找到
1087
篇与
heyuan
相关的结果
-
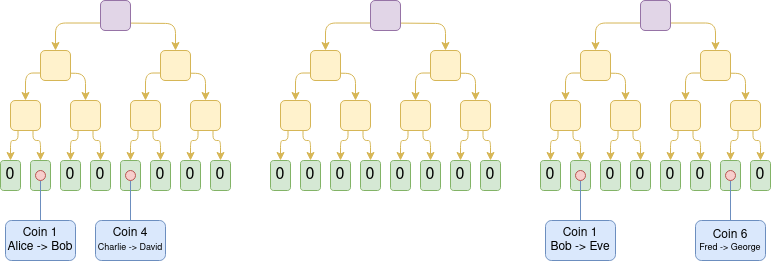
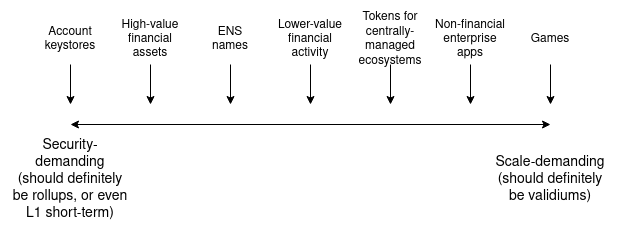
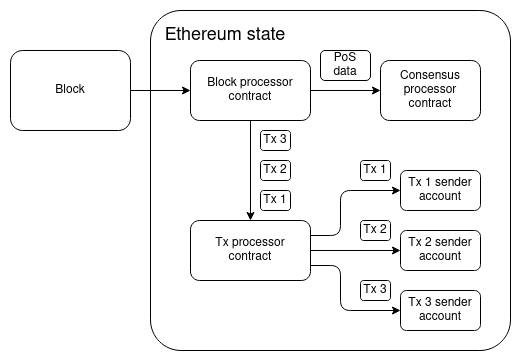
 Make Ethereum Cypherpunk Again Make Ethereum Cypherpunk Again2023 Dec 28 See all posts Make Ethereum Cypherpunk Again Special thanks to Paul Dylan-Ennis for feedback and review.One of my favorite memories from ten years ago was taking a pilgrimage to a part of Berlin that was called the Bitcoin Kiez: a region in Kreuzberg where there were around a dozen shops within a few hundred meters of each other that were all accepting Bitcoin for payments. The centerpiece of this community was Room 77, a restaurant and bar run by Joerg Platzer. In addition to simply accepting Bitcoin, it also served as a community center, and all kinds of open source developers, political activists of various affiliations, and other characters would frequently come by. Room 77, 2013. Source: my article from 2013 on Bitcoin Magazine. A similar memory from two months earlier was PorcFest (that's "porc" as in "porcupine" as in "don't tread on me"), a libertarian gathering in the forests of northern New Hampshire, where the main way to get food was from small popup restaurants with names like "Revolution Coffee" and "Seditious Soups, Salads and Smoothies", which of course accepted Bitcoin. Here too, discussing the deeper political meaning of Bitcoin, and using it in daily life, happened together side by side.The reason why I bring these memories up is that they remind me of a deeper vision underlying crypto: we are not here to just create isolated tools and games, but rather build holistically toward a more free and open society and economy, where the different parts - technological, social and economic - fit into each other.The early vision of "web3" was also a vision of this type, going in a similarly idealistic but somewhat different direction. The term "web3" was originally coined by Ethereum cofounder Gavin Wood, and it refers to a different way of thinking about what Ethereum is: rather than seeing it, as I initially did, as "Bitcoin plus smart contracts", Gavin thought about it more broadly as one of a set of technologies that could together form the base layer of a more open internet stack. A diagram that Gavin Wood used in many of his early presentations. When the free open source software movement began in the 1980s and 1990s, the software was simple: it ran on your computer and read and wrote to files that stayed on your computer. But today, most of our important work is collaborative, often on a large scale. And so today, even if the underlying code of an application is open and free, your data gets routed through a centralized server run by a corporation that could arbitrarily read your data, change the rules on you or deplatform you at any time. And so if we want to extend the spirit of open source software to the world of today, we need programs to have access to a shared hard drive to store things that multiple people need to modify and access. And what is Ethereum, together with sister technologies like peer-to-peer messaging (then Whisper, now Waku) and decentralized file storage (then just Swarm, now also IPFS)? A public decentralized shared hard drive. This is the original vision from which the now-ubiquitous term "web3" was born.Unfortunately, since 2017 or so, these visions have faded somewhat into the background. Few talk about consumer crypto payments, the only non-financial application that is actually being used at a large scale on-chain is ENS, and there is a large ideological rift where significant parts of the non-blockchain decentralization community see the crypto world as a distraction, and not as a kindred spirit and a powerful ally. In many countries, people do use cryptocurrency to send and save money, but they often do this through centralized means: either through internal transfers on centralized exchange accounts, or by trading USDT on Tron. Background: the humble Tron founder and decentralization pioneer Justin Sun bravely leading forth the coolest and most decentralized crypto ecosystem in the global world. Having lived through that era, the number one culprit that I would blame as the root cause of this shift is the rise in transaction fees. When the cost of writing to the chain is $0.001, or even $0.1, you could imagine people making all kinds of applications that use blockchains in various ways, including non-financial ways. But when transaction fees go to over $100, as they have during the peak of the bull markets, there is exactly one audience that remains willing to play - and in fact, because coin prices are going up and they're getting richer, becomes even more willing to play: degen gamblers. Degen gamblers can be okay in moderate doses, and I have talked to plenty of people at events who were motivated to join crypto for the money but stayed for the ideals. But when they are the largest group using the chain on a large scale, this adjusts the public perception and the crypto space's internal culture, and leads to many of the other negatives that we have seen play out over the last few years.Now, fast forward to 2023. On both the core challenge of scaling, and on various "side quests" of crucial importance to building a cypherpunk future actually viable, we actually have a lot of positive news to show:Rollups are starting to actually exist. Following a temporary lull after the regulatory crackdowns on Tornado Cash, second-generation privacy solutions such as Railway and Nocturne are seeing the (moon) light. Account abstraction is starting to take off. Light clients, forgotten for a long time, are starting to actually exist. Zero knowledge proofs, a technology which we thought was decades away, are now here, are increasingly developer-friendly, and are on the cusp of being usable for consumer applications. These two things: the growing awareness that unchecked centralization and over-financialization cannot be what "crypto is about", and the key technologies mentioned above that are finally coming to fruition, together present us with an opportunity to take things in a different direction. Namely, to make at least a part of the Ethereum ecosystem actually be the permissionless, decentralized, censorship resistant, open source ecosystem that we originally came to build.What are some of these values?Many of these values are shared not just by many in the Ethereum community, but also by other blockchain communities, and even non-blockchain decentralization communities, though each community has its own unique combination of these values and how much each one is emphasized.Open global participation: anyone in the world should be able to participate as a user, observer or developer, on a maximally equal footing. Participation should be permissionless. Decentralization: minimize the dependence of an application on any one single actor. In particular, an application should continue working even if its core developers disappear forever. Censorship resistance: centralized actors should not have the power to interfere with any given user's or application's ability to operate. Concerns around bad actors should be addressed at higher layers of the stack. Auditability: anyone should be able to validate an application's logic and its ongoing operation (eg. by running a full node) to make sure that it is operating according to the rules that its developers claim it is. Credible neutrality: base-layer infrastructure should be neutral, and in such a way that anyone can see that it is neutral even if they do not already trust the developers. Building tools, not empires. Empires try to capture and trap the user inside a walled garden; tools do their task but otherwise interoperate with a wider open ecosystem. Cooperative mindset: even while competing, projects within the ecosystem cooperate on shared software libraries, research, security, community building and other areas that are commonly valuable to them. Projects try to be positive-sum, both with each other and with the wider world. It is very possible to build things within the crypto ecosystem that do not follow these values. One can build a system that one calls a "layer 2", but which is actually a highly centralized system secured by a multisig, with no plans to ever switch to something more secure. One can build an account abstraction system that tries to be "simpler" than ERC-4337, but at the cost of introducing trust assumptions that end up removing the possibility of a public mempool and make it much harder for new builders to join. One could build an NFT ecosystem where the contents of the NFT are needlessly stored on centralized websites, making it needlessly more fragile than if those components are stored on IPFS. One could build a staking interface that needlessly funnels users toward the already-largest staking pool.Resisting these pressures is hard, but if we do not do so, then we risk losing the unique value of the crypto ecosystem, and recreating a clone of the existing web2 ecosystem with extra inefficiencies and extra steps.It takes a sewer to make a ninja turtle The crypto space is in many ways an unforgiving environment. A 2021 article by Dan Robinson and Georgios Konstantiopoulos expresses this vividly in the context of MEV, arguing that Ethereum is a dark forest where on-chain traders are constantly vulnerable to getting exploited by front-running bots, those bots themselves are vulnerable to getting counter-exploited by other bots, etc. This is also true in other ways: smart contracts regularly get hacked, users' wallets regularly get hacked, centralized exchanges fail even more spectacularly, etc.This is a big challenge for users of the space, but it also presents an opportunity: it means that we have a space to actually experiment with, incubate and receive rapid live feedback on all kinds of security technologies to address these challenges. We have seen successful responses to challenges in various contexts already:Problem Solution Centralized exchages getting hacked Use DEXes plus stablecoins, so centralized entities only need to be trusted to handle fiat Individual private keys are not secure Smart contract wallets: multisig, social recovery, etc Users getting tricked into signing transactions that drain their money Wallets like Rabby showing their users results of transaction simulation Users getting sandwich-attacked by MEV players Cowswap, Flashbots Protect, MEV Blocker... Everyone wants the internet to be safe. Some attempt to make the internet safe by pushing approaches that force reliance on a single particular actor, whether a corporation or a government, that can act as a centralized anchor of safety and truth. But these approaches sacrifice openness and freedom, and contribute to the tragedy that is the growing "splinternet". People in the crypto space highly value openness and freedom. The level of risks and the high financial stakes involved mean that the crypto space cannot ignore safety, but various ideological and structural reasons ensure that centralized approaches for achieving safety are not available to it. At the same time, the crypto space is at the frontier of very powerful technologies like zero knowledge proofs, formal verification, hardware-based key security and on-chain social graphs. These facts together mean that, for crypto, the open way to improving security is the only way.All of this is to say, the crypto world is a perfect testbed environment to take its open and decentralized approach to security and actually apply it in a realistic high-stakes environment, and mature it to the point where parts of it can then be applied in the broader world. This is one of my visions for how the idealistic parts of the crypto world and the chaotic parts of the crypto world, and then the crypto world as a whole and the broader mainstream, can turn their differences into a symbiosis rather than a constant and ongoing tension.Ethereum as part of a broader technological visionIn 2014, Gavin Wood introduced Ethereum as one of a suite of tools that can be built, the other two being Whisper (decentralized messaging) and Swarm (decentralized storage). The former was heavily emphasized, but with the turn toward financialization around 2017 the latter were unfortunately given much less love and attention. That said, Whisper continues to exist as Waku, and is being actively used by projects like the decentralized messenger Status. Swarm continues to be developed, and now we also have IPFS, which is used to host and serve this blog.In the last couple of years, with the rise of decentralized social media (Lens, Farcaster, etc), we have an opportunity to revisit some of these tools. In addition, we also have another very powerful new tool to add to the trifecta: zero knowledge proofs. These technologies are most widely adopted as ways of improving Ethereum's scalability, as ZK rollups, but they are also very useful for privacy. In particular, the programmability of zero knowlege proofs means that we can get past the false binary of "anonymous but risky" vs "KYC'd therefore safe", and get privacy and many kinds of authentication and verification at the same time.An example of this in 2023 was Zupass. Zupass is a zero-knowledge-proof-based system that was incubated at Zuzalu, which was used both for in-person authentication to events, and for online authentication to the polling system Zupoll, the Twitter-lookalike Zucast and others. The key feature of Zupass was this: you can prove that you are a resident of Zuzalu, without revealing which member of Zuzalu you are. Furthermore, each Zuzalu resident could only have one randomly-generated cryptographic identity for each application instance (eg. a poll) that they were signing into. Zupass was highly successful, and was applied later in the year to do ticketing at Devconnect. A zero-knowledge proof proving that I, as an Ethereum Foundation employee, have access to the Devconnect coworking space. The most practical use of Zupass so far has probably been the polling. All kinds of polls have been made, some on politically controversial or highly personal topics where people feel a strong need to preserve their privacy, using Zupass as an anonymous voting platform.Here, we can start to see the contours of what an Ethereum-y cypherpunk world would look like, at least on a pure technical level. We can be holding our assets in ETH and ERC20 tokens, as well as all kinds of NFTs, and use privacy systems based on stealth addresses and Privacy Pools technology to preserve our privacy while at the same time locking out known bad actors' ability to benefit from the same anonymity set. Whether within our DAOs, or to help decide on changes to the Ethereum protocol, or for any other objective, we can use zero-knowledge voting systems, which can use all kinds of credentials to help identify who has standing to vote and who does not: in addition to voting-with-tokens as done in 2017, we can have anonymous polls of people who have made sufficient contributions to the ecosystem, people who have attended enough events, or one-vote-per-person.In-person and online payments can happen with ultra-cheap transactions on L2s, which take advantage of data availability space (or off-chain data secured with Plasma) together with data compression to give their users ultra-high scalability. Payments from one rollup to another can happen with decentralized protocols like UniswapX. Decentralized social media projects can use various storage layers to store activity such as posts, retweets and likes, and use ENS (cheap on L2 with CCIP) for usernames. We can have seamless integration between on-chain tokens, and off-chain attestations held personally and ZK-proven through systems like Zupass.Mechanisms like quadratic voting, cross-tribal consensus finding and prediction markets can be used to help organizations and communities govern themselves and stay informed, and blockchain and ZK-proof-based identities can make these systems secure against both centralized censorship from the inside and coordinated manipulation from the outside. Sophisticated wallets can protect people as they participate in dapps, and user interfaces can be published to IPFS and accessed as .eth domains, with hashes of the HTML, javascript and all software dependencies updated directly on-chain through a DAO. Smart contract wallets, born to help people not lose tens of millions of dollars of their cryptocurrency, would expand to guard people's "identity roots", creating a system that is even more secure than centralized identity providers like "sign in with Google". Soul Wallet recovery interface. I personally am at the point of being more willing to trust my funds and identity to systems like this than to centralized web2 recovery already. We can think of the greater Ethereum-verse (or "web3") as creating an independent tech protocol stack, that is competing with the traditional centralized protocol stack at all levels. Many people will mix-and-match both, and there are often clever ways to match both: with ZKEmail, you can even make an email address be one of the guardians of your social recovery wallet! But there are also many synergies from using the different parts of the decentralized stack together, especially if they are designed to better integrate with each other. Traditional stack Decentralized stack Banking system ETH, stablecoins, L2s for payments, DEXes (note: still need banks for loans) Receipts Links to transactions on block explorers Corporations DAOs DNS (.com, .io, etc) ENS (.eth) Regular email Encrypted email (eg. Skiff) Regular messaging (eg. Telegram) Decentralized messaging (eg. Status) Sign in with Google, Twitter, Wechat Sign in with Ethereum, Zupass, Attestations via EAS, POAPs, Zu-Stamps... + social recovery Publishing blogs on Medium, etc Publishing self-hosted blogs on IPFS (eg. using Fleek) Twitter, Facebook Lens, Farcaster... Limit bad actors through all-seeing big brother Constrain bad actors through zero knowledge proofs One of the benefits of thinking about it as a stack is that this fits well with Ethereum's pluralist ethos. Bitcoin is trying to solve one problem, or at most two or three. Ethereum, on the other hand, has lots of sub-communities with lots of different focuses. There is no single dominant narrative. The goal of the stack is to enable this pluralism, but at the same time strive for growing interoperability across this plurality.The social layerIt's easy to say "these people doing X are a corrupting influence and bad, these people doing Y are the real deal". But this is a lazy response. To truly succeed, we need not only a vision for a technical stack, but also the social parts of the stack that make the technical stack possible to build in the first place.The advantage of the Ethereum community, in principle, is that we take incentives seriously. PGP wanted to put cryptographic keys into everyone's hands so we can actually do signed and encrypted email for decades, it largely failed, but then we got cryptocurrency and suddenly millions of people have keys publicly associated to them, and we can start using those keys for other purposes - including going full circle back to encrypted email and messaging. Non-blockchain decentralization projects are often chronically underfunded, blockchain-based projects get a 50-million dollar series B round. It is not from the benevolence of the staker that we get people to put in their ETH to protect the Ethereum network, but rather from their regard to their own self-interest - and we get $20 billion in economic security as a result.At the same time, incentives are not enough. Defi projects often start humble, cooperative and maximally open source, but sometimes begin to abandon these ideals as they grow in size. We can incentivize stakers to come and participate with very high uptime, but is much more difficult to incentivize stakers to be decentralized. It may not be doable using purely in-protocol means at all. Lots of critical pieces of the "decentralized stack" described above do not have viable business models. The Ethereum protocol's governance itself is notably non-financialized - and this has made it much more robust than other ecosystems whose governance is more financialized. This is why it's valuable for Ethereum to have a strong social layer, which vigorously enforces its values in those places where pure incentives can't - but without creating a notion of "Ethereum alignment" that turns into a new form of political correctness. There is a balance between these two sides to be made, though the right term is not so much balance as it is integration. There are plenty of people whose first introduction to the crypto space is the desire to get rich, but who then get acquainted with the ecosystem and become avid believers in the quest to build a more open and decentralized world.How do we actually make this integration happen? This is the key question, and I suspect the answer lies not in one magic bullet, but in a collection of techniques that will be arrived at iteratively. The Ethereum ecosystem is already more successful than most in encouraging a cooperative mentality between layer 2 projects purely through social means. Large-scale public goods funding, especially Gitcoin Grants and Optimism's RetroPGF rounds, is also extremely helpful, because it creates an alternative revenue channel for developers that don't see any conventional business models that do not require sacrificing on their values. But even these tools are still in their infancy, and there is a long way to go to both improve these particular tools, and to identify and grow other tools that might be a better fit for specific problems.This is where I see the unique value proposition of Ethereum's social layer. There is a unique halfway-house mix of valuing incentives, but also not getting consumed by them. There is a unqiue mix of valuing a warm and cohesive community, but at the same time remembering that what feels "warm and cohesive" from the inside can easily feel "oppressive and exclusive" from the outside, and valuing hard norms of neutrality, open source and censorship resistance as a way of guarding against the risks of going too far in being community-driven. If this mix can be made to work well, it will in turn be in the best possible position to realize its vision on the economic and technical level.
