionalists" are specifically engaged in a political project of either trying to replace (1) with the right kind of (2), or trying to reform (1) by introducing more elements of the right kind of (2).Which way forward for anti-institutionalists or institutional reformers?It would be wrong to ascribe too much intentional strategy to anti-institutionalists: anti-institutionalism is a movement that is much more united in what is against than in support of any specific particular alternative. But what is possible is to recognize this pattern, and ask the question of which paths forward make sense for anti-institutionalists.From a language point of view, even using the word "institution" at all seems more likely to confuse than enlighten at this point. There is a crucial difference between (i) a desire to replace structures that contain enshrined elite roles with structures that don't, (ii) a preference for small-scale and informal structures over large-scale and formal ones, (iii) a desire to simply swap the current elites out for new elites, and (iv) a kind of social libertinist position that individuals should be driven by their own whims and not by incentives created by other people. The word "institution" obscures that divide, and probably focuses too much attention on what is being torn down rather than what is to be built up in its place. Different anti-institutionalists have different goals in mind. Sure, the person on Twitter delivering that powerful incisive criticism of the New York Times agrees with you on how society should not be run, but are you sure they'll be your ally when it comes time to decide how society should be run? The challenge with avoiding structures entirely is clear: prisoner's dilemmas exist and we need incentives. The challenge with small-scale and informal structures is often clear: economies of scale and gains from standardization - though sometimes there are other benefits from informal approaches that are worth losing those gains. The challenge with simply swapping the elites is clear: it has no path to socially scale into a cross-tribal consensus. If the goal is not to enshrine a new set of elites forever, but for elites to permanently be high-churn (cf. Balaji's founder vs inheritor dichotomy), that is more credibly neutral, but then it starts getting closer to the territory of avoiding enshrined elites in general.Creating formal structures without enshrined elites is fascinating, not least because it's under-explored: there's a strong case that institutions with enshrined elite roles might be an unfortunate historical necessity from when communication was more constrained, but modern information technology (including the internet and also newer spookier stuff like zero-knowledge cryptography, blockchains and DAOs) could rapidly expand our available options. That said, as Hanson points out, this path has its own fair share of challenges too.
-
Updating my blog: a quick GPT chatbot coding experiment Updating my blog: a quick GPT chatbot coding experiment2022 Dec 06 See all posts Updating my blog: a quick GPT chatbot coding experiment The GPT chatbot has been all the rage the last few days. Along with many important use cases like writing song lyrics, acting as a language learning buddy and coming up with convincing-sounding arguments for arbitrary political opinions, one of the things that many people are excited about is the possibility of using the chatbot to write code.In a lot of cases, it can succeed and write some pretty good code especially for common tasks. In cases that cover less well-trodden ground, however, it can fail: witness its hilariously broken attempt to write a PLONK verifier: (In case you want to know how to do it kinda-properly, here is a PLONK verifier written by me)But how well do these tools actually perform in the average case? I decided to take the GPT3 chatbot for a spin, and see if I could get it to solve a problem very relevant to me personally: changing the IPFS hash registered in my vitalik.eth ENS record, in order to make the new article that I just released on my blog viewable through ENS.The process of updating the ENS view of my blog normally consists of two steps: first, publish the updated contents to IPFS, and second, update my ENS record to contain the IPFS hash of the new contents. Fleek has automated the first part of this for me for a long time: I just push the contents to Github, and Fleek uploads the new version to IPFS automatically. I have been told that I could change the settings to give Fleek the power to also edit my ENS, but here I want to be fully "self-sovereign" and not trust third parties, so I have not done this. Instead, so far, I have had to go to the GUI at app.ens.domains, click a few times, wait for a few loading screens to pass, and finally click "ADD / EDIT RECORD", change the CONTENT hash and click "Confirm". This is all a cumbersome process, and so today I finally thought that I would write a script in javascript to automate this all down to a single piece of Javascript that I could just copy-paste into my browser console in the future.The task is simple: send an Ethereum transaction to the right address with the right calldata to update the content hash record in the ENS contract to equal the IPFS hash that Fleek gives to me. Yesterday, I did this all manually (twice, once to publish and again to add some corrections), and the IPFS hashes I got were:bafybeifvvseiarzdfoqadphxtfu5yjfgj3cr6x344qce4s4f7wqyf3zv4ebafybeieg6fhbjlhkzhbyfnmyid3ko5ogxp3mykdarsfyw66lmq6lq5z73mIf you click through to the top article in each one, you'll see the two different versions.This hash format is often called a "bafyhash", because the hashes all begin with "bafy". But there is a problem: the format of the hash that is saved in Ethereum is not a bafyhash. Here's the calldata of the transaction that made one of the update operations: Yes, I checked, that is not hexadecimalized ASCII. I do know that the IPFS content hash is the last two rows of the data. How do I know? Well, I checked the two different transactions I sent for my two updates, and I saw that the top row is the same and the bottom two rows are different. Good enough.So what do I do to convert from a bafyhash into a binary IPFS content hash? Well, let me try asking the GPT3 chatbot! Noooo!!!!!!!!!! Many issues. First, two things that are my fault:I forgot to mention this, but I wanted Javascript, not python. It uses external dependencies. I want my javascript copy-pasteable into the console, so I don't want any libraries. These are on me to specify, though, and in my next instruction to the chatbot I will. But now we get to the things that are its fault:Bafyhashes are base 32, not base 58. There is a base-58 format for IPFS hashes, but those are called "QM hashes", not "bafyhashes". By "binary" I didn't want literal ones and zeroes, I wanted the normal binary format, a bytes or bytearray. That said, at this part of the story I did not even realize that bafyhashes are base 32. I fixed the two issues that were my fault first: BAAAAAAAAAAAAAD, the AI trainer said sheepishly! The atob function is for base 64, not base 58.OK, let's keep going. A few rounds later... It's hard to see what's going on at first, but it's incredibly wrong. Basically, instead of converting the whole string from base 58 to base 16, it's converting each individual digit to base 16. Not what I want to do!Guess I'll have to tell it what strategy it should use: Better! I soon start to realize that I don't need base 58, I need base 32, and furthermore I need the lowercase version of base 32. I also want the code wrapped in a function. For these simpler steps, it gets much more cooperative: At this point, I try actually passing the bafyhashes I have into this function, and I get unrecognizably different outputs. Looks like I can't just assume this is generic base 32, and I have to poke into the details. Hmm, can I perhaps ask the GPT3 chatbot? OK, this is not helpful. Let me try to be more specific. This is an.... interesting guess, but it's totally wrong. After this point, I give up on the GPT3 for a while, and keep poking at the generated hex and the actual hex in python until I find similarities. Eventually, I figure it out: I actually do convert both hexes to literal binary, and search from a binary substring of one in the other. I discover that there is an offset of 2 bits.I just edit the code manually, compensating for the offset by dividing the bigint by 4: Because I already know what to do, I also just code the part that generates the entire calldata myself: Anyway, then I switch to the next task: the portion of the Javascript that actually sends a transaction. I go back to the GPT3. NOOOOO! I SAID NO LIBRARIES!!!!1!1!I tell it what to use directly: This is more successful. Two errors though:A from address actually is required. You can't stick an integer into the gas field, you need a hex value. Also, post EIP-1559, there really isn't much point in hard-coding a gasPrice. From here, I do the rest of the work myself. function bafyToHex(bafyString) { // Create a lookup table for the base32 alphabet var alphabet = 'abcdefghijklmnopqrstuvwxyz234567'; var base = alphabet.length; var lookupTable = ; alphabet.split('').forEach(function(char, i) { lookupTable[char] = i; }); // Decode the base32-encoded string into a big integer var bigInt = bafyString.split('').reduce(function(acc, curr) { return acc * BigInt(base) + BigInt(lookupTable[curr]); }, BigInt(0)) / BigInt(4); // Convert the big integer into a hexadecimal string var hexString = bigInt.toString(16); return 'e30101701220' + hexString.slice(-64); } function bafyToCalldata(bafyString) { return ( '0x304e6ade' + 'ee6c4522aab0003e8d14cd40a6af439055fd2577951148c14b6cea9a53475835' + '0000000000000000000000000000000000000000000000000000000000000040' + '0000000000000000000000000000000000000000000000000000000000000026' + bafyToHex(bafyString) + '0000000000000000000000000000000000000000000000000000' ) } async function setBafyhash(bafyString) { calldata = bafyToCalldata(bafyString); const addr = (await window.ethereum.enable())[0]; // Set the "to" address for the transaction const to = '0x4976fb03c32e5b8cfe2b6ccb31c09ba78ebaba41'; // Set the transaction options const options = { from: addr, to: to, data: calldata, gas: "0x040000" }; console.log(options); // Send the transaction window.ethereum.send('eth_sendTransaction', [options], function(error, result) { if (error) { console.error(error); } else { console.log(result); } }); } I ask the GPT-3 some minor questions: how to declare an async function, and what keyword to use in Twitter search to search only tweets that contain images (needed to write this post). It answers both flawlessly: do async function functionName to declare an async function, and use filter:images to filter for tweets that contain images.ConclusionsThe GPT-3 chatbot was helpful as a programming aid, but it also made plenty of mistakes. Ultimately, I was able to get past its mistakes quickly because I had lots of domain knowledge:I know that it was unlikely that browsers would have a builtin for base 58, which is a relatively niche format mostly used in the crypto world, and so I immediately got suspicious of its attempt to suggest atob I could eventually recall that the hash being all-lowercase means it's base 32 and not base 58 I knew that the data in the Ethereum transaction had to encode the IPFS hash in some sensible way, which led me to eventually come up with the idea of checking bit offsets I know that a simple "correct" way to convert between base A and base B is to go through some abstract integer representation as an in-between, and that Javascript supported big integers. I knew about window.ethereum.send When I got the error that I was not allowed to put an integer into the gas field, I knew immediately that it was supposed to be hex. At this point, AI is quite far from being a substitute for human programmers. In this particular case, it only sped me up by a little bit: I could have figured things out with Google eventually, and indeed in one or two places I did go back to googling. That said, it did introduce me to some coding patterns I had not seen before, and it wrote the base converter faster than I would have on my own. For the boilerplate operation of writing the Javascript to send a simple transaction, it did quite well.That said, AI is improving quickly and I expect it to keep improving further and ironing out bugs like this over time.Addendum: while writing the part of this post that involved more copy-paste than thinking, I put on my music playlist on shuffle. The first song that started playing was, coincidentally, Basshunter's Boten Anna ("Anna The Bot").