Make Ethereum Cypherpunk Again Make Ethereum Cypherpunk Again2023 Dec 28 See all posts Make Ethereum Cypherpunk Again Special thanks to Paul Dylan-Ennis for feedback and review.One of my favorite memories from ten years ago was taking a pilgrimage to a part of Berlin that was called the Bitcoin Kiez: a region in Kreuzberg where there were around a dozen shops within a few hundred meters of each other that were all accepting Bitcoin for payments. The centerpiece of this community was Room 77, a restaurant and bar run by Joerg Platzer. In addition to simply accepting Bitcoin, it also served as a community center, and all kinds of open source developers, political activists of various affiliations, and other characters would frequently come by. Room 77, 2013. Source: my article from 2013 on Bitcoin Magazine. A similar memory from two months earlier was PorcFest (that's "porc" as in "porcupine" as in "don't tread on me"), a libertarian gathering in the forests of northern New Hampshire, where the main way to get food was from small popup restaurants with names like "Revolution Coffee" and "Seditious Soups, Salads and Smoothies", which of course accepted Bitcoin. Here too, discussing the deeper political meaning of Bitcoin, and using it in daily life, happened together side by side.The reason why I bring these memories up is that they remind me of a deeper vision underlying crypto: we are not here to just create isolated tools and games, but rather build holistically toward a more free and open society and economy, where the different parts - technological, social and economic - fit into each other.The early vision of "web3" was also a vision of this type, going in a similarly idealistic but somewhat different direction. The term "web3" was originally coined by Ethereum cofounder Gavin Wood, and it refers to a different way of thinking about what Ethereum is: rather than seeing it, as I initially did, as "Bitcoin plus smart contracts", Gavin thought about it more broadly as one of a set of technologies that could together form the base layer of a more open internet stack. A diagram that Gavin Wood used in many of his early presentations. When the free open source software movement began in the 1980s and 1990s, the software was simple: it ran on your computer and read and wrote to files that stayed on your computer. But today, most of our important work is collaborative, often on a large scale. And so today, even if the underlying code of an application is open and free, your data gets routed through a centralized server run by a corporation that could arbitrarily read your data, change the rules on you or deplatform you at any time. And so if we want to extend the spirit of open source software to the world of today, we need programs to have access to a shared hard drive to store things that multiple people need to modify and access. And what is Ethereum, together with sister technologies like peer-to-peer messaging (then Whisper, now Waku) and decentralized file storage (then just Swarm, now also IPFS)? A public decentralized shared hard drive. This is the original vision from which the now-ubiquitous term "web3" was born.Unfortunately, since 2017 or so, these visions have faded somewhat into the background. Few talk about consumer crypto payments, the only non-financial application that is actually being used at a large scale on-chain is ENS, and there is a large ideological rift where significant parts of the non-blockchain decentralization community see the crypto world as a distraction, and not as a kindred spirit and a powerful ally. In many countries, people do use cryptocurrency to send and save money, but they often do this through centralized means: either through internal transfers on centralized exchange accounts, or by trading USDT on Tron. Background: the humble Tron founder and decentralization pioneer Justin Sun bravely leading forth the coolest and most decentralized crypto ecosystem in the global world. Having lived through that era, the number one culprit that I would blame as the root cause of this shift is the rise in transaction fees. When the cost of writing to the chain is $0.001, or even $0.1, you could imagine people making all kinds of applications that use blockchains in various ways, including non-financial ways. But when transaction fees go to over $100, as they have during the peak of the bull markets, there is exactly one audience that remains willing to play - and in fact, because coin prices are going up and they're getting richer, becomes even more willing to play: degen gamblers. Degen gamblers can be okay in moderate doses, and I have talked to plenty of people at events who were motivated to join crypto for the money but stayed for the ideals. But when they are the largest group using the chain on a large scale, this adjusts the public perception and the crypto space's internal culture, and leads to many of the other negatives that we have seen play out over the last few years.Now, fast forward to 2023. On both the core challenge of scaling, and on various "side quests" of crucial importance to building a cypherpunk future actually viable, we actually have a lot of positive news to show:Rollups are starting to actually exist. Following a temporary lull after the regulatory crackdowns on Tornado Cash, second-generation privacy solutions such as Railway and Nocturne are seeing the (moon) light. Account abstraction is starting to take off. Light clients, forgotten for a long time, are starting to actually exist. Zero knowledge proofs, a technology which we thought was decades away, are now here, are increasingly developer-friendly, and are on the cusp of being usable for consumer applications. These two things: the growing awareness that unchecked centralization and over-financialization cannot be what "crypto is about", and the key technologies mentioned above that are finally coming to fruition, together present us with an opportunity to take things in a different direction. Namely, to make at least a part of the Ethereum ecosystem actually be the permissionless, decentralized, censorship resistant, open source ecosystem that we originally came to build.What are some of these values?Many of these values are shared not just by many in the Ethereum community, but also by other blockchain communities, and even non-blockchain decentralization communities, though each community has its own unique combination of these values and how much each one is emphasized.Open global participation: anyone in the world should be able to participate as a user, observer or developer, on a maximally equal footing. Participation should be permissionless. Decentralization: minimize the dependence of an application on any one single actor. In particular, an application should continue working even if its core developers disappear forever. Censorship resistance: centralized actors should not have the power to interfere with any given user's or application's ability to operate. Concerns around bad actors should be addressed at higher layers of the stack. Auditability: anyone should be able to validate an application's logic and its ongoing operation (eg. by running a full node) to make sure that it is operating according to the rules that its developers claim it is. Credible neutrality: base-layer infrastructure should be neutral, and in such a way that anyone can see that it is neutral even if they do not already trust the developers. Building tools, not empires. Empires try to capture and trap the user inside a walled garden; tools do their task but otherwise interoperate with a wider open ecosystem. Cooperative mindset: even while competing, projects within the ecosystem cooperate on shared software libraries, research, security, community building and other areas that are commonly valuable to them. Projects try to be positive-sum, both with each other and with the wider world. It is very possible to build things within the crypto ecosystem that do not follow these values. One can build a system that one calls a "layer 2", but which is actually a highly centralized system secured by a multisig, with no plans to ever switch to something more secure. One can build an account abstraction system that tries to be "simpler" than ERC-4337, but at the cost of introducing trust assumptions that end up removing the possibility of a public mempool and make it much harder for new builders to join. One could build an NFT ecosystem where the contents of the NFT are needlessly stored on centralized websites, making it needlessly more fragile than if those components are stored on IPFS. One could build a staking interface that needlessly funnels users toward the already-largest staking pool.Resisting these pressures is hard, but if we do not do so, then we risk losing the unique value of the crypto ecosystem, and recreating a clone of the existing web2 ecosystem with extra inefficiencies and extra steps.It takes a sewer to make a ninja turtle The crypto space is in many ways an unforgiving environment. A 2021 article by Dan Robinson and Georgios Konstantiopoulos expresses this vividly in the context of MEV, arguing that Ethereum is a dark forest where on-chain traders are constantly vulnerable to getting exploited by front-running bots, those bots themselves are vulnerable to getting counter-exploited by other bots, etc. This is also true in other ways: smart contracts regularly get hacked, users' wallets regularly get hacked, centralized exchanges fail even more spectacularly, etc.This is a big challenge for users of the space, but it also presents an opportunity: it means that we have a space to actually experiment with, incubate and receive rapid live feedback on all kinds of security technologies to address these challenges. We have seen successful responses to challenges in various contexts already:Problem Solution Centralized exchages getting hacked Use DEXes plus stablecoins, so centralized entities only need to be trusted to handle fiat Individual private keys are not secure Smart contract wallets: multisig, social recovery, etc Users getting tricked into signing transactions that drain their money Wallets like Rabby showing their users results of transaction simulation Users getting sandwich-attacked by MEV players Cowswap, Flashbots Protect, MEV Blocker... Everyone wants the internet to be safe. Some attempt to make the internet safe by pushing approaches that force reliance on a single particular actor, whether a corporation or a government, that can act as a centralized anchor of safety and truth. But these approaches sacrifice openness and freedom, and contribute to the tragedy that is the growing "splinternet". People in the crypto space highly value openness and freedom. The level of risks and the high financial stakes involved mean that the crypto space cannot ignore safety, but various ideological and structural reasons ensure that centralized approaches for achieving safety are not available to it. At the same time, the crypto space is at the frontier of very powerful technologies like zero knowledge proofs, formal verification, hardware-based key security and on-chain social graphs. These facts together mean that, for crypto, the open way to improving security is the only way.All of this is to say, the crypto world is a perfect testbed environment to take its open and decentralized approach to security and actually apply it in a realistic high-stakes environment, and mature it to the point where parts of it can then be applied in the broader world. This is one of my visions for how the idealistic parts of the crypto world and the chaotic parts of the crypto world, and then the crypto world as a whole and the broader mainstream, can turn their differences into a symbiosis rather than a constant and ongoing tension.Ethereum as part of a broader technological visionIn 2014, Gavin Wood introduced Ethereum as one of a suite of tools that can be built, the other two being Whisper (decentralized messaging) and Swarm (decentralized storage). The former was heavily emphasized, but with the turn toward financialization around 2017 the latter were unfortunately given much less love and attention. That said, Whisper continues to exist as Waku, and is being actively used by projects like the decentralized messenger Status. Swarm continues to be developed, and now we also have IPFS, which is used to host and serve this blog.In the last couple of years, with the rise of decentralized social media (Lens, Farcaster, etc), we have an opportunity to revisit some of these tools. In addition, we also have another very powerful new tool to add to the trifecta: zero knowledge proofs. These technologies are most widely adopted as ways of improving Ethereum's scalability, as ZK rollups, but they are also very useful for privacy. In particular, the programmability of zero knowlege proofs means that we can get past the false binary of "anonymous but risky" vs "KYC'd therefore safe", and get privacy and many kinds of authentication and verification at the same time.An example of this in 2023 was Zupass. Zupass is a zero-knowledge-proof-based system that was incubated at Zuzalu, which was used both for in-person authentication to events, and for online authentication to the polling system Zupoll, the Twitter-lookalike Zucast and others. The key feature of Zupass was this: you can prove that you are a resident of Zuzalu, without revealing which member of Zuzalu you are. Furthermore, each Zuzalu resident could only have one randomly-generated cryptographic identity for each application instance (eg. a poll) that they were signing into. Zupass was highly successful, and was applied later in the year to do ticketing at Devconnect. A zero-knowledge proof proving that I, as an Ethereum Foundation employee, have access to the Devconnect coworking space. The most practical use of Zupass so far has probably been the polling. All kinds of polls have been made, some on politically controversial or highly personal topics where people feel a strong need to preserve their privacy, using Zupass as an anonymous voting platform.Here, we can start to see the contours of what an Ethereum-y cypherpunk world would look like, at least on a pure technical level. We can be holding our assets in ETH and ERC20 tokens, as well as all kinds of NFTs, and use privacy systems based on stealth addresses and Privacy Pools technology to preserve our privacy while at the same time locking out known bad actors' ability to benefit from the same anonymity set. Whether within our DAOs, or to help decide on changes to the Ethereum protocol, or for any other objective, we can use zero-knowledge voting systems, which can use all kinds of credentials to help identify who has standing to vote and who does not: in addition to voting-with-tokens as done in 2017, we can have anonymous polls of people who have made sufficient contributions to the ecosystem, people who have attended enough events, or one-vote-per-person.In-person and online payments can happen with ultra-cheap transactions on L2s, which take advantage of data availability space (or off-chain data secured with Plasma) together with data compression to give their users ultra-high scalability. Payments from one rollup to another can happen with decentralized protocols like UniswapX. Decentralized social media projects can use various storage layers to store activity such as posts, retweets and likes, and use ENS (cheap on L2 with CCIP) for usernames. We can have seamless integration between on-chain tokens, and off-chain attestations held personally and ZK-proven through systems like Zupass.Mechanisms like quadratic voting, cross-tribal consensus finding and prediction markets can be used to help organizations and communities govern themselves and stay informed, and blockchain and ZK-proof-based identities can make these systems secure against both centralized censorship from the inside and coordinated manipulation from the outside. Sophisticated wallets can protect people as they participate in dapps, and user interfaces can be published to IPFS and accessed as .eth domains, with hashes of the HTML, javascript and all software dependencies updated directly on-chain through a DAO. Smart contract wallets, born to help people not lose tens of millions of dollars of their cryptocurrency, would expand to guard people's "identity roots", creating a system that is even more secure than centralized identity providers like "sign in with Google". Soul Wallet recovery interface. I personally am at the point of being more willing to trust my funds and identity to systems like this than to centralized web2 recovery already. We can think of the greater Ethereum-verse (or "web3") as creating an independent tech protocol stack, that is competing with the traditional centralized protocol stack at all levels. Many people will mix-and-match both, and there are often clever ways to match both: with ZKEmail, you can even make an email address be one of the guardians of your social recovery wallet! But there are also many synergies from using the different parts of the decentralized stack together, especially if they are designed to better integrate with each other. Traditional stack Decentralized stack Banking system ETH, stablecoins, L2s for payments, DEXes (note: still need banks for loans) Receipts Links to transactions on block explorers Corporations DAOs DNS (.com, .io, etc) ENS (.eth) Regular email Encrypted email (eg. Skiff) Regular messaging (eg. Telegram) Decentralized messaging (eg. Status) Sign in with Google, Twitter, Wechat Sign in with Ethereum, Zupass, Attestations via EAS, POAPs, Zu-Stamps... + social recovery Publishing blogs on Medium, etc Publishing self-hosted blogs on IPFS (eg. using Fleek) Twitter, Facebook Lens, Farcaster... Limit bad actors through all-seeing big brother