-
What in the Ethereum application ecosystem excites me What in the Ethereum application ecosystem excites me2022 Dec 05 See all posts What in the Ethereum application ecosystem excites me Special thanks to Matt Huang, Santi Siri and Tina Zhen for feedback and reviewTen, five, or even two years ago, my opinions on what Ethereum and blockchains can do for the world were very abstract. "This is a general-purpose technology, like C++", I would say; of course, it has specific properties like decentralization, openness and censorship resistance, but beyond that it's just too early to say which specific applications are going to make the most sense.Today's world is no longer that world. Today, enough time has passed that there are few ideas that are completely unexplored: if something succeeds, it will probably be some version of something that has already been discussed in blogs and forums and conferences on multiple occasions. We've also come closer to identifying fundamental limits of the space. Many DAOs have had a fair chance with an enthusiastic audience willing to participate in them despite the inconveniences and fees, and many have underperformed. Industrial supply-chain applications have not gone anywhere. Decentralized Amazon on the blockchain has not happened. But it's also a world where we have seen genuine and growing adoption of a few key applications that are meeting people's real needs - and those are the applications that we need to focus on.Hence my change in perspective: my excitement about Ethereum is now no longer based in the potential for undiscovered unknowns, but rather in a few specific categories of applications that are proving themselves already, and are only getting stronger. What are these applications, and which applications am I no longer optimistic about? That is what this post will be about.1. Money: the first and still most important appWhen I first visited Argentina in December last year, one of the experiences I remember well was walking around on Christmas Day, when almost everything is closed, looking for a coffee shop. After passing by about five closed ones, we finally found one that was open. When we walked in, the owner recognized me, and immediately showed me that he has ETH and other crypto-assets on his Binance account. We ordered tea and snacks, and we asked if we could pay in ETH. The coffee shop owner obliged, and showed me the QR code for his Binance deposit address, to which I sent about $20 of ETH from my Status wallet on my phone.This was far from the most meaningful use of cryptocurrency that is taking place in the country. Others are using it to save money, transfer money internationally, make payments for large and important transactions, and much more. But even still, the fact that I randomly found a coffee shop and it happened to accept cryptocurrency showed the sheer reach of adoption. Unlike wealthy countries like the United States, where financial transactions are easy to make and 8% inflation is considered extreme, in Argentina and many other countries around the world, links to global financial systems are more limited and extreme inflation is a reality every day. Cryptocurrency often steps in as a lifeline. In addition to Binance, there is also an increasing number of local exchanges, and you can see advertisements for them everywhere including at airports. The one issue with my coffee transaction is that it did not really make pragmatic sense. The fee was high, about a third of the value of the transaction. The transaction took several minutes to confirm: I believe that at the time, Status did not yet support sending proper EIP-1559 transactions that more reliably confirm quickly. If, like many other Argentinian crypto users, I had simply had a Binance wallet, the transfer would have been free and instant.A year later, however, the calculus is different. As a side effect of the Merge, transactions get included significantly more quickly and the chain has become more stable, making it safer to accept transactions after fewer confirmations. Scaling technology such as optimistic and ZK rollups is proceeding quickly. Social recovery and multisig wallets are becoming more practical with account abstraction. These trends will take years to play out as the technology develops, but progress is already being made. At the same time, there is an important "push factor" driving interest in transacting on-chain: the FTX collapse, which has reminded everyone, Latin Americans included, that even the most trustworthy-seeming centralized services may not be trustworthy after all.Cryptocurrency in wealthy countriesIn wealthy countries, the more extreme use cases around surviving high inflation and doing basic financial activities at all usually do not apply. But cryptocurrency still has significant value. As someone who has used it to make donations (to quite normal organizations in many countries), I can personally confirm that it is far more convenient than traditional banking. It's also valuable for industries and activities at risk of being deplatformed by payment processors - a category which includes many industries that are perfectly legal under most countries' laws.There is also the important broader philosophical case for cryptocurrency as private money: the transition to a "cashless society" is being taken advantage of by many governments as an opportunity to introduce levels of financial surveillance that would be unimaginable 100 years ago. Cryptocurrency is the only thing currently being developed that can realistically combine the benefits of digitalization with cash-like respect for personal privacy.But in either case, cryptocurrency is far from perfect. Even with all the technical, user experience and account safety problems solved, it remains a fact that cryptocurrency is volatile, and the volatility can make it difficult to use for savings and business. For that reason, we have...StablecoinsThe value of stablecoins has been understood in the Ethereum community for a long time. Quoting a blog post from 2014:Over the past eleven months, Bitcoin holders have lost about 67% of their wealth and quite often the price moves up or down by as much as 25% in a single week. Seeing this concern, there is a growing interest in a simple question: can we get the best of both worlds? Can we have the full decentralization that a cryptographic payment network offers, but at the same time have a higher level of price stability, without such extreme upward and downward swings?And indeed, stablecoins are very popular among precisely those users who are making pragmatic use of cryptocurrency today. That said, there is a reality that is not congenial to cypherpunk values today: the stablecoins that are most successful today are the centralized ones, mostly USDC, USDT and BUSD. Top cryptocurrency market caps, data from CoinGecko, 2022-11-30. Three of the top six are centralized stablecoins. Stablecoins issued on-chain have many convenient properties: they are open for use by anyone, they are resistant to the most large-scale and opaque forms of censorship (the issuer can blacklist and freeze addresses, but such blacklisting is transparent, and there are literal transaction fee costs associated with freezing each address), and they interact well with on-chain infrastructure (accounts, DEXes, etc). But it's not clear how long this state of affairs will last, and so there is a need to keep working on other alternatives.I see the stablecoin design space as basically being split into three different categories: centralized stablecoins, DAO-governed real-world-asset backed stablecoins and governance-minimized crypto-backed stablecoins. Governance Advantages Disadvantages Examples Centralized stablecoins Traditional legal entity • Maximum efficiency• Easy to understand Vulnerable to risks of a single issuer and a single jurisdiction USDC, USDT, BUSD DAO-governed RWA-backed stablecoins DAO deciding on allowed collateral types and maximum per type • Adds resilience by diversifying issuers and jurisdictions• Still somewhat capital efficient Vulnerable to repeated issuer fraud or coordinated takedown DAI Governance-minimized crypto-backed stablecoin Price oracle only • Maximum resilience• No outside dependencies • High collateral requirements• Limited scale• Sometimes needs negative interest rates RAI,LUSD From the user's perspective, the three types are arranged on a tradeoff spectrum between efficiency and resilience. USDC works today, and will almost certainly work tomorrow. But in the longer term, its ongoing stability depends on the macroeconomic and political stability of the United States, a continued US regulatory environment that supports making USDC available to everyone, and the trustworthiness of the issuing organization.RAI, on the other hand, can survive all of these risks, but it has a negative interest rate: at the time of this writing, -6.7%. To make the system stable (so, not be vulnerable to collapse like LUNA), every holder of RAI must be matched by a holder of negative RAI (aka. a "borrower" or "CDP holder") who puts in ETH as collateral. This rate could be improved with more people engaging in arbitrage, holding negative RAI and balancing it out with positive USDC or even interest-bearing bank account deposits, but interest rates on RAI will always be lower than in a functioning banking system, and the possibility of negative rates, and the user experience headaches that they imply, will always be there.The RAI model is ultimately ideal for the more pessimistic lunarpunk world: it avoids all connection to non-crypto financial systems, making it much more difficult to attack. Negative interest rates prevent it from being a convenient proxy for the dollar, but one way to adapt would be to embrace the disconnection: a governance-minimized stablecoin could track some non-currency asset like a global average CPI index, and advertise itself as representing abstract "best-effort price stability". This would also have lower inherent regulatory risk, as such an asset would not be attempting to provide a "digital dollar" (or euro, or...).DAO-governed RWA-backed stablecoins, if they can be made to work well, could be a happy medium. Such stablecoins could combine enough robustness, censorship resistance, scale and economic practicality to satisfy the needs of a large number of real-world crypto users. But making this work requires both real-world legal work to develop robust issuers, and a healthy dose of resilience-oriented DAO governance engineering.In either case, any kind of stablecoin working well would be a boon for many kinds of currency and savings applications that are already concretely useful for millions of people today.2. Defi: keep it simpleDecentralized finance is, in my view, a category that started off honorable but limited, turned into somewhat of an overcapitalized monster that relied on unsustainable forms of yield farming, and is now in the early stages of setting down into a stable medium, improving security and refocusing on a few applications that are particularly valuable. Decentralized stablecoins are, and probably forever will be, the most important defi product, but there are a few others that have an important niche:Prediction markets: these have been a niche but stable pillar of decentralized finance since the launch of Augur in 2015. Since then, they have quietly been growing in adoption. Prediction markets showed their value and their limitations in the 2020 US election, and this year in 2022, both crypto prediction markets like Polymarket and play-money markets like Metaculus are becoming more and more widely used. Prediction markets are valuable as an epistemic tool, and there is a genuine benefit from using cryptocurrency in making these markets more trustworthy and more globally accessible. I expect prediction markets to not make extreme multibillion-dollar splashes, but continue to steadily grow and become more useful over time. Other synthetic assets: the formula behind stablecoins can in principle be replicated to other real-world assets. Interesting natural candidates include major stock indices and real estate. The latter will take longer to get right due to the inherent heterogeneity and complexity of the space, but it could be valuable for precisely the same reasons. The main question is whether or not someone can create the right balance of decentralization and efficiency that gives users access to these assets at reasonable rates of return. Glue layers for efficiently trading between other assets: if there are assets on-chain that people want to use, including ETH, centralized or decentralized stablecoins, more advanced synthetic assets, or whatever else, there will be value in a layer that makes it easy for users to trade between them. Some users may want to hold USDC and pay transaction fees in USDC. Others may hold some assets, but want to be able to instantly convert to pay someone who wants to be paid in another asset. There is also space for using one asset as collateral to take out loans of another asset, though such projects are most likely to succeed and avoid leading to tears if they keep leverage very limited (eg. not more than 2x). 