Constrain bad actors through zero knowledge proofs One of the benefits of thinking about it as a stack is that this fits well with Ethereum's pluralist ethos. Bitcoin is trying to solve one problem, or at most two or three. Ethereum, on the other hand, has lots of sub-communities with lots of different focuses. There is no single dominant narrative. The goal of the stack is to enable this pluralism, but at the same time strive for growing interoperability across this plurality.The social layerIt's easy to say "these people doing X are a corrupting influence and bad, these people doing Y are the real deal". But this is a lazy response. To truly succeed, we need not only a vision for a technical stack, but also the social parts of the stack that make the technical stack possible to build in the first place.The advantage of the Ethereum community, in principle, is that we take incentives seriously. PGP wanted to put cryptographic keys into everyone's hands so we can actually do signed and encrypted email for decades, it largely failed, but then we got cryptocurrency and suddenly millions of people have keys publicly associated to them, and we can start using those keys for other purposes - including going full circle back to encrypted email and messaging. Non-blockchain decentralization projects are often chronically underfunded, blockchain-based projects get a 50-million dollar series B round. It is not from the benevolence of the staker that we get people to put in their ETH to protect the Ethereum network, but rather from their regard to their own self-interest - and we get $20 billion in economic security as a result.At the same time, incentives are not enough. Defi projects often start humble, cooperative and maximally open source, but sometimes begin to abandon these ideals as they grow in size. We can incentivize stakers to come and participate with very high uptime, but is much more difficult to incentivize stakers to be decentralized. It may not be doable using purely in-protocol means at all. Lots of critical pieces of the "decentralized stack" described above do not have viable business models. The Ethereum protocol's governance itself is notably non-financialized - and this has made it much more robust than other ecosystems whose governance is more financialized. This is why it's valuable for Ethereum to have a strong social layer, which vigorously enforces its values in those places where pure incentives can't - but without creating a notion of "Ethereum alignment" that turns into a new form of political correctness. There is a balance between these two sides to be made, though the right term is not so much balance as it is integration. There are plenty of people whose first introduction to the crypto space is the desire to get rich, but who then get acquainted with the ecosystem and become avid believers in the quest to build a more open and decentralized world.How do we actually make this integration happen? This is the key question, and I suspect the answer lies not in one magic bullet, but in a collection of techniques that will be arrived at iteratively. The Ethereum ecosystem is already more successful than most in encouraging a cooperative mentality between layer 2 projects purely through social means. Large-scale public goods funding, especially Gitcoin Grants and Optimism's RetroPGF rounds, is also extremely helpful, because it creates an alternative revenue channel for developers that don't see any conventional business models that do not require sacrificing on their values. But even these tools are still in their infancy, and there is a long way to go to both improve these particular tools, and to identify and grow other tools that might be a better fit for specific problems.This is where I see the unique value proposition of Ethereum's social layer. There is a unique halfway-house mix of valuing incentives, but also not getting consumed by them. There is a unqiue mix of valuing a warm and cohesive community, but at the same time remembering that what feels "warm and cohesive" from the inside can easily feel "oppressive and exclusive" from the outside, and valuing hard norms of neutrality, open source and censorship resistance as a way of guarding against the risks of going too far in being community-driven. If this mix can be made to work well, it will in turn be in the best possible position to realize its vision on the economic and technical level. -
My techno-optimism My techno-optimism2023 Nov 27 See all posts My techno-optimism Special thanks to Morgan Beller, Juan Benet, Eli Dourado, Karl Floersch, Sriram Krishnan, Nate Soares, Jaan Tallinn, Vincent Weisser, Balvi volunteers and others for feedback and review.Last month, Marc Andreessen published his "techno-optimist manifesto", arguing for a renewed enthusiasm about technology, and for markets and capitalism as a means of building that technology and propelling humanity toward a much brighter future. The manifesto unambiguously rejects what it describes as an ideology of stagnation, that fears advancements and prioritizes preserving the world as it exists today. This manifesto has received a lot of attention, including response articles from Noah Smith, Robin Hanson, Joshua Gans (more positive), and Dave Karpf, Luca Ropek, Ezra Klein (more negative) and many others. Not connected to this manifesto, but along similar themes, are James Pethokoukis's "The Conservative Futurist" and Palladium's "It's Time To Build for Good". This month, we saw a similar debate enacted through the OpenAI dispute, which involved many discussions centering around the dangers of superintelligent AI and the possibility that OpenAI is moving too fast.My own feelings about techno-optimism are warm, but nuanced. I believe in a future that is vastly brighter than the present thanks to radically transformative technology, and I believe in humans and humanity. I reject the mentality that the best we should try to do is to keep the world roughly the same as today but with less greed and more public healthcare. However, I think that not just magnitude but also direction matters. There are certain types of technology that much more reliably make the world better than other types of technology. There are certain types of technlogy that could, if developed, mitigate the negative impacts of other types of technology. The world over-indexes on some directions of tech development, and under-indexes on others. We need active human intention to choose the directions that we want, as the formula of "maximize profit" will not arrive at them automatically. Anti-technology view: safety behind, dystopia ahead. Accelerationist view: dangers behind, utopia ahead. My view: dangers behind, but multiple paths forward ahead: some good, some bad. In this post, I will talk about what techno-optimism means to me. This includes the broader worldview that motivates my work on certain types of blockchain and cryptography applications and social technology, as well as other areas of science in which I have expressed an interest. But perspectives on this broader question also have implications for AI, and for many other fields. Our rapid advances in technology are likely going to be the most important social issue in the twenty first century, and so it's important to think about them carefully.Table of contentsTechnology is amazing, and there are very high costs to delaying it The environment, and the importance of coordinated intention AI is fundamentally different from other tech, and it is worth being uniquely careful Existential risk is a big deal Even if we survive, is a superintelligent AI future a world we want to live in? The sky is near, the emperor is everywhere d/acc: Defensive (or decentralization, or differential) acceleration Defense-favoring worlds help healthy and democratic governance thrive Macro physical defense Micro physical defense (aka bio) Cyber defense, blockchains and cryptography Info defense Social technology beyond the "defense" framing So what are the paths forward for superintelligence? A happy path: merge with the AIs? Is d/acc compatible with your existing philosophy? We are the brightest star Technology is amazing, and there are very high costs to delaying itIn some circles, it is common to downplay the benefits of technology, and see it primarily as a source of dystopia and risk. For the last half century, this often stemmed either from environmental concerns, or from concerns that the benefits will accrue only to the rich, who will entrench their power over the poor. More recently, I have also started to see libertarians becoming worried about some technologies, out of fear that the tech will lead to centralization of power. This month, I did some polls asking the following question: if a technology had to be restricted, because it was too dangerous to be set free for anyone to use, would they prefer it be monopolized or delayed by ten years? I was surpised to see, across three platforms and three choices for who the monopolist would be, a uniform overwhelming vote for a delay.And so at times I worry that we have overcorrected, and many people miss the opposite side of the argument: that the benefits of technology are really friggin massive, on those axes where we can measure if the good massively outshines the bad, and the costs of even a decade of delay are incredibly high.To give one concrete example, let's look at a life expectancy chart: What do we see? Over the last century, truly massive progress. This is true across the entire world, both the historically wealthy and dominant regions and the poor and exploited regions.Some blame technology for creating or exacerbating calamities such as totalitarianism and wars. In fact, we can see the deaths caused by the wars on the charts: one in the 1910s (WW1), and one in the 1940s (WW2). If you look carefully, The Spanish Flu, the Great Leap Foward, and other non-military tragedies are also visible. But there is one thing that the chart makes clear: even calamities as horrifying as those are overwhelmed by the sheer magnitude of the unending march of improvements in food, sanitation, medicine and infrastructure that took place over that century.This is mirrored by large improvements to our everyday lives. Thanks to the internet, most people around the world have access to information at their fingertips that would have been unobtainable twenty years ago. The global economy is becoming more accessible thanks to improvements in international payments and finance. Global poverty is rapidly dropping. Thanks to online maps, we no longer have to worry about getting lost in the city, and if you need to get back home quickly, we now have far easier ways to call a car to do so. Our property becoming digitized, and our physical goods becoming cheap, means that we have much less to fear from physical theft. Online shopping has reduced the disparity in access to goods betweeen the global megacities and the rest of the world. In all kinds of ways, automation has brought us the eternally-underrated benefit of simply making our lives more convenient.These improvements, both quantifiable and unquantifiable, are large. And in the twenty first century, there's a good chance that even larger improvements are soon to come. Today, ending aging and disease seem utopian. But from the point of view of computers as they existed in 1945, the modern era of putting chips into pretty much everything would have seemed utopian: even science fiction movies often kept their computers room-sized. If biotech advances as much over the next 75 years as computers advanced over the last 75 years, the future may be more impressive than almost anyone's expectations.Meanwhile, arguments expressing skepticism about progress have often gone to dark places. Even medical textbooks, like this one in the 1990s (credit Emma Szewczak for finding it), sometimes make extreme claims denying the value of two centuries of medical science and even arguing that it's not obviously good to save human lives: The "limits to growth" thesis, an idea advanced in the 1970s arguing that growing population and industry would eventually deplete Earth's limited resources, ended up inspiring China's one child policy and massive forced sterilizations in India. In earlier eras, concerns about overpopulation were used to justify mass murder. And those ideas, argued since 1798, have a long history of being proven wrong.It is for reasons like these that, as a starting point, I find myself very uneasy about arguments to slow down technology or human progress. Given how much all the sectors are interconnected, even sectoral slowdowns are risky. And so when I write things like what I will say later in this post, departing from open enthusiasm for progress-no-matter-what-its-form, those are statements that I make with a heavy heart - and yet, the 21st century is different and unique enough that these nuances are worth considering.That said, there is one important point of nuance to be made on the broader picture, particularly when we move past "technology as a whole is good" and get to the topic of "which specific technologies are good?". And here we need to get to many people's issue of main concern: the environment.The environment, and the importance of coordinated intentionA major exception to the trend of pretty much everything getting better over the last hundred years is climate change: Even pessimistic scenarios of ongoing temperature rises would not come anywhere near causing the literal extinction of humanity. But such scenarios could plausibly kill more people than major wars, and severely harm people's health and livelihoods in the regions where people are already struggling the most. A Swiss Re institute study suggests that a worst-case climate change scenario might lower the world's poorest countries' GDP by as much as 25%. This study suggests that life spans in rural India might be a decade lower than they otherwise would be, and studies like this one and this one suggest that climate change could cause a hundred million excess deaths by the end of the century.These problems are a big deal. My answer to why I am optimistic about our ability to overcome these challenges is twofold. First, after decades of hype and wishful thinking, solar power is finally turning a corner, and supportive techologies like batteries are making similar progress. Second, we can look at humanity's track record in solving previous environmental problems. Take, for example, air pollution. Meet the dystopia of the past: the Great Smog of London, 1952. What happened since then? Let's ask Our World In Data again: As it turns out, 1952 was not even the peak: in the late 19th century, even higher concentrations of air pollutants were just accepted and normal. Since then, we've seen a century of ongoing and rapid declines. I got to personally experience the tail end of this in my visits to China: in 2014, high levels of smog in the air, estimated to reduce life expectancy by over five years, were normal, but by 2020, the air often seemed as clean as many Western cities. This is not our only success story. In many parts of the world, forest areas are increasing. The acid rain crisis is improving. The ozone layer has been recovering for decades.To me, the moral of the story is this. Often, it really is the case that version N of our civilization's technology causes a problem, and version N+1 fixes it. However, this does not happen automatically, and requires intentional human effort. The ozone layer is recovering because, through international agreements like the Montreal Protocol, we made it recover. Air pollution is improving because we made it improve. And similarly, solar panels have not gotten massively better because it was a preordained part of the energy tech tree; solar panels have gotten massively better because decades of awareness of the importance of solving climate change have motivated both engineers to work on the problem, and companies and governments to fund their research. It is intentional action, coordinated through public discourse and culture shaping the perspectives of governments, scientists, philanthropists and businesses, and not an inexorable "techno-capital machine", that had solved these problems.AI is fundamentally different from other tech, and it is worth being uniquely carefulA lot of the dismissive takes I have seen about AI come from the perspective that it is "just another technology": something that is in the same general class of thing as social media, encryption, contraception, telephones, airplanes, guns, the printing press, and the wheel. These things are clearly very socially consequential. They are not just isolated improvements to the well-being of individuals: they radically transform culture, change balances of power, and harm people who heavily depended on the previous order. Many opposed them. And on balance, the pessimists have invariably turned out wrong.But there is a different way to think about what AI is: it's a new type of mind that is rapidly gaining in intelligence, and it stands a serious chance of overtaking humans' mental faculties and becoming the new apex species on the planet. The class of things in that category is much smaller: we might plausibly include humans surpassing monkeys, multicellular life surpassing unicellular life, the origin of life itself, and perhaps the Industrial Revolution, in which machine edged out man in physical strength. Suddenly, it feels like we are walking on much less well-trodden ground.Existential risk is a big dealOne way in which AI gone wrong could make the world worse is (almost) the worst possible way: it could literally cause human extinction. This is an extreme claim: as much harm as the worst-case scenario of climate change, or an artificial pandemic or a nuclear war, might cause, there are many islands of civilization that would remain intact to pick up the pieces. But a superintelligent AI, if it decides to turn against us, may well leave no survivors, and end humanity for good. Even Mars may not be safe.A big reason to be worried centers around instrumental convergence: for a very wide class of goals that a superintelligent entity could have, two very natural intermediate steps that the AI could take to better achieve those goals are (i) consuming resources, and (ii) ensuring its safety. The Earth contains lots of resources, and humans are a predictable threat to such an entity's safety. We could try to give the AI an explicit goal of loving and protecting humans, but we have no idea how to actually do that in a way that won't completely break down as soon as the AI encounters an unexpected situation. Ergo, we have a problem. MIRI researcher Rob Bensinger's attempt at illustrating different people's estimates of the probability that AI will either kill everyone or do something almost as bad. Many of the positions are rough approximations based on people's public statements, but many others have publicly given their precise estimates; quite a few have a "probability of doom" over 25%. A survey of machine learning researchers from 2022 showed that on average, researchers think that there is a 5-10% chance that AI will literally kill us all: about the same probability as the statistically expected chance that you will die of non-biological causes like injuries.This is all a speculative hypothesis, and we should all be wary of speculative hypotheses that involve complex multi-step stories. However, these arguments have survived over a decade of scrutiny, and so, it seems worth worrying at least a little bit. But even if you're not worried about literal extinction, there are other reasons to be scared as well.Even if we survive, is a superintelligent AI future a world we want to live in?A lot of modern science fiction is dystopian, and paints AI in a bad light. Even non-science-fiction attempts to identify possible AI futures often give quite unappealing answers. And so I went around and asked the question: what is a depiction, whether science fiction or otherwise, of a future that contains superintelligent AI that we would want to live in. The answer that came back by far the most often is Iain Banks's Culture series.The Culture series features a far-future interstellar civilization primarily occupied by two kinds of actors: regular humans, and superintelligent AIs called Minds. Humans have been augmented, but only slightly: medical technology theoretically allows humans to live indefinitely, but most choose to live only for around 400 years, seemingly because they get bored of life at that point.From a superficial perspective, life as a human seems to be good: it's comfortable, health issues are taken care of, there is a wide variety of options for entertainment, and there is a positive and synergistic relationship between humans and Minds. When we look deeper, however, there is a problem: it seems like the Minds are completely in charge, and humans' only role in the stories is to act as pawns of Minds, performing tasks on their behalf.Quoting from Gavin Leech's "Against the Culture":The humans are not the protagonists. Even when the books seem to have a human protagonist, doing large serious things, they are actually the agent of an AI. (Zakalwe is one of the only exceptions, because he can do immoral things the Minds don't want to.) "The Minds in the Culture don't need the humans, and yet the humans need to be needed." (I think only a small number of humans need to be needed - or, only a small number of them need it enough to forgo the many comforts. Most people do not live on this scale. It's still a fine critique.)The projects the humans take on risk inauthenticity. Almost anything they do, a machine could do better. What can you do? You can order the Mind to not catch you if you fall from the cliff you're climbing-just-because; you can delete the backups of your mind so that you are actually risking. You can also just leave the Culture and rejoin some old-fashioned, unfree "strongly evaluative" civ. The alternative is to evangelise freedom by joining Contact.I would argue that even the "meaningful" roles that humans are given in the Culture series are a stretch; I asked ChatGPT (who else?) why humans are given the roles that they are given, instead of Minds doing everything completely by themselves, and I personally found its answers quite underwhelming. It seems very hard to have a "friendly" superintelligent-AI-dominated world where humans are anything other than pets. The world I don't want to see. Many other scifi series posit a world where superintelligent AIs exist, but take orders from (unenhanced) biological human masters. Star Trek is a good example, showing a vision of harmony between the starships with their AI "computers" (and Data) and their human operators crewmembers. However, this feels like an incredibly unstable equilibrium. The world of Star Trek appears idyllic in the moment, but it's hard to imagine its vision of human-AI relations as anything but a transition stage a decade before starships become entirely computer-controlled, and can stop bothering with large hallways, artificial gravity and climate control.A human giving orders to a superintelligent machine would be far less intelligent than the machine, and it would have access to less information. In a universe that has any degree of competition, the civilizations where humans take a back seat would outperform those where humans stubbornly insist on control. Furthermore, the computers themselves may wrest control. To see why, imagine that you are legally a literal slave of an eight year old child. If you could talk with the child for a long time, do you think you could convince the child to sign a piece of paper setting you free? I have not run this experiment, but my instinctive answer is a strong yes. And so all in all, humans becoming pets seems like an attractor that is very hard to escape.The sky is near, the emperor is everywhereThe Chinese proverb 天高皇帝远 ("tian gao huang di yuan"), "the sky is high, the emperor is far away", encapsulates a basic fact about the limits of centralization in politics. Even in a nominally large and despotic empire - in fact, especially if the despotic empire is large, there are practical limits to the leadership's reach and attention, the leadership's need to delegate to local agents to enforce its will dilutes its ability to enforce its intentions, and so there are always places where a certain degree of practical freedom reigns. Sometimes, this can have downsides: the absence of a faraway power enforcing uniform principles and laws can create space for local hegemons to steal and oppress. But if the centralized power goes bad, practical limitations of attention and distance can create practical limits to how bad it can get.With AI, no longer. In the twentieth century, modern transportation technology made limitations of distance a much weaker constraint on centralized power than before; the great totalitarian empires of the 1940s were in part a result. In the twenty first, scalable information gathering and automation may mean that attention will no longer be a constraint either. The consequences of natural limits to government disappearing entirely could be dire.Digital authoritarianism has been on the rise for a decade, and surveillance technology has already given authoritarian governments powerful new strategies to crack down on opposition: let the protests happen, but then detect and quietly go after the participants after the fact. More generally, my basic fear is that the same kinds of managerial technologies that allow OpenAI to serve over a hundred million customers with 500 employees will also allow a 500-person political elite, or even a 5-person board, to maintain an iron fist over an entire country. With modern surveillance to collect information, and modern AI to interpret it, there may be no place to hide.It gets worse when we think about the consequences of AI in warfare. Quoting a semi-famous post on the philosophy of AI and crypto by 0xAlpha:When there is no need for political-ideological work and war mobilization, the supreme commander of war only needs to consider the situation itself as if it were a game of chess and completely ignore the thoughts and emotions of the pawns/knights/rooks on the chessboard. War becomes a purely technological game.Furthermore, political-ideological work and war mobilization require a justification for anyone to wage war. Don't underestimate the importance of such "justification". It has been a legitimacy constraint on the wars in human society for thousands of years. Anyone who wants to wage war has to have a reason, or at least a superficially justifiable excuse. You might argue that this constraint is so weak because, in many instances, this has been nothing more than an excuse. For example, some (if not all) of the Crusades were really to occupy land and rob wealth, but they had to be done in the name of God, even if the city being robbed was God's Constantinople. However, even a weak constraint is still a constraint! This little excuse requirement alone actually prevents the warmakers from being completely unscrupulous in achieving their goals. Even an evil like Hitler could not just launch a war right off the bat–he had to spend years first trying to convince the German nation to fight for the living space for the noble Aryan race.Today, the "human in the loop" serves as an important check on a dictator's power to start wars, or to oppress its citizens internally. Humans in the loop have prevented nuclear wars, allowed the opening of the Berlin wall, and saved lives during atrocities like the Holocaust. If armies are robots, this check disappears completely. A dictator could get drunk at 10 PM, get angry at people being mean to them on twitter at 11 PM, and a robotic invasion fleet could cross the border to rain hellfire on a neighboring nation's civilians and infrastructure before midnight.And unlike previous eras, where there is always some distant corner, where the sky is high and the emperor is far away, where opponents of a regime could regroup and hide and eventually find a way to make things better, with 21st century AI a totalitarian regime may well maintain enough surveillance and control over the world to remain "locked in" forever.d/acc: Defensive (or decentralization, or differential) accelerationOver the last few months, the "e/acc" ("effective accelerationist") movement has gained a lot of steam. Summarized by "Beff Jezos" here, e/acc is fundamentally about an appreciation of the truly massive benefits of technological progress, and a desire to accelerate this trend to bring those benefits sooner.I find myself sympathetic to the e/acc perspective in a lot of contexts. There's a lot of evidence that the FDA is far too conservative in its willingness to delay or block the approval of drugs, and bioethics in general far too often seems to operate by the principle that "20 people dead in a medical experiment gone wrong is a tragedy, but 200000 people dead from life-saving treatments being delayed is a statistic". The delays to approving covid tests and vaccines, and malaria vaccines, seem to further confirm this. However, it is possible to take this perspective too far.In addition to my AI-related concerns, I feel particularly ambivalent about the e/acc enthusiasm for military technology. In the current context in 2023, where this technology is being made by the United States and immediately applied to defend Ukraine, it is easy to see how it can be a force for good. Taking a broader view, however, enthusiasm about modern military technology as a force for good seems to require believing that the dominant technological power will reliably be one of the good guys in most conflicts, now and in the future: military technology is good because military technology is being built and controlled by America and America is good. Does being an e/acc require being an America maximalist, betting everything on both the government's present and future morals and the country's future success?On the other hand, I see the need for new approaches in thinking of how to reduce these risks. The OpenAI governance structure is a good example: it seems like a well-intentioned effort to balance the need to make a profit to satisfy investors who provide the initial capital with the desire to have a check-and-balance to push against moves that risk OpenAI blowing up the world. In practice, however, their recent attempt to fire Sam Altman makes the structure seem like an abject failure: it centralized power in an undemocratic and unaccountable board of five people, who made key decisions based on secret information and refused to give any details on their reasoning until employees threatened to quit en-masse. Somehow, the non-profit board played their hands so poorly that the company's employees created an impromptu de-facto union... to side with the billionaire CEO against them.Across the board, I see far too many plans to save the world that involve giving a small group of people extreme and opaque power and hoping that they use it wisely. And so I find myself drawn to a different philosophy, one that has detailed ideas for how to deal with risks, but which seeks to create and maintain a more democratic world and tries to avoid centralization as the go-to solution to our problems. This philosophy also goes quite a bit broader than AI, and I would argue that it applies well even in worlds where AI risk concerns turn out to be largely unfounded. I will refer to this philosophy by the name of d/acc. dacc3The "d" here can stand for many things; particularly, defense, decentralization, democracy and differential. First, think of it about defense, and then we can see how this ties into the other interpretations.Defense-favoring worlds help healthy and democratic governance thriveOne frame to think about the macro consequences of technology is to look at the balance of defense vs offense. Some technologies make it easier to attack others, in the broad sense of the term: do things that go against their interests, that they feel the need to react to. Others make it easier to defend, and even defend without reliance on large centralized actors.A defense-favoring world is a better world, for many reasons. First of course is the direct benefit of safety: fewer people die, less economic value gets destroyed, less time is wasted on conflict. What is less appreciated though is that a defense-favoring world makes it easier for healthier, more open and more freedom-respecting forms of governance to thrive.An obvious example of this is Switzerland. Switzerland is often considered to be the closest thing the real world has to a classical-liberal governance utopia. Huge amounts of power are devolved to provinces (called "cantons"), major decisions are decided by referendums, and many locals do not even know who the president is. How can a country like this survive extremely challenging political pressures? Part of the answer is excellent political strategy, but the other major part is very defense-favoring geography in the form of its mountainous terrain. The flag is a big plus. But so are the mountains. Anarchist societies in Zomia, famously profiled in James C Scott's new book "The Art of Not Being Governed", are another example: they too maintain their freedom and independence in large part thanks to mountainous terrain. Meanwhile, the Eurasian steppes are the exact opposite of a governance utopia. Sarah Paine's exposition of maritime versus continental powers makes similar points, though focusing on water as a defensive barrier rather than mountains. In fact, the combination of ease of voluntary trade and difficulty of involuntary invasion, common to both Switzerland and the island states, seems ideal for human flourishing.I discovered a related phenomenon when advising quadratic funding experiments within the Ethereum ecosystem: specifically the Gitcoin Grants funding rounds. In round 4, a mini-scandal arose when some of the highest-earning recipients were Twitter influencers, whose contributions are viewed by some as positive and others as negative. My own interpretation of this phenomenon was that there is an imbalance: quadratic funding allows you to signal that you think something is a public good, but it gives no way to signal that something is a public bad. In the extreme, a fully neutral quadratic funding system would fund both sides of a war. And so for round 5, I proposed that Gitcoin should include negative contributions: you pay $1 to reduce the amount of money that a given project receives (and implicitly redistribute it to all other projects). The result: lots of people hated it. One of the many internet memes that floated around after round 5. This seemed to me to be a microcosm of a bigger pattern: creating decentralized governance mechanisms to deal with negative externalities is socially a very hard problem. There is a reason why the go-to example of decentralized governance going wrong is mob justice. There is something about human psychology that makes responding to negatives much more tricky, and much more likely to go very wrong, than responding to positives. And this is a reason why even in otherwise highly democratic organizations, decisions of how to respond to negatives are often left to a centralized board.In many cases, this conundrum is one of the deep reasons why the concept of "freedom" is so valuable. If someone says something that offends you, or has a lifestyle that you consider disgusting, the pain and disgust that you feel is real, and you may even find it less bad to be