3. The identity ecosystem: ENS, SIWE, PoH, POAPs, SBTs"Identity" is a complicated concept that can mean many things. Some examples include:Basic authentication: simply proving that action A (eg. sending a transaction or logging into a website) was authorized by some agent that has some identifier, such as an ETH address or a public key, without attempting to say anything else about who or what the agent is. Attestations: proving claims about an agent made by other agents ("Bob attests that he knows Alice", "the government of Canada attests that Charlie is a citizen") Names: establishing consensus that a particular human-readable name can be used to refer to a particular agent. Proof of personhood: proving that an agent is human, and guaranteeing that each human can only obtain one identity through the proof of personhood system (this is often done with attestations, so it's not an entirely separate category, but it's a hugely important special case) For a long time, I have been bullish on blockchain identity but bearish on blockchain identity platforms. The use cases mentioned above are really important to many blockchain use cases, and blockchains are valuable for identity applications because of their institution-independent nature and the interoperability benefits that they provide. But what will not work is an attempt to create a centralized platform to achieve all of these tasks from scratch. What more likely will work is an organic approach, with many projects working on specific tasks that are individually valuable, and adding more and more interoperability over time.And this is exactly what has happened since then. The Sign In With Ethereum (SIWE) standard allows users to log into (traditional) websites in much the same way that you can use Google or Facebook accounts to log into websites today. This is actually useful: it allows you to interact with a site without giving Google or Facebook access to your private information or the ability to take over or lock you out of your account. Techniques like social recovery could give users account recovery options in case they forget their password that are much better than what centralized corporations offer today. SIWE is supported by many applications today, including Blockscan chat, the end-to-end-encrypted email and notes service Skiff, and various blockchain-based alternative social media projects.ENS lets users have usernames: I have vitalik.eth. Proof of Humanity and other proof-of-personhood systems let users prove that they are unique humans, which is useful in many applications including airdrops and governance. POAP (the "proof of attendance protocol", pronounced either "pope" or "poe-app" depending on whether you're a brave contrarian or a sheep) is a general-purpose protocol for issuing tokens that represent attestations: have you completed an educational course? Have you attended an event? Have you met a particular person? POAPs could be used both as an ingredient in a proof-of-personhood protocol and as a way to try to determine whether or not someone is a member of a particular community (valuable for governance or airdrops). An NFC card that contains my ENS name, and allows you to receive a POAP verifying that you've met me. I'm not sure I want to create any further incentive for people to bug me really hard to get my POAP, but this seems fun and useful for other people. Each of these applications are useful individually. But what makes them truly powerful is how well they compose with each other. When I log on to Blockscan chat, I sign in with Ethereum. This means that I am immediately visible as vitalik.eth (my ENS name) to anyone I chat with. In the future, to fight spam, Blockscan chat could "verify" accounts by looking at on-chain activity or POAPs. The lowest tier would simply be to verify that the account has sent or been the recipient in at least one on-chain transaction (as that requires paying fees). A higher level of verification could involve checking for balances of specific tokens, ownership of specific POAPs, a proof-of-personhood profile, or a meta-aggregator like Gitcoin Passport.The network effects of these different services combine to create an ecosystem that provides some very powerful options for users and applications. An Ethereum-based Twitter alternative (eg. Farcaster) could use POAPs and other proofs of on-chain activity to create a "verification" feature that does not require conventional KYC, allowing anons to participate. Such platforms could create rooms that are gated to members of a particular community - or hybrid approaches where only community members can speak but anyone can listen. The equivalent of Twitter polls could be limited to particular communities.Equally importantly, there are much more pedestrian applications that are relevant to simply helping people make a living: verification through attestations can make it easier for people to prove that they are trustworthy to get rent, employment or loans.The big future challenge for this ecosystem is privacy. The status quo involves putting large amounts of information on-chain, which is something that is "fine until it's not", and eventually will become unpalatable if not outright risky to more and more people. There are ways to solve this problem by combining on-chain and off-chain information and making heavy use of ZK-SNARKs, but this is something that will actually need to be worked on; projects like Sismo and HeyAnon are an early start. Scaling is also a challenge, but scaling can be solved generically with rollups and perhaps validiums. Privacy cannot, and must be worked on intentionally for each application.4. DAOs"DAO" is a powerful term that captures many of the hopes and dreams that people have put into the crypto space to build more democratic, resilient and efficient forms of governance. It's also an incredibly broad term whose meaning has evolved a lot over the years. Most generally, a DAO is a smart contract that is meant to represent a structure of ownership or control over some asset or process. But this structure could be anything, from the lowly multisig to highly sophisticated multi-chamber governance mechanisms like those proposed for the Optimism Collective. Many of these structures work, and many others cannot, or at least are very mismatched to the goals that they are trying to achieve.There are two questions to answer:What kinds of governance structures make sense, and for what use cases? Does it make sense to implement those structures as a DAO, or through regular incorporation and legal contracts? A particular subtlety is that the word "decentralized" is sometimes used to refer to both: a governance structure is decentralized if its decisions depend on decisions taken from a large group of participants, and an implementation of a governance structure is decentralized if it is built on a decentralized structure like a blockchain and is not dependent on any single nation-state legal system.Decentralization for robustnessOne way to think about the distinction is: decentralized governance structure protects against attackers on the inside, and a decentralized implementation protects against powerful attackers on the outside ("censorship resistance").First, some examples: Higher need for protection from inside Lower need for protection from inside Higher need for protection from outside Stablecoins The Pirate Bay, Sci-Hub Lower need for protection from outside Regulated financial institutions Regular businesses The Pirate Bay and Sci-Hub are important case studies of something that is censorship-resistant, but does not need decentralization. Sci-Hub is largely run by one person, and if some part of Sci-Hub infrastructure gets taken down, she can simply move it somewhere else. The Sci-Hub URL has changed many times over the years. The Pirate Bay is a hybrid: it relies on BitTorrent, which is decentralized, but the Pirate Bay itself is a centralized convenience layer on top.The difference between these two examples and blockchain projects is that they do not attempt to protect their users against the platform itself. If Sci-Hub or The Pirate Bay wanted to harm their users, the worst they could do is either serve bad results or shut down - either of which would only cause minor inconvenience until their users switch to other alternatives that would inevitably pop up in their absence. They could also publish user IP addresses, but even if they did that the total harm to users would still be much lower than, say, stealing all the users' funds.Stablecoins are not like this. Stablecoins are trying to create stable credibly neutral global commercial infrastructure, and this demands both lack of dependence on a single centralized actor on the outside and protection against attackers from the inside. If a stablecoin's governance is poorly designed, an attack on the governance could steal billions of dollars from users.At the time of this writing, MakerDAO has $7.8 billion in collateral, over 17x the market cap of the profit-taking token, MKR. Hence, if governance was up to MKR holders with no safeguards, someone could buy up half the MKR, use that to manipulate the price oracles, and steal a large portion of the collateral for themselves. In fact, this actually happened with a smaller stablecoin! It hasn't happened to MKR yet largely because the MKR holdings are still fairly concentrated, with the majority of the MKR held by a fairly small group that would not be willing to sell because they believe in the project. This is a fine model to get a stablecoin started, but not a good one for the long term. Hence, making decentralized stablecoins work long term requires innovating in decentralized governance that does not have these kinds of flaws.Two possible directions include:Some kind of non-financialized governance, or perhaps a bicameral hybrid where decisions need to be passed not just by token holders but also by some other class of user (eg. the Optimism Citizens' House or stETH holders as in the Lido two-chamber proposal) Intentional friction, making it so that certain kinds of decisions can only take effect after a delay long enough that users can see that something is going wrong and escape the system. There are many subtleties in making governance that effectively optimizes for robustness. If the system's robustness depends on pathways that are only activated in extreme edge cases, the system may even want to intentionally test those pathways once in a while to make sure that they work - much like the once-every-20-years rebuilding of Ise Jingu. This aspect of decentralization for robustness continues to require more careful thought and development.Decentralization for efficiencyDecentralization for efficiency is a different school of thought: decentralized governance structure is valuable because it can incorporate opinions from more diverse voices at different scales, and decentralized implementation is valuable because it can sometimes be more efficient and lower cost than traditional legal-system-based approaches.This implies a different style of decentralization. Governance decentralized for robustness emphasizes having a large number of decision-makers to ensure alignment with a pre-set goal, and intentionally makes pivoting more difficult. Governance decentralized for efficiency preserves the ability to act rapidly and pivot if needed, but tries to move decisions away from the top to avoid the organization becoming a sclerotic bureaucracy. Pod-based governance in Ukraine DAO. This style of governance improves efficiency by maximizing autonomy. Decentralized implementations designed for robustness and decentralized implementations designed for efficiency are in one way similar: they both just involve putting assets into smart contracts. But decentralized implementations designed for efficiency are going to be much simpler: just a basic multisig will generally suffice.It's worth noting that "decentralizing for efficiency" is a weak argument for large-scale projects in the same wealthy country. But it's a stronger argument for very-small-scale projects, highly internationalized projects, and projects located in countries with inefficient institutions and weak rule of law. Many applications of "decentralizing for efficiency" probably could also be done on a central-bank-run chain run by a stable large country; I suspect that both decentralized approaches and centralized approaches are good enough, and it's the path-dependent question of which one becomes viable first that will determine which approach dominates.Decentralization for interoperabilityThis is a fairly boring class of reasons to decentralize, but it's still important: it's easier and more secure for on-chain things to interact with other on-chain things, than with off-chain systems that would inevitably require an (attackable) bridge layer.If a large organization running on direct democracy holds 10,000 ETH in its reserves, that would be a decentralized governance decision, but it would not be a decentralized implementation: in practice, that country would have a few people managing the keys and that storage system could get attacked.There is also a governance angle to this: if a system provides services to other DAOs that are not capable of rapid change, it is better for that system to itself be incapable of rapid change, to avoid "rigidity mismatch" where a system's dependencies break and that system's rigidity renders it unable to adapt to the break.These three "theories of decentralization" can be put into a chart as follows: Why decentralize governance structure Why decentralize implementation Decentralization for robustness Defense against inside threats (eg. SBF) Defense against outside threats, and censorship resistance Decentralization for efficiency Greater efficiency from accepting input from more voices and giving room for autonomy Smart contracts often more convenient than legal systems Decentralization for interoperability To be rigid enough to be safe to use by other rigid systems To more easily interact with other decentralized things Decentralization and fancy new governance mechanismsOver the last few decades, we've seen the development of a number of fancy new governance mechanisms:Quadratic voting Futarchy Liquid democracy Decentralized conversation tools like Pol.is These ideas are an important part of the DAO story, and they can be valuable for both robustness and efficiency. The case for quadratic voting relies on a mathematical argument that it makes the exactly correct tradeoff between giving space for