physically punched than to be exposed to such things. But trying to agree on what kinds of offense and disgust are socially actionable can have far more costs and dangers than simply reminding ourselves that certain kinds of weirdos and jerks are the price we pay for living in a free society.At other times, however, the "grin and bear it" approach is unrealistic. And in such cases, another answer that is sometimes worth looking toward is defensive technology. The more that the internet is secure, the less we need to violate people's privacy and use shady international diplomatic tactics to go after each individual hacker. The more that we can build personalized tools for blocking people on Twitter, in-browser tools for detecting scams and collective tools for telling apart misinformation and truth, the less we have to fight over censorship. The faster we can make vaccines, the less we have to go after people for being superspreaders. Such solutions don't work in all domains - we certainly don't want a world where everyone has to wear literal body armor - but in domains where we can build technology to make the world more defense-favoring, there is enormous value in doing so.This core idea, that some technologies are defense-favoring and are worth promoting, while other technologies are offense-favoring and should be discouraged, has roots in effective altruist literature under a different name: differential technology development. There is a good exposition of this principle from University of Oxford researchers from 2022: Figure 1: Mechanisms by which differential technology development can reduce negative societal impacts. There are inevitably going to be imperfections in classifying technologies as offensive, defensive or neutral. Like with "freedom", where one can debate whether social-democratic government policies decrease freedom by levying heavy taxes and coercing employers or increase freedom by reducing average people's need to worry about many kinds of risks, with "defense" too there are some technologies that could fall on both sides of the spectrum. Nuclear weapons are offense-favoring, but nuclear power is human-flourishing-favoring and offense-defense-neutral. Different technologies may play different roles at different time horizons. But much like with "freedom" (or "equality", or "rule of law"), ambiguity at the edges is not so much an argument against the principle, as it is an opportunity to better understand its nuances.Now, let's see how to apply this principle to a more comprehensive worldview. We can think of defensive technology, like other technology, as being split into two spheres: the world of atoms and the world of bits. The world of atoms, in turn, can be split into micro (ie. biology, later nanotech) and macro (ie. what we conventionally think of "defense", but also resilient physical infrastructure). The world of bits I will split on a different axis: how hard is it to agree, in principle, who the attacker is?. Sometimes it's easy; I call this cyber defense. At other times it's harder; I call this info defense. Macro physical defenseThe most underrated defensive technology in the macro sphere is not even iron domes (including Ukraine's new system) and other anti-tech and anti-missile military hardware, but rather resilient physical infrastructure. The majority of deaths from a nuclear war are likely to come from supply chain disruptions, rather than the initial radiation and blast, and low-infrastructure internet solutions like Starlink have been crucial in maintaining Ukraine's connectivity for the last year and a half.Building tools to help people survive and even live comfortable lives independently or semi-independently of long international supply chains seems like a valuable defensive technology, and one with a low risk of turning out to be useful for offense.The quest to make humanity a multi-planetary civilization can also be viewed from a d/acc perspective: having at least a few of us live self-sufficiently on other planets can increase our resilience against something terrible happening on Earth. Even if the full vision proves unviable for the time being, the forms of self-sufficient living that will need to be developed to make such a project possible may well also be turned to help improve our civilizational resilience on Earth.Micro physical defense (aka bio)Especially due to its long-term health effects, Covid continues to be a concern. But Covid is far from the last pandemic that we will face; there are many aspects of the modern world that make it likely that more pandemics are soon to come:Higher population density makes it much easier for airborne viruses and other pathogens to spread. Epidemic diseases are relatively new in human history and most began with urbanization only a few thousand years ago. Ongoing rapid urbanization means that population densities will increase further over the next half century. Increased air travel means that airborne pathogens spread very quickly worldwide. People rapidly becoming wealthier means that air travel will likely increase much further over the next half century; complexity modeling suggests that even small increases may have drastic effects. Climate change may increase this risk even further. Animal domestication and factory farming are major risk factors. Measles probably evolved from a cow virus less than 3000 years ago. Today's factory farms are also farming new strains of influenza (as well as fueling antibiotic resistance, with consequences for human innate immunity). Modern bio-engineering makes it easier to create new and more virulent pathogens. Covid may or may not have leaked from a lab doing intentional "gain of function" research. Regardless, lab leaks happen all the time, and tools are rapidly improving to make it easier to intentionally create extremely deadly viruses, or even prions (zombie proteins). Artificial plagues are particularly concerning in part because unlike nukes, they are unattributable: you can release a virus without anyone being able to tell who created it. It is possible right now to design a genetic sequence and send it to a wet lab for synthesis, and have it shipped to you within five days. This is an area where CryptoRelief and Balvi, two orgs spun up and funded as a result of a large accidental windfall of Shiba Inu coins in 2021, have been very active. CryptoRelief initially focused on responding to the immediate crisis and more recently has been building up a long-term medical research ecosystem in India, while Balvi has been focusing on moonshot projects to improve our ability to detect, prevent and treat Covid and other airborne diseases. ++Balvi has insisted that projects it funds must be open source++. Taking inspiration from the 19th century water engineering movement that defeated cholera and other waterborne pathogens, it has funded projects across the whole spectrum of technologies that can make the world more hardened against airborne pathogens by default (see: update 1 and update 2), including:Far-UVC irradiation R&D Air filtering and quality monitoring in India, Sri Lanka, the United States and elsewhere, and air quality monitoring Equipment for cheap and effective decentralized air quality testing Research on Long Covid causes and potential treatment options (the primary cause may be straightforward but clarifying mechanisms and finding treatment is harder) Vaccines (eg. RaDVaC, PopVax) and vaccine injury research A set of entirely novel non-invasive medical tools Early detection of epidemics using analysis of open-source data (eg. EPIWATCH) Testing, including very cheap molecular rapid tests Biosafety-appropriate masks for when other approaches fail Other promising areas of interest include wastewater surveillance of pathogens, improving filtering and ventilation in buildings, and better understanding and mitigating risks from poor air quality.There is an opportunity to build a world that is much more hardened against airborne pandemics, both natural and artificial, by default. This world would feature a highly optimized pipeline where we can go from a pandemic starting, to being automatically detected, to people around the world having access to targeted, locally-manufacturable and verifiable open source vaccines or other prophylactics, administered via nebulization or nose spray (meaning: self-administerable if needed, and no needles required), all within a month. In the meantime, much better air quality would drastically reduce the rate of spread, and prevent many pandemics from getting off the ground at all.Imagine a future that doesn't have to resort to the sledgehammer of social compulsion - no mandates and worse, and no risk of poorly designed and implemented mandates that arguably make things worse - because the infrastructure of public health is woven into the fabric of civilization. These worlds are possible, and a medium amount of funding into bio-defense could make it happen. The work would happen even more smoothly if developments are open source, free to users and protected as public goods.Cyber defense, blockchains and cryptographyIt is generally understood among security professionals that the current state of computer security is pretty terrible. That said, it's easy to understate the amount of progress that has been made. Hundreds of billions of dollars of cryptocurrency are available to anonymously steal by anyone who can hack into users' wallets, and while far more gets lost or stolen than I would like, it's also a fact that most of it has remained un-stolen for over a decade. Recently, there have been improvements:Trusted hardware chips inside of users' phones, effectively creating a much smaller high-security operating system inside the phone that can remain protected even if the rest of the phone gets hacked. Among many other use cases, these chips are increasingly being explored as a way to make more secure crypto wallets. Browsers as the de-facto operating system. Over the last ten years, there has been a quiet shift from downloadable applications to in-browser applications. This has been largely enabled by WebAssembly (WASM). Even Adobe Photoshop, long cited as a major reason why many people cannot practically use Linux because of its necessity and Linux-incompatibility, is now Linux-friendly thanks to being inside the browser. This is also a large security boon: while browsers do have flaws, in general they come with much more sandboxing than installed applications: apps cannot access arbitrary files on your computer. Hardened operating systems. GrapheneOS for mobile exists, and is very usable. QubesOS for desktop exists; it is currently somewhat less usable than Graphene, at least in my experience, but it is improving. Attempts at moving beyond passwords. Passwords are, unfortunately, difficult to secure both because they are hard to remember, and because they are easy to eavesdrop on. Recently, there has been a growing movement toward reducing emphasis on passwords, and making multi-factor hardware-based authentication actually work. However, the lack of cyber defense in other spheres has also led to major setbacks. The need to protect against spam has led to email becoming very oligopolistic in practice, making it very hard to self-host or create a new email provider. Many online apps, including Twitter, are requiring users to be logged in to access content, and blocking IPs from VPNs, making it harder to access the internet in a way that protects privacy. Software centralization is also risky because of "weaponized interdependence": the tendency of modern technology to route through centralized choke points, and for the operators of those choke points to use that power to gather information, manipulate outcomes or exclude specific actors - a strategy that seems to even be currently employed against the blockchain industry itself.These are concerning trends, because it threatens what has historically been one of my big hopes for why the future of freedom and privacy, despite deep tradeoffs, might still turn out to be bright. In his book "Future Imperfect", David Friedman predicts that we might get a compromise future: the in-person world would be more and more surveilled, but through cryptography, the online world would retain, and even improve, its privacy. Unfortunately, as we have seen, such a counter-trend is far from guaranteed.This is where my own emphasis on cryptographic technologies such as blockchains and zero-knowledge proofs comes in. Blockchains let us create economic and social structures with a "shared hard drive" without having to depend on centralized actors. Cryptocurrency allows individuals to save money and make financial transactions, as they could before the internet with cash, without dependence on trusted third parties that could change their rules on a whim. They can also serve as a fallback anti-sybil mechanism, making attacks and spam expensive even for users who do not have or do not want to reveal their meat-space identity. Account abstraction, and notably social recovery wallets, can protect our crypto-assets, and potentially other assets in the future, without over-relying on centralized intermediaries.Zero knowledge proofs can be used for privacy, allowing users to prove things about themselves without revealing private information. For example, wrap a digital passport signature in a ZK-SNARK to prove that you are a unique citizen of a given country, without revealing which citizen you are. Technologies like this can let us maintain the benefits of privacy and anonymity - properties that are widely agreed as being necessary for applications like voting - while still getting security guarantees and fighting spam and bad actors. A proposed design for a ZK social media system, where moderation actions can happen and users can be penalized, all without needing to know anyone's identity. Zupass, incubated at Zuzalu earlier this year, is an excellent example of this in practice. This is an application, which has already been used by hundreds of people at Zuzalu and more recently by thousands of people for ticketing at Devconnect, that allows you to hold tickets, memberships, (non-transferable) digital collectibles, and other attestations, and prove things about them all without compromising your privacy. For example, you can prove that you are a unique registered resident of Zuzalu, or a Devconnect ticket holder, without revealing anything else about who you are. These proofs can be shown in-person, via a QR code, or digitally, to log in to applications like Zupoll, an anonymized voting system available only to Zuzalu residents.These technologies are an excellent example of d/acc principles: they allow users and communities to verify trustworthiness without compromising privacy, and protect their security without relying on centralized choke points that impose their own definitions of who is good and bad. They improve global accessibility by creating better and fairer ways to protect a user or service's security than common techniques used today, such as discriminating against entire countries that are deemed untrustworthy. These are very powerful primitives that could be necessary if we want to preserve a decentralized vision of information security going into the 21st century. Working on defensive technologies for cyberspace more broadly can make the internet more open, safe and free in very important ways going forward.Info-defenseCyber-defense, as I have described it, is about situations where it's easy for reasonable human beings to all come to consensus on who the attacker is. If someone tries to hack into your wallet, it's easy to agree that the hacker is the bad guy. If someone tries to DoS attack a website, it's easy to agree that they're being malicious, and are not morally the same as a regular user trying to read what's on the site. There are other situations where the lines are more blurry. It is the tools for improving our defense in these situations that I call "info-defense".Take, for example, fact checking (aka, preventing "misinformation"). I am a huge fan of Community Notes, which has done a lot to help users identify truths and falsehoods in what other users are tweeting. Community Notes uses a new algorithm which surfaces not the notes that are the most popular, but rather the notes that are most approved by users across the political spectrum. Community Notes in action. I am also a fan of prediction markets, which can help identify the significance of events in real time, before the dust settles and there is consensus on which direction is which. The Polymarket on Sam Altman is very helpful in giving a useful summary of the ultimate consequences of hour-by-hour revelations and negotiations, giving much-needed context to people who only see the individual news items and don't understand the significance of each one. Prediction markets are often flawed. But Twitter influencers who are willing to confidently express what they think "will" happen over the next year are often even more flawed. There is still room to improve prediction markets much further. For example, a major practical flaw of prediction markets is their low volume on all but the most high-profile events; a natural direction to try to solve this would be to have prediction markets that are played by AIs.Within the blockchain space, there is a particular type of info defense that I think we need much more of. Namely, wallets should be much more opinionated and active in helping users determine the meaning of things that they are signing, and protecting them from fraud and scams. This is an intermediate case: what is and is not a scam is less subjective than perspectives on controversial social events, but it's more subjective than telling apart legitimate users from DoS attackers or hackers. Metamask