stronger preferences to outcompete weaker but more popular preferences and not weighting stronger preferences (or wealthy actors) too much. But people who have used it have found that it can improve robustness too. Newer ideas, like pairwise matching, intentionally sacrifice mathematically provable optimality for robustness in situations where the mathematical model's assumptions break.These ideas, in addition to more "traditional" centuries-old ideas around multicameral architectures and intentional indirection and delays, are going to be an important part of the story in making DAOs more effective, though they will also find value in improving the efficiency of traditional organizations.Case study: Gitcoin GrantsWe can analyze the different styles of decentralization through an interesting edge-case: Gitcoin Grants. Should Gitcoin Grants be an on-chain DAO, or should it just be a centralized org?Here are some possible arguments for Gitcoin Grants to be a DAO:It holds and deals with cryptocurrency, because most of its users and funders are Ethereum users Secure quadratic funding is best done on-chain (see next section on blockchain voting, and implementation of on-chain QF here), so you reduce security risks if the result of the vote feeds into the system directly It deals with communities all around the world, and so benefits from being credibly neutral and not centered around a single country. It benefits from being able to give its users confidence that it will still be around in five years, so that public goods funders can start projects now and hope to be rewarded later. These arguments lean toward decentralization for robustness and decentralization for interoperability of the superstructure, though the individual quadratic funding rounds are more in the "decentralization for efficiency" school of thought (the theory behind Gitcoin Grants is that quadratic funding is a more efficient way to fund public goods).If the robustness and interoperability arguments did not apply, then it probably would have been better to simply run Gitcoin Grants as a regular company. But they do apply, and so Gitcoin Grants being a DAO makes sense.There are plenty of other examples of this kind of argument applying, both for DAOs that people increasingly rely on for their day-to-day lives, and for "meta-DAOs" that provide services to other DAOs:Proof of humanity Kleros Chainlink Stablecoins Blockchain layer 2 protocol governance I don't know enough about all of these systems to testify that they all do optimize for decentralization-for-robustness enough to satisfy my standards, but hopefully it should be obvious by now that they should.The main thing that does not work well are DAOs that require pivoting ability that is in conflict with robustness, and that do not have a sufficient case to "decentralize for efficiency". Large-scale companies that mainly interface with US users would be one example. When making a DAO, the first thing is to determine whether or not it is worth it to structure the project as a DAO, and the second thing is to determine whether it's targeting robustness or efficiency: if the former, deep thought into governance design is also required, and if the latter, then either it's innovating on governance via mechanisms like quadratic funding, or it should just be a multisig.5. Hybrid applicationsThere are many applications that are not entirely on-chain, but that take advantage of both blockchains and other systems to improve their trust models.Voting is an excellent example. High assurances of censorship resistance, auditability and privacy are all required, and systems like MACI effectively combine blockchains, ZK-SNARKs and a limited centralized (or M-of-N) layer for scalability and coercion resistance to achieve all of these guarantees. Votes are published to the blockchain, so users have a way independent of the voting system to ensure that their votes get included. But votes are encrypted, preserving privacy, and a ZK-SNARK-based solution is used to ensure that the final result is the correct computation of the votes. Diagram of how MACI works, combining together blockchains for censorship resistance, encryption for privacy, and ZK-SNARKs to ensure the result is correct without compromising on the other goals. Voting in existing national elections is already a high-assurance process, and it will take a long time before countries and citizens are comfortable with the security assurances of any electronic ways to vote, blockchain or otherwise. But technology like this can be valuable very soon in two other places:Increasing the assurance of voting processes that already happen electronically today (eg. social media votes, polls, petitions) Creating new forms of voting that allow citizens or members of groups to give rapid feedback, and baking high assurance into those from the start Going beyond voting, there is an entire field of potential "auditable centralized services" that could be well-served by some form of hybrid off-chain validium architecture. The easiest example of this is proof of solvency for exchanges, but there are plenty of other possible examples:Government registries Corporate accounting Games (see Dark Forest for an example) Supply chain applications Tracking access authorization ... As we go further down the list, we get to use cases that are lower and lower value, but it is important to remember that these use cases are also quite low cost. Validiums do not require publishing everything on-chain. Rather, they can be simple wrappers around existing pieces of software that maintain a Merkle root (or other commitment) of the database and occasionally publish the root on-chain along with a SNARK proving that it was updated correctly. This is a strict improvement over existing systems, because it opens the door for cross-institutional proofs and public auditing.So how do we get there?Many of these applications are being built today, though many of these applications are seeing only limited usage because of the limitations of present-day technology. Blockchains are not scalable, transactions until recently took a fairly long time to reliably get included on the chain, and present-day wallets give users an uncomfortable choice between low convenience and low security. In the longer term, many of these applications will need to overcome the specter of privacy issues.These are all problems that can be solved, and there is a strong drive to solve them. The FTX collapse has shown many people the importance of truly decentralized solutions to holding funds, and the rise of ERC-4337 and account abstraction wallets gives us an opportunity to create such alternatives. Rollup technology is rapidly progressing to solve scalability, and transactions already get included much more quickly on-chain than they did three years ago.But what is also important is to be intentional about the application ecosystem itself. Many of the more stable and boring applications do not get built because there is less excitement and less short-term profit to be earned around them: the LUNA market cap got to over $30 billion, while stablecoins striving for robustness and simplicity often get largely ignored for years. Non-financial applications often have no hope of earning $30 billion because they do not have a token at all. But it is these applications that will be most valuable for the ecosystem in the long term, and that will bring the most lasting value to both their users and those who build and support them.
-
Having a safe CEX: proof of solvency and beyond Having a safe CEX: proof of solvency and beyond2022 Nov 19 See all posts Having a safe CEX: proof of solvency and beyond Special thanks to Balaji Srinivasan, and Coinbase, Kraken and Binance staff for discussion.Every time a major centralized exchange blows up, a common question that comes up is whether or not we can use cryptographic techniques to solve the problem. Rather than relying solely on "fiat" methods like government licenses, auditors and examining the corporate governance and the backgrounds of the individuals running the exchange, exchanges could create cryptographic proofs that show that the funds they hold on-chain are enough to cover their liabilities to their users.Even more ambitiously, an exchange could build a system where it can't withdraw a depositor's funds at all without their consent. Potentially, we could explore the entire spectrum between the "don't be evil" aspiring-good-guy CEX and the "can't be evil", but for-now inefficient and privacy-leaking, on-chain DEX. This post will get into the history of attempts to move exchanges one or two steps closer to trustlessness, the limitations of these techniques, and some newer and more powerful ideas that rely on ZK-SNARKs and other advanced technologies.Balance lists and Merkle trees: old-school proof-of-solvencyThe earliest attempts by exchanges to try to cryptographically prove that they are not cheating their users go back quite far. In 2011, then-largest Bitcoin exchange MtGox proved that they had funds by sending a transaction that moved 424242 BTC to a pre-announced address. In 2013, discussions started on how to solve the other side of the problem: proving the total size of customers' deposits. If you prove that customers' deposits equal X ("proof of liabilities"), and prove ownership of the private keys of X coins ("proof of assets"), then you have a proof of solvency: you've proven the exchange has the funds to pay back all of its depositors.The simplest way to prove deposits is to simply publish a list of (username, balance) pairs. Each user can check that their balance is included in the list, and anyone can check the full list to see that (i) every balance is non-negative, and (ii) the total sum is the claimed amount. Of course, this breaks privacy, so we can change the scheme a little bit: publish a list of (hash(username, salt), balance) pairs, and send each user privately their salt value. But even this leaks balances, and it leaks the pattern of changes in balances. The desire to preserve privacy brings us to the next invention: the Merkle tree technique. Green: Charlie's node. Blue: nodes Charlie will receive as part of his proof. Yellow: root node, publicly shown to everyone. The Merkle tree technique consists of putting the table of customers' balances into a Merkle sum tree. In a Merkle sum tree, each node is a (balance, hash) pair. The bottom-layer leaf nodes represent the balances and salted username hashes of individual customers. In each higher-layer node, the balance is the sum of the two balances below, and the hash is the hash of the two nodes below. A Merkle sum proof, like a Merkle proof, is a "branch" of the tree, consisting of the sister nodes along the path from a leaf to the root.The exchange would send each user a Merkle sum proof of their balance. The user would then have a guarantee that their balance is correctly included as part of the total. A simple example code implementation can be found here.# The function for computing a parent node given two child nodes def combine_tree_nodes(L, R): L_hash, L_balance = L R_hash, R_balance = R assert L_balance >= 0 and R_balance >= 0 new_node_hash = hash( L_hash + L_balance.to_bytes(32, 'big') + R_hash + R_balance.to_bytes(32, 'big') ) return (new_node_hash, L_balance + R_balance) # Builds a full Merkle tree. Stored in flattened form where # node i is the parent of nodes 2i and 2i+1 def build_merkle_sum_tree(user_table: "List[(username, salt, balance)]"): tree_size = get_next_power_of_2(len(user_table)) tree = ( [None] * tree_size + [userdata_to_leaf(*user) for user in user_table] + [EMPTY_LEAF for _ in range(tree_size - len(user_table))] ) for i in range(tree_size - 1, 0, -1): tree[i] = combine_tree_nodes(tree[i*2], tree[i*2+1]) return tree # Root of a tree is stored at index 1 in the flattened form def get_root(tree): return tree[1] # Gets a proof for a node at a particular index def get_proof(tree, index): branch_length = log2(len(tree)) - 1 # ^ = bitwise xor, x ^ 1 = sister node of x index_in_tree = index + len(tree) // 2 return [tree[(index_in_tree // 2**i) ^ 1] for i in range(branch_length)] # Verifies a proof (duh) def verify_proof(username, salt, balance, index, user_table_size, root, proof): leaf = userdata_to_leaf(username, salt, balance) branch_length = log2(get_next_power_of_2(user_table_size)) - 1 for i in range(branch_length): if index & (2**i): leaf = combine_tree_nodes(proof[i], leaf) else: leaf = combine_tree_nodes(leaf, proof[i]) return leaf == rootPrivacy leakage in this design is much lower than with a fully public list, and it can be decreased further by shuffling the branches each time a root is published, but some privacy leakage is still there: Charlie learns that someone has a balance of 164 ETH, some two users have balances that add up to 70 ETH, etc. An attacker that controls many accounts could still potentially learn a significant amount about the exchange's users.One important subtlety of the scheme is the possibility of negative balances: what if an exchange that has 1390 ETH of customer balances but only 890 ETH in reserves tries to make up the difference by adding a -500 ETH balance under a fake account somewhere in the tree? It turns out that this possibility does not break the scheme, though this is the reason why we specifically need a Merkle sum tree and not a regular Merkle tree. Suppose that Henry is the fake account controlled by the exchange, and the exchange puts -500 ETH there: Greta's proof verification would fail: the exchange would have to give her Henry's -500 ETH node, which she would reject as invalid. Eve and Fred's proof verification would also fail, because the intermediate node above Henry has -230 total ETH, and so is also invalid! To get away with the theft, the exchange would have to hope that nobody in the entire right half of the tree checks