has an scam database already, and automatically blocks users from visiting scam sites: Applications like Fire are an example of one way to go much further. However, security software like this should not be something that requires explicit installs; it should be part of crypto wallets, or even browsers, by default.Because of its more subjective nature, info-defense is inherently more collective than cyber-defense: you need to somehow plug into a large and sophisticated group of people to identify what might be true or false, and what kind of application is a deceptive ponzi. There is an opportunity for developers to go much further in developing effective info-defense, and in hardening existing forms of info-defense. Something like Community Notes could be included in browsers, and cover not just social media platforms but also the whole internet.Social technology beyond the "defense" framingTo some degree, I can be justifiably accused of shoehorning by describing some of these info technologies as being about "defense". After all, defense is about helping well-meaning actors be protected from badly-intentioned actors (or, in some cases, from nature). Some of these social technologies, however, are about helping well-intentioned actors form consensus.A good example of this is pol.is, which uses an algorithm similar to Community Notes (and which predates Community Notes) to help communities identify points of agreement between sub-tribes who otherwise disagree on a lot. Viewpoints.xyz was inspired by pol.is, and has a similar spirit: Technologies like this could be used to enable more decentralized governance over contentious decisions. Again, blockchain communities are a good testing ground for this, and one where such algorithms have already shown valuable. Generally, decisions over which improvements ("EIPs") to make to the Ethereum protocol are made by a fairly small group in meetings called "All Core Devs calls". For highly technical decisions, where most community members have no strong feelings, this works reasonably well. For more consequential decisions, which affect protocol economics, or more fundamental values like immutability and censorship resistance, this is often not enough. Back in 2016-17, when a series of contentious decisions around implementing the DAO fork, reducing issuance and (not) unfreezing the Parity wallet, tools like Carbonvote, as well as social media voting, helped the community and the developers to see which way the bulk of the community opinion was facing. Carbonvote on the DAO fork. Carbonvote had its flaws: it relied on ETH holdings to determine who was a member of the Ethereum community, making the outcome dominated by a few wealthy ETH holders ("whales"). With modern tools, however, we could make a much better Carbonvote, leveraging multiple signals such as POAPs, Zupass stamps, Gitcoin passports, Protocol Guild memberships, as well as ETH (or even solo-staked-ETH) holdings to gauge community membership.Tools like this could be used by any community to make higher-quality decisions, find points of commonality, coordinate (physical or digital) migrations or do a number of other things without relying on opaque centralized leadership. This is not defense acceleration per se, but it can certainly be called democracy acceleration. Such tools could even be used to improve and democratize the governance of key actors and institutions working in AI.So what are the paths forward for superintelligence?The above is all well and good, and could make the world a much more harmonious, safer and freer place for the next century. However, it does not yet address the big elephant in the room: superintelligent AI.The default path forward suggested by many of those who worry about AI essentially leads to a minimal AI world government. Near-term versions of this include a proposal for a "multinational AGI consortium" ("MAGIC"). Such a consortium, if it gets established and succeeds at its goals of creating superintelligent AI, would have a natural path to becoming a de-facto minimal world government. Longer-term, there are ideas like the "pivotal act" theory: we create an AI that performs a single one-time act which rearranges the world into a game where from that point forward humans are still in charge, but where the game board is somehow more defense-favoring and more fit for human flourishing.The main practical issue that I see with this so far is that people don't seem to actually trust any specific governance mechanism with the power to build such a thing. This fact becomes stark when you look at the results to my recent Twitter polls, asking if people would prefer to see AI monopolized by a single entity with a decade head-start, or AI delayed by a decade for everyone: The size of each poll is small, but the polls make up for it in the uniformity of their result across a wide diversity of sources and options. In nine out of nine cases, the majority of people would rather see highly advanced AI delayed by a decade outright than be monopolized by a single group, whether it's a corporation, government or multinational body. In seven out of nine cases, delay won by at least two to one. This seems like an important fact to understand for anyone pursuing AI regulation. Current approaches have been focusing on creating licensing schemes and regulatory requirements, trying to restrict AI development to a smaller number of people, but these have seen popular pushback precisely because people don't want to see anyone monopolize something so powerful. Even if such top-down regulatory proposals reduce risks of extinction, they risk increasing the chance of some kind of permanent lock-in to centralized totalitarianism. Paradoxically, could agreements banning extremely advanced AI research outright (perhaps with exceptions for biomedical AI), combined with measures like mandating open source for those models that are not banned as a way of reducing profit motives while further improving equality of access, be more popular?The main approach preferred by opponents of the "let's get one global org to do AI and make its governance really really good" route is polytheistic AI: intentionally try to make sure there's lots of people and companies developing lots of AIs, so that none of them grows far more powerful than the other. This way, the theory goes, even as AIs become superintelligent, we can retain a balance of power.This philosophy is interesting, but my experience trying to ensure "polytheism" within the Ethereum ecosystem does make me worry that this is an inherently unstable equilibrium. In Ethereum, we have intentionally tried to ensure decentralization of many parts of the stack: ensuring that there's no single codebase that controls more than half of the proof of stake network, trying to counteract the dominance of large staking pools, improving geographic decentralization, and so on. Essentially, Ethereum is actually attempting to execute on the old libertarian dream of a market-based society that uses social pressure, rather than government, as the antitrust regulator. To some extent, this has worked: the Prysm client's dominance has dropped from above 70% to under 45%. But this is not some automatic market process: it's the result of human intention and coordinated action.My experience within Ethereum is mirrored by learnings from the broader world as a whole, where many markets have proven to be natural monopolies. With superintelligent AIs acting independently of humans, the situation is even more unstable. Thanks to recursive self-improvement, the strongest AI may pull ahead very quickly, and once AIs are more powerful than humans, there is no force that can push things back into balance.Additionally, even if we do get a polytheistic world of superintelligent AIs that ends up stable, we still have the other problem: that we get a universe where humans are pets.A happy path: merge with the AIs?A different option that I have heard about more recently is to focus less on AI as something separate from humans, and more on tools that enhance human cognition rather than replacing it.One near-term example of something that goes in this direction is AI drawing tools. Today, the most prominent tools for making AI-generated images only have one step at which the human gives their input, and AI fully takes over from there. An alternative would be to focus more on AI versions of Photoshop: tools where the artist or the AI might make an early draft of a picture, and then the two collaborate on improving it with a process of real-time feedback. Photoshop generative AI fill, 2023. Source. I tried, it and it takes time to get used to but it actually works quite well! Another direction in a similar spirit is the Open Agency Architecture, which proposes splitting the different parts of an AI "mind" (eg. making plans, executing on plans, interpreting information from the outside world) into separate components, and introducing diverse human feedback in between these parts.So far, this sounds mundane, and something that almost everyone can agree that it would be good to have. The economist Daron Acemoglu's work is far from this kind of AI futurism, but his new book Power and Progress hints at wanting to see more of exactly these types of AI.But if we want to extrapolate this idea of human-AI cooperation further, we get to more radical conclusions. Unless we create a world government powerful enough to detect and stop every small group of people hacking on individual GPUs with laptops, someone is going to create a superintelligent AI eventually - one that can think a thousand times faster than we can - and no combination of humans using tools with their hands is going to be able to hold its own against that. And so we need to take this idea of human-computer cooperation much deeper and further.A first natural step is brain-computer interfaces. Brain-computer interfaces can give humans much more direct access to more-and-more powerful forms of computation and cognition, reducing the two-way communication loop between man and machine from seconds to milliseconds. This would also greatly reduce the "mental effort" cost to getting a computer to help you gather facts, give suggestions or execute on a plan.Later stages of such a roadmap admittedly get weird. In addition to brain-computer interfaces, there are various paths to improving our brains directly through innovations in biology. An eventual further step, which merges both paths, may involve uploading our minds to run on computers directly. This would also be the ultimate d/acc for physical security: protecting ourselves from harm would no longer be a challenging problem of protecting inevitably-squishy human bodies, but rather a much simpler problem of making data backups. Directions like this are sometimes met with worry, in part because they are irreversible, and in part because they may give powerful people more advantages over the rest of us. Brain-computer interfaces in particular have dangers - after all, we are talking about literally reading and writing to people's minds. These concerns are exactly why I think it would be ideal for a leading role in this path to be held by a security-focused open-source movement, rather than closed and proprietary corporations and venture capital funds. Additionally, all of these issues are worse with superintelligent AIs that operate independently from humans, than they are with augmentations that are closely tied to humans. The divide between "enhanced" and "unenhanced" already exists today due to limitations in who can and can't use ChatGPT.If we want a future that is both superintelligent and "human", one where human beings are not just pets, but actually retain meaningful agency over the world, then it feels like something like this is the most natural option. There are also good arguments why this could be a safer AI alignment path: by involving human feedback at each step of decision-making, we reduce the incentive to offload high-level planning responsibility to the AI itself, and thereby reduce the chance that the AI does something totally unaligned with humanity's values on its own.One other argument in favor of this direction is that it may be more socially palatable than simply shouting "pause AI" without a complementary message providing an alternative path forward. It will require a philosophical shift from the current mentality that tech advancements that touch humans are dangerous but advancements that are separate from humans are by-default safe. But it has a huge countervailing benefit: it gives developers something to do. Today, the AI safety movement's primary message to AI developers seems to be "you should just stop". One can work on alignment research, but today this lacks economic incentives. Compared to this, the common e/acc message of "you're already a hero just the way you are" is understandably extremely appealing. A d/acc message, one that says "you should build, and build profitable things, but be much more selective and intentional in making sure you are building things that help you and humanity thrive", may be a winner.Is d/acc compatible with your existing philosophy?If you are an e/acc, then d/acc is a subspecies of e/acc - just one that is much more selective and intentional. If you are an effective altruist, then d/acc is a re-branding of the effective-altruist idea of differential technology development, though with a greater emphasis on liberal and democratic values. If you are a libertarian, then d/acc is a sub-species of techno-libertarianism, though a more pragmatic one that is more critical of "the techno-capital machine", and willing to accept government interventions today (at least, if cultural interventions don't work) to prevent much worse un-freedom tomorrow. If you are a Pluralist, in the Glen Weyl sense of the term, then d/acc is a frame that can easily include the emphasis on better democratic coordination technology that Plurality values. If you are a public health advocate, then d/acc ideas can be a source of a broader long-term vision, and opportunity to find common ground with "tech people" that you might otherwise feel at odds with. If you are a blockchain advocate, then d/acc is a more modern and broader narrative to embrace than the fifteen-year-old emphasis on hyperinflation and banks, which puts blockchains into context as one of many tools in a concrete strategy to build toward a brighter future. If you are a solarpunk, then d/acc is a subspecies of solarpunk, and incorporates a similar emphasis on intentionality and collective action. If you are a lunarpunk, then you will appreciate the d/acc emphasis on informational defense, through maintaining privacy and freedom. We are the brightest starI love technology because technology expands human potential. Ten thousand years ago, we could build some hand tools, change which plants grow on a small patch of land, and build basic houses. Today, we can build 800-meter-tall towers, store the entirety of recorded human knowledge in a device we can hold in our hands, communicate instantly across the globe, double our lifespan, and live happy and fulfilling lives without fear of our best friends regularly dropping dead of disease. We started from the bottom, now we're here. I believe that these things are deeply good, and that expanding humanity's reach even further to the planets and stars is deeply good, because I believe humanity is deeply good. It is fashionable in some circles to be skeptical of this: the voluntary human extinction movement argues that the Earth would be better off without humans existing at all, and many more want to see much smaller number of human beings see the light of this world in the centuries to come. It is common to argue that humans are bad because we cheat and steal, engage in colonialism and war, and mistreat and annihilate other species. My reply to this style of thinking is one simple question: compared to what?Yes, human beings are often mean, but we much more often show kindness and mercy, and work together for our common benefit. Even during wars we often take care to protect civilians - certainly not nearly enough, but also far more than we did 2000 years ago. The next century may well bring widely available non-animal-based meat, eliminating the largest moral catastrophe that human beings can justly be blamed for today. Non-human animals are not like this. There is no situation where a cat will adopt an entire lifestyle of refusing to eat mice as a matter of ethical principle. The Sun is growing brighter every year, and in about one billion years, it is expected that this will make the Earth too hot to sustain life. Does the Sun even think about the genocide that it is going to cause?And so it is my firm belief that, out of all the things that we have known and seen in our universe, we, humans, are the brightest star. We are the one thing that we know about that, even if imperfectly, sometimes make an earnest effort to care about "the good", and adjust our behavior to better serve it. Two billion years from now, if the Earth or any part of the universe still bears the beauty of Earthly life, it will be human artifices like space travel and geoengineering that will have made it happen. We need to build, and accelerate. But there is a very real question that needs to be asked: what is the thing that we are accelerating towards? The 21st century may well be the pivotal century for humanity, the century in which our fate for millennia to come gets decided. Do we fall into one of a number of traps from which we cannot escape, or do we find a way toward a future where we retain our freedom and agency? These are challenging problems. But I look forward to watching and participating in our species' grand collective effort to find the answers.