their balance proof.If the exchange can identify 500 ETH worth of users that they are confident will either not bother to check the proof, or will not be believed when they complain that they never received a proof, they could get away with the theft. But then the exchange could also just exclude those users from the tree and have the same effect. Hence, the Merkle tree technique is basically as good as a proof-of-liabilities scheme can be, if only achieving a proof of liabilities is the goal. But its privacy properties are still not ideal. You can go a little bit further by using Merkle trees in more clever ways, like making each satoshi or wei a separate leaf, but ultimately with more modern tech there are even better ways to do it.Improving privacy and robustness with ZK-SNARKsZK-SNARKs are a powerful technology. ZK-SNARKs may be to cryptography what transformers are to AI: a general-purpose technology that is so powerful that it will completely steamroll a whole bunch of application-specific techniques for a whole bunch of problems that were developed in the decades prior. And so, of course, we can use ZK-SNARKs to greatly simplify and improve privacy in proof-of-liabilities protocols.The simplest thing that we can do is put all users' deposits into a Merkle tree (or, even simpler, a KZG commitment), and use a ZK-SNARK to prove that all balances in the tree are non-negative and add up to some claimed value. If we add a layer of hashing for privacy, the Merkle branch (or KZG proof) given to each user would reveal nothing about the balance of any other user. Using KZG commitments is one way to avoid privacy leakage, as there is no need to provide "sister nodes" as proofs, and a simple ZK-SNARK can be used to prove the sum of the balances and that each balance is non-negative. We can prove the sum and non-negativity of balances in the above KZG with a special-purpose ZK-SNARK. Here is one simple example way to do this. We introduce an auxiliary polynomial \(I(x)\), which "builds up the bits" of each balance (we assume for the sake of example that balances are under \(2^\)) and where every 16th position tracks a running total with an offset so that it sums to zero only if the actual total matches the declared total. If \(z\) is an order-128 root of unity, we might prove the equations: \(I(z^) = 0\)\(I(z^) = P(\omega^)\)\(I(z^) - 2*I(z^) \in \\ \ if\ \ i\ \ mod\ 16 \not \in \\)\(I(z^) = I(z^) + I(z^) - \frac\) The first values of a valid setting for \(I(x)\) would be 0 0 0 0 0 0 0 0 0 0 1 2 5 10 20 -165 0 0 0 0 0 0 0 0 0 1 3 6 12 25 50 -300 ...See here and here in my post on ZK-SNARKs for further explanation of how to convert equations like these into a polynomial check and then into a ZK-SNARK. This isn't an optimal protocol, but it does show how these days these kinds of cryptographic proofs are not that spooky!With only a few extra equations, constraint systems like this can be adapted to more complex settings. For example, in a leverage trading system, an individual users having negative balances is acceptable but only if they have enough other assets to cover the funds with some collateralization margin. A SNARK could be used to prove this more complicated constraint, reassuring users that the exchange is not risking their funds by secretly exempting other users from the rules.In the longer-term future, this kind of ZK proof of liabilities could perhaps be used not just for customer deposits at exchanges, but for lending more broadly. Anyone taking out a loan would put a record into a polynomial or a tree containing that loan, and the root of that structure would get published on-chain. This would let anyone seeking a loan ZK-prove to the lender that they have not yet taken out too many other loans. Eventually, legal innovation could even make loans that have been committed to in this way higher-priority than loans that have not. This leads us in exactly the same direction as one of the ideas that was discussed in the "Decentralized Society: Finding Web3's Soul" paper: a general notion of negative reputation or encumberments on-chain through some form of "soulbound tokens".Proof of assetsThe simplest version of proof of assets is the protocol that we saw above: to prove that you hold X coins, you simply move X coins around at some pre-agreed time or in a transaction where the data field contains the words "these funds belong to Binance". To avoid paying transaction fees, you could sign an off-chain message instead; both Bitcoin and Ethereum have standards for off-chain signed messages.There are two practical problems with this simple proof-of-assets technique:Dealing with cold storage Collateral dual-use For safety reasons, most exchanges keep the great majority of customer funds in "cold storage": on offline computers, where transactions need to be signed and carried over onto the internet manually. Literal air-gapping is common: a cold storage setup that I used to use for personal funds involved a permanently offline computer generating a QR code containing the signed transaction, which I would scan from my phone. Because of the high values at stake, the security protocols used by exchanges are crazier still, and often involve using multi-party computation between several devices to further reduce the chance of a hack against a single device compromising a key. Given this kind of setup, making even a single extra message to prove control of an address is an expensive operation!There are several paths that an exchange can take:Keep a few public long-term-use addresses. The exchange would generate a few addresses, publish a proof of each address once to prove ownership, and then use those addresses repeatedly. This is by far the simplest option, though it does add some constraints in how to preserve security and privacy. Have many addresses, prove a few randomly. The exchange would have many addresses, perhaps even using each address only once and retiring it after a single transaction. In this case, the exchange may have a protocol where from time to time a few addresses get randomly selected and must be "opened" to prove ownership. Some exchanges already do something like this with an auditor, but in principle this technique could be turned into a fully automated procedure. More complicated ZKP options. For example, an exchange could set all of its addresses to be 1-of-2 multisigs, where one of the keys is different per address, and the other is a blinded version of some "grand" emergency backup key stored in some complicated but very high-security way, eg. a 12-of-16 multisig. To preserve privacy and avoid revealing the entire set of its addresses, the exchange could even run a zero knowledge proof over the blockchain where it proves the total balance of all addresses on chain that have this format. The other major issue is guarding against collateral dual-use. Shuttling collateral back and forth between each other to do proof of reserves is something that exchanges could easily do, and would allow them to pretend to be solvent when they actually are not. Ideally, proof of solvency would be done in real time, with a proof that updates after every block. If this is impractical, the next best thing would be to coordinate on a fixed schedule between the different exchanges, eg. proving reserves at 1400 UTC every Tuesday.One final issue is: can you do proof-of-assets on fiat? Exchanges don't just hold cryptocurrency, they also hold fiat currency within the banking system. Here, the answer is: yes, but such a procedure would inevitably rely on "fiat" trust models: the bank itself can attest to balances, auditors can attest to balance sheets, etc. Given that fiat is not cryptographically verifiable, this is the best that can be done within that framework, but it's still worth doing.An alternative approach would be to cleanly separate between one entity that runs the exchange and deals with asset-backed stablecoins like USDC, and another entity (USDC itself) that handles the cash-in and cash-out process for moving between crypto and traditional banking systems. Because the "liabilities" of USDC are just on-chain ERC20 tokens, proof of liabilities comes "for free" and only proof of assets is required.Plasma and validiums: can we make CEXes non-custodial?Suppose that we want to go further: we don't want to just prove that the exchange has the funds to pay back its users. Rather, we want to prevent the exchange from stealing users' funds completely.The first major attempt at this was Plasma, a scaling solution that was popular in Ethereum research circles in 2017 and 2018. Plasma works by splitting up the balance into a set of individual "coins", where each coin is assigned an index and lives in a particular position in the Merkle tree of a Plasma block. Making a valid transfer of a coin requires putting a transaction into the correct position of a tree whose root gets published on-chain. Oversimplified diagram of one version of Plasma. Coins are held in a smart contract that enforces the rules of the Plasma protocol at withdrawal time. OmiseGo attempted to make a decentralized exchange based on this protocol, but since then they have pivoted to other ideas - as has, for that matter, Plasma Group itself, which is now the optimistic EVM rollup project Optimism.It's not worth looking at the technical limitations of Plasma as conceived in 2018 (eg. proving coin defragmentation) as some kind of morality tale about the whole concept. Since the peak of Plasma discourse in 2018, ZK-SNARKs have become much more viable for scaling-related use cases, and as we have said above, ZK-SNARKs change everything.The more modern version of the Plasma idea is what Starkware calls a validium: basically the same as a ZK-rollup, except where data is held off-chain. This construction could be used for a lot of use cases, conceivably anything where a centralized server needs to run some code and prove that it's executing code correctly. In a validium, the operator has no way to steal funds, though depending on the details of the implementation some quantity of user funds could get stuck if the operator disappears.This is all really good: far from CEX vs DEX being a binary, it turns out that there is a whole spectrum of options, including various forms of hybrid centralization where you gain some benefits like efficiency but still have a lot of cryptographic guardrails preventing the centralized operator from engaging in most forms of abuses. But it's worth getting to the fundamental issue with the right half of this design space: dealing with user errors. By far the most important type of error is: what if a user forgets their password, loses their devices, gets hacked, or otherwise loses access to their account?Exchanges can solve this problem: first e-mail recovery, and if even that fails, more complicated forms of recovery through KYC. But to be able to solve such problems, the exchange needs to actually have control over the coins. In order to have the ability to recover user accounts' funds for good reasons, exchanges need to have power that could also be used to steal user accounts' funds for bad reasons. This is an unavoidable tradeoff.The ideal long-term solution is to rely on self-custody, in a future where users have easy access to technologies such as multisig and social recovery wallets to help deal with emergency situations. But in the short term, there are two clear alternatives that have clearly distinct costs and benefits:Option Exchange-side risk User-side risk Custodial exchange (eg. Coinbase today) User funds may be lost if there is a problem on the exchange side Exchange can help recover account Non-custodial exchange (eg. Uniswap today) User can withdraw even if exchange acts maliciously User funds may be lost if user screws up Another important issue is cross-chain support: exchanges need to support many different chains, and systems like Plasma and validiums would need to have code written in different languages to support different platforms, and cannot be implemented at all on others (notably Bitcoin) in their current form. In the long-term future, this can hopefully be fixed with technological upgrades and standardization; in the short term, however, it's another argument in favor of custodial exchanges remaining custodial for now.Conclusions: the future of better exchangesIn the short term, there are two clear "classes" of exchanges: custodial exchanges and non-custodial exchanges. Today, the latter category is just DEXes such as Uniswap, and in the future we may also see cryptographically "constrained" CEXes where user funds are held in something like a validium smart contract. We may also see half-custodial exchanges where we trust them with fiat but not cryptocurrency.Both types of exchanges will continue to exist, and the easiest backwards-compatible way to improve the safety of custodial exchanges is to add proof of reserve. This consists of a combination of proof of assets and proof of liabilities. There are technical challenges in making good protocols for both, but we can and should go as far as possible to make headway in both, and open-source the software and processes as much as possible so that all exchanges can benefit.In the longer-term future, my hope is that we move closer and closer to all exchanges being non-custodial, at least on the crypto side. Wallet recovery would exist, and there may need to be highly centralized recovery options for new users dealing with small amounts, as well as institutions that require such arrangements for legal reasons, but this can be done at the wallet layer rather than within the exchange itself. On the fiat side, movement between the traditional banking system and the crypto ecosystem could be done via cash in / cash out processes native to asset-backed stablecoins such as USDC. However, it will still take a while before we can fully get there.