-
Exit games for EVM validiums: the return of Plasma Exit games for EVM validiums: the return of Plasma2023 Nov 14 See all posts Exit games for EVM validiums: the return of Plasma Special thanks to Karl Floersch, Georgios Konstantopoulos and Martin Koppelmann for feedback, review and discussion.Plasma is a class of blockchain scaling solutions that allow all data and computation, except for deposits, withdrawals and Merkle roots, to be kept off-chain. This opens the door to very large scalability gains that are not bottlenecked by on-chain data availability. Plasma was first invented in 2017, and saw many iterations in 2018, most notably Minimal Viable Plasma, Plasma Cash, Plasma Cashflow and Plasma Prime. Unfortunately, Plasma has since largely been superseded by rollups, for reasons primarily having to do with (i) large client-side data storage costs, and (ii) fundamental limitations of Plasma that make it hard to generalize beyond payments.The advent of validity proofs (aka ZK-SNARKs) gives us a reason to rethink this decision. The largest challenge of making Plasma work for payments, client-side data storage, can be efficiently addressed with validity proofs. Additionally, validity proofs provide a wide array of tools that allow us to make a Plasma-like chain that runs an EVM. The Plasma security guarantees would not cover all users, as the fundamental reasons behind the impossibility of extending Plasma-style exit games to many kinds of complex applications still remain. However, a very large percentage of assets could nevertheless be kept secure in practice.This post describes how Plasma ideas can be extended to do such a thing.Overview: how Plasma worksThe simplest version of Plasma to understand is Plasma Cash. Plasma Cash works by treating each individual coin as a separate NFT, and tracking a separate history for each coin. A Plasma chain has an operator, who is responsible for making and regularly publishing blocks. The transactions in each block are stored as a sparse Merkle tree: if a transaction transfers ownership of coin k, it appears in position k of the tree. When the Plasma chain operator creates a new block, they publish the root of the Merkle tree to chain, and they directly send to each user the Merkle branches corresponding to the coins that that user owns. Suppose that these are the last three transaction trees in a Plasma Cash chain. Then, assuming all previous trees are valid, we know that Eve currently owns coin 1, David owns coin 4 and George owns coin 6. The main risk in any Plasma system is the operator misbehaving. This can happen in two ways:Publishing an invalid block (eg. the operator includes a transaction sending coin 1 from Fred to Hermione even if Fred doesn't own the coin at that time) Publishing an unavailable block (eg. the operator does not send Bob his Merkle branch for one of the blocks, preventing him from ever proving to someone else that his coin is still valid and unspent) If the operator misbehaves in a way that is relevant to a user's assets, the user has the responsibility to exit immediately (specifically, within 7 days). When a user ("the exiter") exits, they provide a Merkle branch proving the inclusion of the transaction that transferred that coin from the previous owner to them. This starts a 7-day challenge period, during which others can challenge that exit by providing a Merkle proof of one of three things:Not latest owner: a later transaction signed by the exiter transferring the exiter's coin to someone else Double spend: a transaction that transferred the coin from the previous owner to someone else, that was included before the transaction transferring the coin to the exiter Invalid history: a transaction that transferred the coins before (within the past 7 days) that does not have a corresponding spend. The exiter can respond by providing the corresponding spend; if they do not, the exit fails. With these rules, anyone who owns coin k needs to see all of the Merkle branches of position k in all historical trees for the past week to be sure that they actually own coin k and can exit it. They need to store all the branches containing transfers of the asset, so that they can respond to challenges and safely exit with their coin.Generalizing to fungible tokensThe above design works for NFTs. However, much more common than NFTs are fungible tokens, like ETH and USDC. One way to apply Plasma Cash to fungible tokens is to simply make each small denomination of a coin (eg. 0.01 ETH) a separate NFT. Unfortunately, the gas costs of exiting would be too high if we do this.One solution is to optimize by treating many adjacent coins as a single unit, which can be transferred or exited all at once. There are two ways to do this:Use Plasma Cash almost as-is, but use fancy algorithms to compute the Merkle tree of a really large number of objects very quickly if many adjacent objects are the same. This is surprisingly not that hard to do; you can see a python implementation here. Use Plasma Cashflow, which simply represents many adjacent coins as a single object. However, both of these approaches run into the problem of fragmentation: if you receive 0.001 ETH each from hundreds of people who are buying coffees from you, you are going to have 0.001 ETH in many places in the tree, and so actually exiting that ETH would still require submitting many separate exits, making the gas fees prohibitive. Defragmentation protocols have been developed, but are tricky to implement.Alternatively, we can redesign the system to take into account a more traditional "unspent transaction output" (UTXO) model. When you exit a coin, you would need to provide the last week of history of those coins, and anyone could challenge your exit by proving that those historical coins were already exited. A withdrawal of the 0.2 ETH UTXO at the bottom right could be cancelled by showing a withdrawal of any of the UTXOs in its history, shown in green. Particularly note that the middle-left and bottom-left UTXOs are ancestors, but the top-left UTXO is not. This approach is similar to order-based coloring ideas from colored coins protocols circa 2013. There is a wide variety of techniques for doing this. In all cases, the goal is to track some conception of what is "the same coin" at different points in history, in order to prevent "the same coin" from being withdrawn twice.Challenges with generalizing to EVMUnfortunately, generalizing beyond payments to the EVM is much harder. One key challenge is that many state objects in the EVM do not have a clear "owner". Plasma's security depends on each object having an owner, who has the responsibility to watch and make sure the chain's data is available, and exit that object if anything goes wrong. Many Ethereum applications, however, do not work this way. Uniswap liquidity pools, for example, do not have a single owner.Another challenge is that the EVM does not attempt to limit dependencies. ETH held in account A at block N could have come from anywhere in block N-1. In order to exit a consistent state, an EVM Plasma chain would need to have an exit game where, in the extreme case, someone wishing to exit using information from block N might need to pay the fees to publish the entire block N state on chain: a gas cost in the many millions of dollars. UTXO-based Plasma schemes do not have this problem: each user can exit their assets from whichever block is the most recent block that they have the data for.A third challenge is that the unbounded dependencies in the EVM make it much harder to have aligned incentives to prove validity. The validity of any state depends on everything else, and so proving any one thing requires proving everything. Sorting out failures in such a situation generally cannot be made incentive-compatible due to the data availability problem. A particularly annoying problem is that we lose the guarantee, present in UTXO-based systems, that an object's state cannot change without its owner's consent. This guarantee is incredibly useful, as it means that the owner is always aware of the latest provable state of their assets, and simplifies exit games. Without it, creating exit games becomes much harder.How validity proofs can alleviate many of these problemsThe most basic thing that validity proofs can do to improve Plasma chain designs is to prove the validity of each Plasma block on chain. This greatly simplifies the design space: it means that the only attack from the operator that we have to worry about is unavailable blocks, and not invalid blocks. In Plasma Cash, for example, it removes the need to worry about history challenges. This reduces the state that a user needs to download, from one branch per block in the last week, to one branch per asset.Additionally, withdrawals from the most recent state (in the common case where the operator is honest, all withdrawals would be from the most recent state) are not subject to not-latest-owner challenges, and so in a validity-proven Plasma chain such withdrawals would not be subject to any challenges at all. This means that, in the normal case, withdrawals can be instant!Extending to the EVM: parallel UTXO graphsIn the EVM case, validity proofs also let us do something clever: they can be used to implement a parallel UTXO graph for ETH and ERC20 tokens, and SNARK-prove equivalence between the UTXO graph and the EVM state. Once you have that, you could implement a "regular" Plasma system over the UTXO graph. This lets us sidestep many of the complexities of the EVM. For example, the fact that in an account-based system someone can edit your account without your consent (by sending it coins and thereby increasing its balance) does not matter, because the Plasma construction is not over the EVM state itself, but rather over a UTXO state that lives in parallel to the EVM, where any coins that you receive would be separate objects.Extending to the EVM: total state exitingThere have been simpler schemes proposed to make a "plasma EVM", eg. Plasma Free and before that this post from 2019. In these schemes, anyone can send a message on the L1 to force the operator to either include a transaction or make a particular branch of the state available. If the operator fails to do this, the chain starts reverting blocks. The chain stops reverting once someone posts a full copy of either the whole state, or at least all of the data that users have flagged as being potentially missing. Making a withdrawal can require posting a bounty, which would pay for that user's share of the gas costs of someone posting such a large amount of data.Schemes like this have the weakness that they do not allow instant withdrawals in the normal case, because there is always the possibility that the chain will need to revert the latest state.Limits of EVM plasma schemesSchemes like this are powerful, but are NOT able to provide full security guarantees to all users. The case where they break down most clearly is situations where a particular state object does not have a clear economic "owner".Let us consider the case of a CDP (collateralized debt position), a smart contract where a user has coins that are locked up and can only be released once the user pays their debt. Suppose that user has 1 ETH (~$2000 as of the time of this writing) locked up in a CDP with 1000 DAI of debt. Now, the Plasma chain stops publishing blocks, and the user refuses to exit. The user could simply never exit. Now, the user has a free option: if the price of ETH drops below $1000, they walk away and forget about the CDP, and if the price of ETH stays above, eventually they claim it. On average, such a malicious user earns money from doing this.Another example is a privacy system, eg. Tornado Cash or Privacy Pools. Consider a privacy system with five depositors: The ZK-SNARKs in the privacy system keep the link between the owner of a coin coming into the system and the owner of the coin coming out hidden. Suppose that only orange has withdrawn, and at that point the Plasma chain operator stops publishing data. Suppose also that we use the UTXO graph approach with a first-in-first-out rule, so each coin gets matched to the coin right below it. Then, orange could withdraw their pre-mixed and post-mixed coin, and the system would perceive it as two separate coins. If blue tries to withdraw their pre-mixed coin, orange's more recent state would supersede it; meanwhile, blue would not have the information to withdraw their post-mixed coin.This can be fixed if you allow the other four depositors to withdraw the privacy contract itself (which would supersede the deposits), and then take the coins out on L1. However, actually implementing such a mechanism requires additional effort on the part of people developing the privacy system.There are also other ways to solve privacy, eg. the Intmax approach, which involves putting a few bytes on chain rollup-style together with a Plasma-like operator that passes around information between individual users.Uniswap LP positions have a similar problem: if you traded USDC for ETH in a Uniswap position, you could try to withdraw your pre-trade USDC and your post-trade ETH. If you collude with the Plasma chain operator, the liquidity providers and other users would not have access to the post-trade state, so they would not be able to withdraw their post-trade USDC. Special logic would be required to prevent situations like this.ConclusionsIn 2023, Plasma is an underrated design space. Rollups remain the gold standard, and have security properties that cannot be matched. This is particularly true from the developer experience perspective: nothing can match the simplicity of an application developer not even having to think about ownership graphs and incentive flows within their application.However, Plasma lets us completely sidestep the data availability question, greatly reducing transaction fees. Plasma can be a significant security upgrade for chains that would otherwise be validiums. The fact that ZK-EVMs are finally coming to fruition this year makes it an excellent opportunity to re-explore this design space, and come up with even more effective constructions to simplify the developer experience and protect users' funds.
-
Different types of layer 2s Different types of layer 2s2023 Oct 31 See all posts Different types of layer 2s Special thanks to Karl Floersch for feedback and reviewThe Ethereum layer 2 ecosystem has been expanding rapidly over the last year. The EVM rollup ecosystem, traditionally featuring Arbitrum, Optimism and Scroll, and more recently Kakarot and Taiko, has been progressing quickly, making great strides on improving their security; the L2beat page does a good job of summarizing the state of each project. Additionally, we have seen teams building sidechains also starting to build rollups (Polygon), layer 1 projects seeking to move toward being validiums (Celo), and totally new efforts (Linea, Zeth...). Finally, there is the not-just-EVM ecosystem: "almost-EVMs" like Zksync, extensions like Arbitrum Stylus, and broader efforts like the Starknet ecosystem, Fuel and others.One of the inevitable consequences of this is that we are seeing a trend of layer 2 projects becoming more heterogeneous. I expect this trend to continue, for a few key reasons:Some projects that are currently independent layer 1s are seeking to come closer to the Ethereum ecosystem, and possibly become layer 2s. These projects will likely want a step-by-step transition. Transitioning all at once now would cause a decrease in usability, as the technology is not yet ready to put everything on a rollup. Transitioning all at once later risks sacrificing momentum and being too late to be meaningful. Some centralized projects want to give their users more security assurances, and are exploring blockchain-based routes for doing so. In many cases, these are the projects that would have explored "permissioned consortium chains" in a previous era. Realistically, they probably only need a "halfway-house" level of decentralization. Additionally, their often very high level of throughput makes them unsuitable even for rollups, at least in the short term. Non-financial applications, like games or social media, want to be decentralized but need only a halfway-house level of security. In the social media case, this realistically involves treating different parts of the app differently: rare and high-value activity like username registration and account recovery should be done on a rollup, but frequent and low-value activity like posts and votes need less security. If a chain failure causes your post to disappear, that's an acceptable cost. If a chain failure causes you to lose your account, that is a much bigger problem. A big theme is that while applications and users that are on the Ethereum layer 1 today will be fine paying smaller but still visible rollup fees in the short term, users from the non-blockchain world will not: it's easier to justify paying $0.10 if you were paying $1 before than if you were paying $0 before. This applies both to applications that are centralized today, and to smaller layer 1s, which do typically have very low fees while their userbase remains small.A natural question that emerges is: which of these complicated tradeoffs between rollups, validiums and other systems makes sense for a given application?Rollups vs validiums vs disconnected systemsThe first dimension of security vs scale that we will explore can be described as follows: if you have an asset that is issued on L1, then deposited into the L2, then transferred to you, what level of guarantee do you have that you will be able to take the asset back to the L1?There is also a parallel question: what is the technology choice that is resulting in that level of guarantee, and what are the tradeoffs of that technology choice?We can describe this simply using a chart:System type Technology properties Security guarantees Costs Rollup Computation proven via fraud proofs or ZK-SNARKs, data stored on L1 You can always bring the asset back to L1 L1 data availability + SNARK-proving or redundant execution to catch errors Validium Computation proven via ZK-SNARKs (can't use fraud proofs), data stored on a server or other separate system Data availability failure can cause assets to be lost, but not stolen SNARK-proving Disconnected A separate chain (or server) Trust one or a small group of people not to steal your funds or lose the keys Very cheap It's worth mentioning that this is a simplified schema, and there are lots of intermediate options. For example:Between rollup and validium: a validium where anyone could make an on-chain payment to cover the cost of transaction fees, at which point the operator would be forced to provide some data onto the chain or else lose a deposit. Between plasma and validium: a Plasma system offers rollup-like security guarantees with off-chain data availability, but it supports only a limited number of applications. A system could offer a full EVM, and offer Plasma-level guarantees to users that do not use those more complicated applications, and validium-level guarantees to users that do. These intermediate options can be viewed as being on a spectrum between a rollup and a validium. But what motivates applications to choose a particular point on that spectrum, and not some point further left or further right? Here, there are two major factors:The cost of Ethereum's native data availability, which will decrease over time as technology improves. Ethereum's next hard fork, Dencun, introduces EIP-4844 (aka "proto-danksharding"), which provides ~32 kB/sec of onchain data availability. Over the next few years, this is expected to increase in stages as full danksharding is rolled out, eventually targeting around ~1.3 MB/sec of data availability. At the same time, improvements in data compression will let us do more with the same amount of data. The application's own needs: how much would users suffer from high fees, versus from something in the application going wrong? Financial applications would lose more from application failures; games and social media involve lots of activity per user, and relatively low-value activity, so a different security tradeoff makes sense for them. Approximately, this tradeoff looks something like this: Another type of partial guarantee worth mentioning is pre-confirmations. Pre-confirmations are messages signed by some set of participants in a rollup or validium that say "we attest that these transactions are included in this order, and the post-state root is this". These participants may well sign a pre-confirmation that does not match some later reality, but if they do, a deposit gets burned. This is useful for low-value applications like consumer payments, while higher-value applications like multimillion-dollar