-
The Revenue-Evil Curve: a different way to think about prioritizing public goods funding The Revenue-Evil Curve: a different way to think about prioritizing public goods funding2022 Oct 28 See all posts The Revenue-Evil Curve: a different way to think about prioritizing public goods funding Special thanks to Karl Floersch, Hasu and Tina Zhen for feedback and review.Public goods are an incredibly important topic in any large-scale ecosystem, but they are also one that is often surprisingly tricky to define. There is an economist definition of public goods - goods that are non-excludable and non-rivalrous, two technical terms that taken together mean that it's difficult to provide them through private property and market-based means. There is a layman's definition of public good: "anything that is good for the public". And there is a democracy enthusiast's definition of public good, which includes connotations of public participation in decision-making.But more importantly, when the abstract category of non-excludable non-rivalrous public goods interacts with the real world, in almost any specific case there are all kinds of subtle edge cases that need to be treated differently. A park is a public good. But what if you add a $5 entrance fee? What if you fund it by auctioning off the right to have a statue of the winner in the park's central square? What if it's maintained by a semi-altruistic billionaire that enjoys the park for personal use, and designs the park around their personal use, but still leaves it open for anyone to visit?This post will attempt to provide a different way of analyzing "hybrid" goods on the spectrum between private and public: the revenue-evil curve. We ask the question: what are the tradeoffs of different ways to monetize a given project, and how much good can be done by adding external subsidies to remove the pressure to monetize? This is far from a universal framework: it assumes a "mixed-economy" setting in a single monolithic "community" with a commercial market combined with subsidies from a central funder. But it can still tell us a lot about how to approach funding public goods in crypto communities, countries and many other real-world contexts today.The traditional framework: excludability and rivalrousnessLet us start off by understanding how the usual economist lens views which projects are private vs public goods. Consider the following examples:Alice owns 1000 ETH, and wants to sell it on the market. Bob runs an airline, and sells tickets for a flight. Charlie builds a bridge, and charges a toll to pay for it. David makes and releases a podcast. Eve makes and releases a song. Fred invents a new and better cryptographic algorithm for making zero knowledge proofs. We put these situations on a chart with two axes:Rivalrousness: to what extent does one person enjoying the good reduce another person's ability to enjoy it? Excludability: how difficult is it to prevent specific individuals, eg. those who do not pay, from enjoying the good? Such a chart might look like this: Alice's ETH is completely excludable (she has total power to choose who gets her coins), and crypto coins are rivalrous (if one person owns a particular coin, no one else owns that same coin) Bob's plane tickets are excludable, but a tiny bit less rivalrous: there's a chance the plane won't be full. Charlie's bridge is a bit less excludable than plane tickets, because adding a gate to verify payment of tolls takes extra effort (so Charlie can exclude but it's costly, both to him and to users), and its rivalrousness depends on whether the road is congested or not. David's podcast and Eve's song are not rivalrous: one person listening to it does not interfere with another person doing the same. They're a little bit excludable, because you can make a paywall but people can circumvent the paywall. And Fred's cryptographic algorithm is close to not excludable at all: it needs to be open-source for people to trust it, and if Fred tries to patent it, the target user base (open-source-loving crypto users) may well refuse to use the algorithm and even cancel him for it. This is all a good and important analysis. Excludability tells us whether or not you can fund the project by charging a toll as a business model, and rivalrousness tells us whether exclusion is a tragic waste or if it's just an unavoidable property of the good in question that if one person gets it another does not. But if we look at some of the examples carefully, especially the digital examples, we start to see that it misses a very important issue: there are many business models available other than exclusion, and those business models have tradeoffs too.Consider one particular case: David's podcast versus Eve's song. In practice, a huge number of podcasts are released mostly or completely freely, but songs are more often gated with licensing and copyright restrictions. To see why, we need only look at how these podcasts are funded: sponsorships. Podcast hosts typically find a few sponsors, and talk about the sponsors briefly at the start or middle of each episode. Sponsoring songs is harder: you can't suddenly start talking about how awesome Athletic Greens* are in the middle of a love song, because come on, it kills the vibe, man!Can we get beyond focusing solely on exclusion, and talk about monetization and the harms of different monetization strategies more generally? Indeed we can, and this is exactly what the revenue/evil curve is about.The revenue-evil curve, definedThe revenue-evil curve of a product is a two-dimensional curve that plots the answer to the following question:How much harm would the product's creator have to inflict on their potential users and the wider community to earn $N of revenue to pay for building the product?The word "evil" here is absolutely not meant to imply that no quantity of evil is acceptable, and that if you can't fund a project without committing evil you should not do it at all. Many projects make hard tradeoffs that hurt their customers and community in order to ensure sustainable funding, and often the value of the project existing at all greatly outweighs these harms. But nevertheless, the goal is to highlight that there is a tragic aspect to many monetization schemes, and public goods funding can provide value by giving existing projects a financial cushion that enables them to avoid such sacrifices.Here is a rough attempt at plotting the revenue-evil curves of our six examples above: For Alice, selling her ETH at market price is actually the most compassionate thing she could do. If she sells more cheaply, she will almost certainly create an on-chain gas war, trader HFT war, or other similarly value-destructive financial conflict between everyone trying to claim her coins the fastest. Selling above market price is not even an option: no one would buy. For Bob, the socially-optimal price to sell at is the highest price at which all tickets get sold out. If Bob sells below that price, tickets will sell out quickly and some people will not be able to get seats at all even if they really need them (underpricing may have a few countervailing benefits by giving opportunities to poor people, but it is far from the most efficient way to achieve that goal). Bob could also sell above market price and potentially earn a higher profit at the cost of selling fewer seats and (from the god's-eye perspective) needlessly excluding people. If Charlie's bridge and the road leading to it are uncongested, charging any toll at all imposes a burden and needlessly excludes drivers. If they are congested, low tolls help by reducing congestion and high tolls needlessly exclude people. David's podcast can monetize to some extent without hurting listeners much by adding advertisements from sponsors. If pressure to monetize increases, David would have to adopt more and more intrusive forms of advertising, and truly maxing out on revenue would require paywalling the podcast, a high cost to potential listeners. Eve is in the same position as David, but with fewer low-harm options (perhaps selling an NFT?). Especially in Eve's case, paywalling may well require actively participating in the legal apparatus of copyright enforcement and suing infringers, which carries further harms. Fred has even fewer monetization options. He could patent it, or potentially do exotic things like auction off the right to choose parameters so that hardware manufacturers that favor particular values would bid on it. All options are high-cost. What we see here is that there are actually many kinds of "evil" on the revenue-evil curve:Traditional economic deadweight loss from exclusion: if a product is priced above marginal cost, mutually beneficial transactions that could have taken place do not take place Race conditions: congestion, shortages and other costs from products being too cheap. "Polluting" the product in ways that make it appealing to a sponsor, but is harmful to a (maybe small, maybe large) degree to listeners. Engaging in offensive actions through the legal system, which increases everyone's fear and need to spend money on lawyers, and has all kinds of hard-to-predict secondary chilling effects. This is particularly severe in the case of patenting. Sacrificing on principles highly valued by the users, the community and even the people working on the project itself. In many cases, this evil is very context-dependent. Patenting is both extremely harmful and ideologically offensive within the crypto space and software more broadly, but this is less true in industries building physical goods: in physical goods industries, most people who realistically can create a derivative work of something patented are going to be large and well-organized enough to negotiate for a license, and capital costs mean that the need for monetization is much higher and hence maintaining purity is harder. To what extent advertisements are harmful depends on the advertiser and the audience: if the podcaster understands the audience very well, ads can even be helpful! Whether or not the possibility to "exclude" even exists depends on property rights.But by talking about committing evil for the sake of earning revenue in general terms, we gain the ability to compare these situations against each other.What does the revenue-evil curve tell us about funding prioritization?Now, let's get back to the key question of why we care about what is a public good and what is not: funding prioritization. If we have a limited pool of capital that is dedicated to helping a community prosper, which things should we direct funding to? The revenue-evil curve graphic gives us a simple starting point for an answer: direct funds toward those projects where the slope of the revenue-evil curve is the steepest.We should focus on projects where each $1 of subsidies, by reducing the pressure to monetize, most greatly reduces the evil that is unfortunately required to make the project possible. This gives us roughly this ranking:Top of the line are "pure" public goods, because often there aren't any ways to monetize them at all, or if there are, the economic or moral costs of trying to monetize are extremely high. Second priority is "naturally" public but monetizable goods that can be funded through commercial channels by tweaking them a bit, like songs or sponsorships to a podcast. Third priority is non-commodity-like private goods where social welfare is already optimized by charging a fee, but where profit margins are high or more generally there are opportunities to "pollute" the product to increase revenue, eg. by keeping accompanying software closed-source or refusing to use standards, and subsidies could be used to push such projects to make more pro-social choices on the margin. Notice that the excludability and rivalrousness framework usually outputs similar answers: focus on non-excludable and non-rivalrous goods first, excludable goods but non-rivalrous second, and excludable and partially rivalrous goods last - and excludable and rivalrous goods never (if you have capital left over, it's better to just give it out as a UBI). There is a rough approximate mapping between revenue/evil curves and excludability and rivalrousness: higher excludability means lower slope of the revenue/evil curve, and rivalrousness tells us whether the bottom of the revenue/evil curve is zero or nonzero. But the revenue/evil curve is a much more general tool, which allows us to talk about tradeoffs of monetization strategies that go far beyond exclusion.One practical example of how this framework can be used to analyze decision-making is Wikimedia donations. I personally have never donated to Wikimedia, because I've always thought that they could and should fund themselves without relying on limited public-goods-funding capital by just adding a few advertisements, and this would be only a small cost to their user experience and neutrality. Wikipedia admins, however, disagree; they even have a wiki page listing their arguments why they disagree.We can understand this disagreement as a dispute over revenue-evil curves: I think Wikimedia's revenue-evil curve has a low slope ("ads are not that bad"), and therefore they are low priority for my charity dollars; some other people think their revenue-evil curve has a high slope, and therefore they are high priority for their charity dollars.Revenue-evil curves are an intellectual tool, NOT a good direct mechanismOne important conclusion that it is important NOT to take from this idea is that we should try to use revenue-evil curves directly as a way of prioritizing individual projects. There are severe constraints on our ability to do this because of limits to monitoring.If this framework is widely used, projects would have an incentive to misrepresent their revenue-evil curves. Anyone charging a toll would have an incentive to come up with clever arguments to try to show that the world would be much better if the toll could be 20% lower, but because they're desperately under-budget, they just can't lower the toll without subsidies. Projects would have an incentive to be more evil in the short term, to attract subsidies that help them become less evil.For these reasons, it is probably best to use the framework not as a way to allocate decisions directly, but to identify general principles for what kinds of projects to prioritize funding for. For example, the framework can be a valid way to determine how to prioritize whole industries or whole categories of goods. It can help you answer questions like: if a company is producing a public good, or is making pro-social but financially costly choices in the design of a not-quite-public good, do they deserve subsidies for that? But even here, it's better to treat revenue-evil curves as a mental tool, rather than attempting to precisely measure them and use them to make individual decisions.ConclusionsExcludability and rivalrousness are important dimensions of a good, that have really important consequences for its ability to monetize itself, and for answering the question of how much harm can be averted by funding it out of some public pot. But especially once more complex projects enter the fray, these two dimensions quickly start to become insufficient for determining how to prioritize funding. Most things are not pure public goods: they are some hybrid in the middle, and there are many dimensions on which they could become more or less public that do not easily map to "exclusion".Looking at the revenue-evil curve of a project gives us another way of measuring the statistic that really matters: how much harm can be averted by relieving a project of one dollar of monetization pressure? Sometimes, the gains from relieving monetization pressure are decisive: there just is no way to fund certain kinds of things through commercial channels, until you can find one single user that benefits from them enough to fund them unilaterally. Other times, commercial funding options exist, but have harmful side effects. Sometimes these effects are smaller, sometimes they are greater. Sometimes a small piece of an individual project has a clear tradeoff between pro-social choices and increasing monetization. And, still other times, projects just fund themselves, and there is no need to subsidize them - or at least, uncertainties and hidden information make it too hard to create a subsidy schedule that does more good than harm. It's always better to prioritize funding in order of greatest gains to smallest; and how far you can go depends on how much funding you have.* I did not accept sponsorship money from Athletic Greens. But the podcaster Lex Fridman did. And no, I did not accept sponsorship money from Lex Fridman either. But maybe someone else did. Whatevs man, as long as we can keep getting podcasts funded so they can be free-to-listen without annoying people too much, it's all good, you know?
-
DAOs are not corporations: where decentralization in autonomous organizations matters DAOs are not corporations: where decentralization in autonomous organizations matters2022 Sep 20 See all posts DAOs are not corporations: where decentralization in autonomous organizations matters Special thanks to Karl Floersch and Tina Zhen for feedback and review on earlier versions of this article.Recently, there has been a lot of discourse around the idea that highly decentralized DAOs do not work, and DAO governance should start to more closely resemble that of traditional corporations in order to remain competitive. The argument is always similar: highly decentralized governance is inefficient, and traditional corporate governance structures with boards, CEOs and the like evolved over hundreds of years to optimize for the goal of making good decisions and delivering value to shareholders in a changing world. DAO idealists are naive to assume that egalitarian ideals of decentralization can outperform this, when attempts to do this in the traditional corporate sector have had marginal success at best.This post will argue why this position is often wrong, and offer a different and more detailed perspective about where different kinds of decentralization are important. In particular, I will focus on three types of situations where decentralization is important:Decentralization for making better decisions in concave environments, where pluralism and even naive forms of compromise are on average likely to outperform the kinds of coherency and focus that come from centralization. Decentralization for censorship resistance: applications that need to continue functioning while resisting attacks from powerful external actors. Decentralization as credible fairness: applications where DAOs are taking on nation-state-like functions like basic infrastructure provision, and so traits like predictability, robustness and neutrality are valued above efficiency. Centralization is convex, decentralization is concaveSee the original post: ../../../2020/11/08/concave.htmlOne way to categorize decisions that need to be made is to look at whether they are convex or concave. In a choice between A and B, we would first look not at the question of A vs B itself, but instead at a higher-order question: would you rather take a compromise between A and B or a coin flip? In expected utility terms, we can express this distinction using a graph: If a decision is concave, we would prefer a compromise, and if it's convex, we would prefer a coin flip. Often, we can answer the higher-order question of whether a compromise or a coin flip is better much more easily than we can answer the first-order question of A vs B itself.Examples of convex decisions include:Pandemic response: a 100% travel ban may work at keeping a virus out, a 0% travel ban won't stop viruses but at least doesn't inconvenience people, but a 50% or 90% travel ban is the worst of both worlds. Military strategy: attacking on front A may make sense, attacking on front B may make sense, but splitting your army in half and attacking at both just means the enemy can easily deal with the two halves one by one Technology choices in crypto protocols: using technology A may make sense, using technology B may make sense, but some hybrid between the two often just leads to needless complexity and even adds risks of the two interfering with each other. Examples of concave decisions include:Judicial decisions: an average between two independently chosen judgements is probably more likely to be fair, and less likely to be completely ridiculous, than a random choice of one of the two judgements. Public goods funding: usually, giving $X to each of two promising projects is more effective than giving $2X to one and nothing to the other. Having any money at all gives a much bigger boost to a project's ability to achieve its mission than going from $X to $2X does. Tax rates: because of quadratic deadweight loss mechanics, a tax rate of X% is often only a quarter as harmful as a tax rate of 2X%, and at the same time more than half as good at raising revenue. Hence, moderate taxes are better than a coin flip between low/no taxes and high taxes. When decisions are convex, decentralizing the process of making that decision can easily lead to confusion and low-quality compromises. When decisions are concave, on the other hand, relying on the wisdom of the crowds can give better answers. In these cases, DAO-like structures with large amounts of diverse input going into decision-making can make a lot of sense. And indeed, people who see the world as a more concave place in general are more likely to see a need for decentralization in a wider variety of contexts.Should VitaDAO and Ukraine DAO be DAOs?Many of the more recent DAOs differ from earlier DAOs, like MakerDAO, in that whereas the earlier DAOs are organized around providing infrastructure, the newer DAOs are organized around performing various tasks around a particular theme. VitaDAO is a DAO funding early-stage longevity research, and UkraineDAO is a DAO organizing and funding efforts related to helping Ukrainian victims of war and supporting the Ukrainian defense effort. Does it make sense for these to be DAOs?This is a nuanced question, and we can get a view of one possible answer by understanding the internal workings of UkraineDAO itself. Typical DAOs tend to "decentralize" by gathering large amounts of capital into a single pool and using token-holder voting to fund each allocation. UkraineDAO, on the other hand, works by splitting its functions up into many pods, where each pod works as independently as possible. A top layer of governance can create new pods (in principle, governance can also fund pods, though so far funding has only gone to external Ukraine-related organizations), but once a pod is made and endowed with resources, it functions largely on its own. Internally, individual pods do have leaders and function in a more centralized way, though they still try to respect an ethos of personal autonomy. One natural question that one might ask is: isn't this kind of "DAO" just rebranding the traditional concept of multi-layer hierarchy? I would say this depends on the implementation: it's certainly possible to take this template and turn it into something that feels authoritarian in the same way stereotypical large corporations do, but it's also possible to use the template in a very different way.Two things that can help ensure that an organization built this way will actually turn out to be meaningfully decentralized include:A truly high level of autonomy for pods, where the pods accept resources from the core and are occasionally checked for alignment and competence if they want to keep getting those resources, but otherwise act entirely on their own and don't "take orders" from the core. Highly decentralized and diverse core governance. This does not require a "governance token", but it does require broader and more diverse participation in the core. Normally, broad and diverse participation is a large tax on efficiency. But if (1) is satisfied, so pods are highly autonomous and the core needs to make fewer decisions, the effects of top-level governance being less efficient become smaller. Now, how does this fit into the "convex vs concave" framework? Here, the answer is roughly as follows: the (more decentralized) top level is concave, the (more centralized within each pod) bottom level is convex. Giving a pod $X is generally better than a coin flip between giving it $0 and giving it $2X, and there isn't a large loss from having compromises or "inconsistent" philosophies guiding different decisions. But within each individual pod, having a clear opinionated perspective guiding decisions and being able to insist on many choices that have synergies with each other is much more important.Decentralization and censorship resistanceThe most often publicly cited reason for decentralization in crypto is censorship resistance: a DAO or protocol needs to be able to function and defend itself despite external attack, including from large corporate or even state actors. This has already been publicly talked about at length, and so deserves less elaboration, but there are still some important nuances.Two of the most successful censorship-resistant services that large numbers of people use today are The Pirate Bay and Sci-Hub. The Pirate Bay is a hybrid system: it's a search engine for BitTorrent, which is a highly decentralized network, but the search engine itself is centralized. It has a small core team that is dedicated to keeping it running, and it defends itself with the mole's strategy in whack-a-mole: when the hammer comes down, move out of the way and re-appear somewhere else. The Pirate Bay and Sci-Hub have both frequently changed domain names, relied on arbitrage between different jurisdictions, and used all kinds of other techniques. This strategy is centralized, but it has allowed them both to be successful both at defense and at product-improvement agility.DAOs do not act like The Pirate Bay and Sci-Hub; DAOs act like BitTorrent. And there is a reason why BitTorrent does need to be decentralized: it requires not just censorship resistance, but also long-term investment and reliability. If BitTorrent got shut down once a year and required all its seeders and users to switch to a new provider, the network would quickly degrade in quality. Censorship resistance-demanding DAOs should also be in the same category: they should be providing a service that isn't just evading permanent censorship, but also evading mere instability and disruption. MakerDAO (and the Reflexer DAO which manages RAI) are excellent examples of this. A DAO running a decentralized search engine probably does not: you can just build a regular search engine and use Sci-Hub-style techniques to ensure its survival.Decentralization as credible fairnessSometimes, DAOs' primary concern is not a need to resist nation states, but rather a need to take on some of the functions of nation states. This often involves tasks that can be described as "maintaining basic infrastructure". Because governments have less ability to oversee DAOs, DAOs need to be structured to take on a greater ability to oversee themselves. And this requires decentralization. Of course, it's not actually possible to come anywhere close to eliminating hierarchy and inequality of information and decision-making power in its entirety etc etc etc, but what if we can get even 30% of the way there? Consider three motivating examples: algorithmic stablecoins, the Kleros court, and the Optimism retroactive funding mechanism.An algorithmic stablecoin DAO is a system that uses on-chain financial contracts to create a crypto-asset whose price tracks some stable index, often but not necessarily the US dollar. Kleros is a "decentralized court": a DAO whose function is to give rulings on arbitration questions such as "is this Github commit an acceptable submission to this on-chain bounty?" Optimism's retroactive funding mechanism is a component of the Optimism DAO which retroactively rewards projects that have provided value to the Ethereum and Optimism ecosystems. In all three cases, there is a need to make subjective judgements, which cannot be done automatically through a piece of on-chain code. In the first case, the goal is simply to get reasonably accurate measurements of some price index. If the stablecoin tracks the US dollar, then you just need the ETH/USD price. If hyperinflation or some other reason to abandon the US dollar arises, the stablecoin DAO might need to manage a trustworthy on-chain CPI calculation. Kleros is all about making unavoidably subjective judgements on any arbitrary question that is submitted to it, including whether or not submitted questions should be rejected for being "unethical". Optimism's retroactive funding is tasked with one of the most open-ended subjective questions at all: what projects have done work that is the most useful to the Ethereum and Optimism ecosystems?All three cases have an unavoidable need for "governance", and pretty robust governance too. In all cases, governance being attackable, from the outside or the inside, can easily lead to very big problems. Finally, the governance doesn't just need to be robust, it needs to credibly convince a large and untrusting public that it is robust.The algorithmic stablecoin's Achilles heel: the oracleAlgorithmic stablecoins depend on oracles. In order for an on-chain smart contract to know whether to target the value of DAI to 0.005 ETH or 0.0005 ETH, it needs some mechanism to learn the (external-to-the-chain) piece of information of what the ETH/USD price is. And in fact, this "oracle" is the primary place at which an algorithmic stablecoin can be attacked.This leads to a security conundrum: an algorithmic stablecoin cannot safely hold more collateral, and therefore cannot issue more units, than the market cap of its speculative token (eg. MKR, FLX...), because if it does, then it becomes profitable to buy up half the speculative token supply, use those tokens to control the oracle, and steal funds from users by feeding bad oracle values and liquidating them.Here is a possible alternative design for a stablecoin oracle: add a layer of indirection. Quoting the ethresear.ch post:We set up a contract where there are 13 "providers"; the answer to a query is the median of the answer returned by these providers. Every week, there is a vote, where the oracle token holders can replace one of the providers ...The security model is simple: if you trust the voting mechanism, you can trust the oracle output, unless 7 providers get corrupted at the same time. If you trust the current set of oracle providers, you can trust the output for at least the next six weeks, even if you completely do not trust the voting mechanism. Hence, if the voting mechanism gets corrupted, there will be able time for participants in any applications that depend on the oracle to make an orderly exit.Notice the very un-corporate-like nature of this proposal. It involves taking away the governance's ability to act quickly, and intentionally spreading out oracle responsibility across a large number of participants. This is valuable for two reasons. First, it makes it harder for outsiders to attack the oracle, and for new coin holders to quickly take over control of the oracle. Second, it makes it harder for the oracle participants themselves to collude to attack the system. It also mitigates oracle extractable value, where a single provider might intentionally delay publishing to personally profit from a liquidation (in a multi-provider system, if one provider doesn't immediately publish, others soon will).Fairness in KlerosThe "decentralized court" system Kleros is a really valuable and important piece of infrastructure for the Ethereum ecosystem: Proof of Humanity uses it, various "smart contract bug insurance" products use it, and many other projects plug into it as some kind of "adjudication of last resort".Recently, there have been some public concerns about whether or not the platform's decision-making is fair. Some participants have made cases, trying to claim a payout from decentralized smart contract insurance platforms that they argue they deserve. Perhaps the most famous of these cases is Mizu's report on case #1170. The case blew up from being a minor language intepretation dispute into a broader scandal because of the accusation that insiders to Kleros itself were making a coordinated effort to throw a large number of tokens to pushing the decision in the direction they wanted. A participant to the debate writes:The incentives-based decision-making process of the court ... is by all appearances being corrupted by a single dev with a very large (25%) stake in the courts.Of course, this is but one side of one issue in a broader debate, and it's up to the Kleros community to figure out who is right or wrong and how to respond. But zooming out from the question of this individual case, what is important here is the the extent to which the entire value proposition of something like Kleros depends on it being able to convince the public that it is strongly protected against this kind of centralized manipulation. For something like Kleros to be trusted, it seems necessary that there should not be a single individual with a 25% stake in a high-level court. Whether through a more widely distributed token supply, or through more use of non-token-driven governance, a more credibly decentralized form of governance could help Kleros avoid such concerns entirely.Optimism retro fundingOptimism's retroactive founding round 1 results were chosen by a quadratic vote among 24 "badge holders". Round 2 will likely use a larger number of badge holders, and the eventual goal is to move to a system where a much larger body of citizens control retro funding allocation, likely through some multilayered mechanism involving sortition, subcommittees and/or delegation.There have been some internal debates about whether to have more vs fewer citizens: should "citizen" really mean something closer to "senator", an expert contributor who deeply understands the Optimism ecosystem, should it be a position given out to just about anyone who has significantly participated in the Optimism ecosystem, or somewhere in between? My personal stance on this issue has always been in the direction of more citizens, solving governance inefficiency issues with second-layer delegation instead of adding enshrined centralization into the governance protocol. One key reason for my position is the potential for insider trading and self-dealing issues.The Optimism retroactive funding mechanism has always been intended to be coupled with a prospective speculation ecosystem: public-goods projects that need funding now could sell "project tokens", and anyone who buys project tokens becomes eligible for a large retroactively-funded compensation later. But this mechanism working well depends crucially on the retroactive funding part working correctly, and is very vulnerable to the retroactive funding mechanism becoming corrupted. Some example attacks:If some group of people has decided how they will vote on some project, they can buy up (or if overpriced, short) its project token ahead of releasing the decision. If some group of people knows that they will later adjudicate on some specific project, they can buy up the project token early and then intentionally vote in its favor even if the project does not actually deserve funding. Funding deciders can accept bribes from projects. There are typically three ways of dealing with these types of corruption and insider trading issues:Retroactively punish malicious deciders. Proactively filter for higher-quality deciders. Add more deciders. The corporate world typically focuses on the first two, using financial surveillance and judicious penalties for the first and in-person interviews and background checks for the second. The decentralized world has less access to such tools: project tokens are likely to be tradeable anonymously, DAOs have at best limited recourse to external judicial systems, and the remote and online nature of the projects and the desire for global inclusivity makes it harder to do background checks and informal in-person "smell tests" for character. Hence, the decentralized world needs to put more weight on the third technique: distribute decision-making power among more deciders, so that each individual decider has less power, and so collusions are more likely to be whistleblown on and revealed.Should DAOs learn more from corporate governance or political science?Curtis Yarvin, an American philosopher whose primary "big idea" is that corporations are much more effective and optimized than governments and so we should improve governments by making them look more like corporations (eg. by moving away from democracy and closer to monarchy), recently wrote an article expressing his thoughts on how DAO governance should be designed. Not surprisingly, his answer involves borrowing ideas from governance of traditional corporations. From his introduction:Instead the basic design of the Anglo-American limited-liability joint-stock company has remained roughly unchanged since the start of the Industrial Revolution—which, a contrarian historian might argue, might actually have been a Corporate Revolution. If the joint-stock design is not perfectly optimal, we can expect it to be nearly optimal.While there is a categorical difference between these two types of organizations—we could call them first-order (sovereign) and second-order (contractual) organizations—it seems that society in the current year has very effective second-order organizations, but not very effective first-order organizations.Therefore, we probably know more about second-order organizations. So, when designing a DAO, we should start from corporate governance, not political science.Yarvin's post is very correct in identifying the key difference between "first-order" (sovereign) and "second-order" (contractual) organizations - in fact, that exact distinction is precisely the topic of the section in my own post above on credible fairness. However, Yarvin's post makes a big, and surprising, mistake immediately after, by immediately pivoting to saying that corporate governance is the better starting point for how DAOs should operate. The mistake is surprising because the logic of the situation seems to almost directly imply the exact opposite conclusion. Because DAOs do not have a sovereign above them, and are often explicitly in the business of providing services (like currency and arbitration) that are typically reserved for sovereigns, it is precisely the design of sovereigns (political science), and not the design of corporate governance, that DAOs have more to learn from.To Yarvin's credit, the second part of his post does advocate an "hourglass" model that combines a decentralized alignment and accountability layer and a centralized management and execution layer, but this is already an admission that DAO design needs to learn at least as much from first-order orgs as from second-order orgs.Sovereigns are inefficient and corporations are efficient for the same reason why number theory can prove very many things but abstract group theory can prove much fewer things: corporations fail less and accomplish more because they can make more assumptions and have more powerful tools to work with. Corporations can count on their local sovereign to stand up to defend them if the need arises, as well as to provide an external legal system they can lean on to stabilize their incentive structure. In a sovereign, on the other hand, the biggest challenge is often what to do when the incentive structure is under attack and/or at risk of collapsing entirely, with no external leviathan standing ready to support it.Perhaps the greatest problem in the design of successful governance systems for sovereigns is what Samo Burja calls "the succession problem": how to ensure continuity as the system transitions from being run by one group of humans to another group as the first group retires. Corporations, Burja writes, often just don't solve the problem at all:Silicon Valley enthuses over "disruption" because we have become so used to the succession problem remaining unsolved within discrete institutions such as companies.DAOs will need to solve the succession problem eventually (in fact, given the sheer frequency of the "get rich and retire" pattern among crypto early adopters, some DAOs have to deal with succession issues already). Monarchies and corporate-like forms often have a hard time solving the succession problem, because the institutional structure gets deeply tied up with the habits of one specific person, and it either proves difficult to hand off, or there is a very-high-stakes struggle over whom to hand it off to. More decentralized political forms like democracy have at least a theory of how smooth transitions can happen. Hence, I would argue that for this reason too, DAOs have more to learn from the more liberal and democratic schools of political science than they do from the governance of corporations.Of course, DAOs will in some cases have to accomplish specific complicated tasks, and some use of corporate-like forms for accomplishing those tasks may well be a good idea. Additionally, DAOs need to handle unexpected uncertainty. A system that was intended to function in a stable and unchanging way around one set of assumptions, when faced with an extreme and unexpected change to those circumstances, does need some kind of brave leader to coordinate a response. A prototypical example of the latter is stablecoins handling a US dollar collapse: what happens when a stablecoin DAO that evolved around the assumption that it's just trying to track the US dollar suddenly faces a world where the US dollar is no longer a viable thing to be tracking, and a rapid switch to some kind of CPI is needed? Stylized diagram of the internal experience of the RAI ecosystem going through an unexpected transition to a CPI-based regime if the USD ceases to be a viable reference asset. Here, corporate governance-inspired approaches may seem better, because they offer a ready-made pattern for responding to such a problem: the founder organizes a pivot. But as it turns out, the history of political systems also offers a pattern well-suited to this situation, and one that covers the question of how to go back to a decentralized mode when the crisis is over: the Roman Republic custom of electing a dictator for a temporary term to respond to a crisis.Realistically, we probably only need a small number of DAOs that look more like constructs from political science than something out of corporate governance. But those are the really important ones. A stablecoin does not need to be efficient; it must first and foremost be stable and decentralized. A decentralized court is similar. A system that directs funding for a particular cause - whether Optimism retroactive funding, VitaDAO, UkraineDAO or something else - is optimizing for a much more complicated purpose than profit maximization, and so an alignment solution other than shareholder profit is needed to make sure it keeps using the funds for the purpose that was intended.By far the greatest number of organizations, even in a crypto world, are going to be "contractual" second-order organizations that ultimately lean on these first-order giants for support, and for these organizations, much simpler and leader-driven forms of governance emphasizing agility are often going to make sense. But this should not distract from the fact that the ecosystem would not survive without some non-corporate decentralized forms keeping the whole thing stable.