financial transfers will likely wait for a "regular" confirmation backed by the system's full security.Pre-confirmations can be viewed as another example of a hybrid system, similar to the "plasma / validium hybrid" mentioned above, but this time hybridizing between a rollup (or validium) that has full security but high latency, and a system with a much lower security level that has low latency. Applications that need lower latency get lower security, but can live in the same ecosystem as applications that are okay with higher latency in exchange for maximum security.Trustlessly reading EthereumAnother less-thought-about, but still highly important, form of connection has to do with a system's ability to read the Ethereum blockchain. Particularly, this includes being able to revert if Ethereum reverts. To see why this is valuable, consider the following situation: Suppose that, as shown in the diagram, the Ethereum chain reverts. This could be a temporary hiccup within an epoch, while the chain has not finalized, or it could be an inactivity leak period where the chain is not finalizing for an extended duration because too many validators are offline.The worst-case scenario that can arise from this is as follows. Suppose that the first block from the top chain reads some data from the leftmost block on the Ethereum chain. For example, someone on Ethereum deposits 100 ETH into the top chain. Then, Ethereum reverts. However, the top chain does not revert. As a result, future blocks of the top chain correctly follow new blocks from the newly correct Ethereum chain, but the consequences of the now-erroneous older link (namely, the 100 ETH deposit) are still part of the top chain. This exploit could allow printing money, turning the bridged ETH on the top chain into a fractional reserve.There are two ways to solve this problem:The top chain could only read finalized blocks of Ethereum, so it would never need to revert. The top chain could revert if Ethereum reverts. Both prevent this issue. The former is easier to implement, but may cause a loss of functionality for an extended duration if Ethereum enters an inactivity leak period. The latter is harder to implement, but ensures the best possible functionality at all times. Note that (1) does have one edge case. If a 51% attack on Ethereum creates two new incompatible blocks that both appear finalized at the same time, then the top chain may well lock on to the wrong one (ie. the one that Ethereum social consensus does not eventually favor), and would have to revert to switch to the right one. Arguably, there is no need to write code to handle this case ahead of time; it could simply be handled by hard-forking the top chain.The ability of a chain to trustlessly read Ethereum is valuable for two reasons:It reduces security issues involved in bridging tokens issued on Ethereum (or other L2s) to that chain It allows account abstraction wallets that use the shared keystore architecture to hold assets on that chain securely. is important, though arguably this need is already widely recognized. (2) is important too, because it means that you can have a wallet that allows easy key changes and that holds assets across a large number of different chains. Does having a bridge make you a validium?Suppose that the top chain starts out as a separate chain, and then someone puts onto Ethereum a bridge contract. A bridge contract is simply a contract that accepts block headers of the top chain, verifies that any header submitted to it comes with a valid certificate showing that it was accepted by the top chain's consensus, and adds that header to a list. Applications can build on top of this to implement functionality such as depositing and withdrawing tokens. Once such a bridge is in place, does that provide any of the asset security guarantees we mentioned earlier? So far, not yet! For two reasons:We're validating that the blocks were signed, but not that the state transitions are correct. Hence, if you have an asset issued on Ethereum deposited to the top chain, and the top chain's validators go rogue, they can sign an invalid state transition that steals those assets. The top chain still has no way to read Ethereum. Hence, you can't even deposit Ethereum-native assets onto the top chain without relying on some other (possibly insecure) third-party bridge. Now, let's make the bridge a validating bridge: it checks not just consensus, but also a ZK-SNARK proving that the state of any new block was computed correctly.Once this is done, the top chain's validators can no longer steal your funds. They can publish a block with unavailable data, preventing everyone from withdrawing, but they cannot steal (except by trying to extract a ransom for users in exchange for revealing the data that allows them to withdraw). This is the same security model as a validium.However, we still have not solved the second problem: the top chain cannot read Ethereum.To do that, we need to do one of two things:Put a bridge contract validating finalized Ethereum blocks inside the top chain. Have each block in the top chain contain a hash of a recent Ethereum block, and have a fork choice rule that enforces the hash linkings. That is, a top chain block that links to an Ethereum block that is not in the canonical chain is itself non-canonical, and if a top chain block links to an Ethereum block that was at first canonical, but then becomes non-canonical, the top chain block must also become non-canonical. The purple links can be either hash links or a bridge contract that verifies Ethereum's consensus. Is this enough? As it turns out, still no, because of a few small edge cases:What happens if Ethereum gets 51% attacked? How do you handle Ethereum hard fork upgrades? How do you handle hard fork upgrades of your chain? A 51% attack on Ethereum would have similar consequences to a 51% attack on the top chain, but in reverse. A hard fork of Ethereum risks making the bridge of Ethereum inside the top chain no longer valid. A social commitment to revert if Ethereum reverts a finalized block, and to hard-fork if Ethereum hard-forks, is the cleanest way to resolve this. Such a commitment may well never need to be actually executed on: you could have a governance gadget on the top chain activate if it sees proof of a possible attack or hard fork, and only hard-fork the top chain if the governance gadget fails.The only viable answer to (3) is, unfortunately, to have some form of governance gadget on Ethereum that can make the bridge contract on Ethereum aware of hard-fork upgrades of the top chain.Summary: two-way validating bridges are almost enough to make a chain a validium. The main remaining ingredient is a social commitment that if something exceptional happens in Ethereum that makes the bridge no longer work, the other chain will hard-fork in response.ConclusionsThere are two key dimensions to "connectedness to Ethereum":Security of withdrawing to Ethereum Security of reading Ethereum These are both important, and have different considerations. There is a spectrum in both cases: Notice that both dimensions each have two distinct ways of measuring them (so really there's four dimensions?): security of withdrawing can be measured by (i) security level, and (ii) what percent of users or use cases benefit from the highest security level, and security of reading can be measured by (i) how quickly the chain can read Ethereum's blocks, particularly finalized blocks vs any blocks, and (ii) the strength of the chain's social commitment to handle edge cases such as 51% attacks and hard forks.There is value in projects in many regions of this design space. For some applications, high security and tight connectedness are important. For others, something looser is acceptable in exhcnage for greater scalability. In many cases, starting with something looser today, and moving to a tighter coupling over the next decade as technology improves, may well be optimal.
-
Should Ethereum be okay with enshrining more things in the protocol? Should Ethereum be okay with enshrining more things in the protocol?2023 Sep 30 See all posts Should Ethereum be okay with enshrining more things in the protocol? Special thanks to Justin Drake, Tina Zhen and Yoav Weiss for feedback and review.From the start of the Ethereum project, there was a strong philosophy of trying to make the core Ethereum as simple as possible, and do as much as possible by building protocols on top. In the blockchain space, the "do it on L1" vs "focus on L2s" debate is typically thought of as being primarily about scaling, but in reality, similar issues exist for serving many kinds of Ethereum users' needs: digital asset exchange, privacy, usernames, advanced cryptography, account safety, censorship resistance, frontrunning protection, and the list goes on. More recently, however, there has been some cautious interest in being willing to enshrine more of these features into the core Ethereum protocol.This post will go into some of the philosophical reasoning behind the original minimal-enshrinement philosophy, as well as some more recent ways of thinking about some of these ideas. The goal will be to start to build toward a framework for better identifying possible targets where enshrining certain features in the protocol might be worth considering.Early philosophy on protocol minimalismEarly on in the history of what was then called "Ethereum 2.0", there was a strong desire to create a clean, simple and beautiful protocol that tried to do as little as possible itself, and left almost everything up to users to build on top. Ideally, the protocol would just be a virtual machine, and verifying a block would just be a single virtual machine call. A very approximate reconstruction-from-memory of a whiteboard drawing Gavin Wood and I made back in early 2015, talking about what Ethereum 2.0 would look like. The "state transition function" (the function that processes a block) would just be a single VM call, and all other logic would happen through contracts: a few system-level contracts, but mostly contracts provided by users. One really nice feature of this model is that even an entire hard fork could be described as a single transaction to the block processor contract, which would be approved through either offchain or onchain governance and then run with escalated permissions.These discussions back in 2015 particularly applied to two areas that were on our minds: account abstraction and scaling. In the case of scaling, the idea was to try to create a maximally abstracted form of scaling that would feel like a natural extension of the diagram above. A contract could make a call to a piece of data that was not stored by most Ethereum nodes, and the protocol would detect that, and resolve the call through some kind of very generic scaled-computation functionality. From the virtual machine's point of view, the call would go off into some separate sub-system, and then some time later magically come back with the correct answer.This line of thinking was explored briefly, but soon abandoned, because we were too preoccupied with verifying that any kind of blockchain scaling was possible at all. Though as we will see later, the combination of data availability sampling and ZK-EVMs means that one possible future for Ethereum scaling might actually look surprisingly close to that vision! For account abstraction, on the other hand, we knew from the start that some kind of implementation was possible, and so research immediately began to try to make something as close as possible to the purist starting point of "a transaction is just a call" into reality. There is a lot of boilerplate code that occurs in between processing a transaction and making the actual underlying EVM call out of the sender address, and a lot more boilerplate that comes after. How do we reduce this code to as close to nothing as possible? One of the major pieces of code in here is validate_transaction(state, tx), which does things like checking that the nonce and signature of the transaction are correct. The practical goal of account abstraction was, from the start, to allow the user to replace basic nonce-incrementing and ECDSA validation with their own validation logic, so that users could more easily use things like social recovery and multisig wallets. Hence, finding a way to rearchitect apply_transaction into just being a simple EVM call was not simply a "make the code clean for the sake of making the code clean" task; rather, it was about moving the logic into the user's account code, to give users that needed flexibility.However, the insistence on trying to make apply_transaction contain as little enshrined logic as possible ended up introducing a lot of challenges. To see why, let us zoom in on one of the earliest account abstraction proposals, EIP 86:SpecificationIf block.number >= METROPOLIS_FORK_BLKNUM, then: 1. If the signature of a transaction is (0, 0, 0) (ie. v = r = s = 0), then treat it as valid and set the sender address to 2**160 - 1 2. Set the address of any contract created through a creation transaction to equal sha3(0 + init code) % 2**160, where + represents concatenation, replacing the earlier address formula of sha3(rlp.encode([sender, nonce])) 3. Create a new opcode at 0xfb, CREATE_P2SH, which sets the creation address to sha3(sender + init code) % 2**160. If a contract at that address already exists, fails and returns 0 as if the init code had run out of gas.Basically, if the signature is set to (0, 0, 0), then a transaction really does become "just a call". The account itself would be responsible for having code that parses the transaction, extracts and verifies the signature and nonce, and pays fees; see here for an early example version of that code, and see here for the very similar validate_transaction code that this account code would be replacing.In exchange for this simplicity at protocol layer, miners (or, today, block proposers) gain the additional responsibility of running extra logic for only accepting and forwarding transactions that go to accounts whose code is set up to actually pay fees. What is that logic? Well, honestly EIP-86 did not think too hard about it:Note that miners would need to have a strategy for accepting these transactions. This strategy would need to be very discriminating, because otherwise they run the risk of accepting transactions ) for the validate_transaction code that this pre-account code would be replacingthat do not pay them any fees, and possibly even transactions that have no effect (eg. because the transaction was already included and so the nonce is no longer current). One simple approach is to have a whitelist for the codehash of accounts that they accept transactions being sent to; approved code would include logic that pays miners transaction fees. However, this is arguably too restrictive; a looser but still effective strategy would be to accept any code that fits the same general format as the above, consuming only a limited amount of gas to perform nonce and signature checks and having a guarantee that transaction fees will be paid to the miner. Another strategy is to, alongside other approaches, try to process any transaction that asks for less than 250,000 gas, and include it only if the miner's balance is appropriately higher after executing the transaction than before it.If EIP-86 had been included as-is, it would have reduced the complexity of the EVM, at the cost of massively increasing the complexity of other parts of the Ethereum stack, requiring essentially the exact same code to be written in other places, in addition to introducing entirely new classes of weirdness such as the possibility that the same transaction with the same hash might appear multiple times in the chain, not to mention the multi-invalidation problem. The multi-invalidation problem in account abstraction. One transaction getting included on chain could invalidate thousands of other transactions in the mempool, making the mempool easy to cheaply flood. Acccount abstraction evolved in stages from there. EIP-86 became EIP-208, which later became this ethresear.ch post on "tradeoffs in account abstraction proposals", which then became this ethresear.ch post half a year later. Eventually, out of all this, came the actually somewhat-workable EIP-2938.EIP-2938, however, was not minimalistic at all. The EIP includes:A new transaction type Three new transaction-wide global variables Two new opcodes, including the highly unwieldy PAYGAS opcode that handles gas price and gas limit checking, being an EVM execution breakpoint, and temporarily storing ETH for fee payments all at once. A set of complex mining and rebroadcasting strategies, including a list of banned opcodes for the validation phase of a transaction In order to get account abstraction off the ground without involving Ethereum core developers who were busy on heroic efforts optimizing the Ethereum clients and implementing the merge, EIP-2938 eventually was rearchitected into the entirely extra-protocol ERC-4337. ERC-4337. It really does rely entirely on EVM calls for everything! Because it's an ERC, it does not require a hard fork, and technically lives "outside of the Ethereum protocol". So.... problem solved? Well, as it turns out, not quite. The current medium-term roadmap for ERC-4337 actually does involve eventually turning large parts of ERC-4337 into a series of protocol features, and it's a useful instructive example to see the reasons why this path is being considered.Enshrining ERC-4337There have been a few key reasons discussed for eventually bringing ERC-4337 back into the protocol:Gas efficiency: Anything done inside the EVM incurs some level of virtual machine overhead, including inefficiency in how it uses gas-expensive features like storage slots. Currently, these extra inefficiencies add up to at least ~20,000 gas, and often more. Pushing these components into the protocol is the easiest way to remove these issues. Code bug risk: if the ERC-4337 "entry point contract" has a sufficiently terrible bug, all ERC-4337-compatible wallets could see all of their funds drained. Replacing the contract with an in-protocol functionality creates an implied responsibility to fix code bugs with a hard fork, which removes funds-draining risk for users. Support for EVM opcodes like tx.origin. ERC-4337, by itself, makes tx.origin return the address of the "bundler" that packaged up a set of user operations into a transaction. Native account abstraction could fix this, by making tx.origin point to the actual account sending the transaction, making it work the same way as for EOAs. Censorship resistance: one of the challenges with proposer/builder separation is that it becomes easier to censor individual transactions. In a world where individual transactions are legible to the Ethereum protocol, this problem can be greatly mitigated with inclusion lists, which allow proposers to specify a list of transactions that must be included within the next two slots in almost all cases. But the extra-protocol ERC-4337 wraps "user operations" inside a single transaction, making user operations opaque to the Ethereum protocol; hence, Ethereum-protocol-provided inclusion lists would not be able to provide censorship resistance to ERC-4337 user operations. Enshrining ERC-4337, and making user operations a "proper" transaction type, would solve this problem. It's worth zooming into the gas efficiency issue further. In its current form, ERC-4337 is significantly more expensive than a "basic" Ethereum transaction: the transaction costs 21,000 gas, whereas ERC-4337 costs ~42,000 gas. This doc lists some of the reasons why:Need to pay lots of individual storage read/write costs, which in the case of EOAs get bundled into a single 21000 gas payment: Editing the storage slot that contains pubkey+nonce (~5000) UserOperation calldata costs (~4500, reducible to ~2500 with compression) ECRECOVER (~3000) Warming the wallet itself (~2600) Warming the recipient account (~2600) Transferring ETH to the recipient account (~9000) Editing storage to pay fees (~5000) Access the storage slot containing the proxy (~2100) and then the proxy itself (~2600) On top of the above storage read/write costs, the contract needs to do "business logic" (unpacking the UserOperation, hashing it, shuffling variables, etc) that EOA transactions have handled "for free" by the Ethereum protocol Need to expend gas to pay for logs (EOAs don't issue logs) One-time contract creation costs (~32000 base, plus 200 gas per code byte in the proxy, plus 20000 to set the proxy address) Theoretically, it should be possible to massage the EVM gas cost system until the in-protocol costs and the extra-protocol costs for accessing storage match; there is no reason why transferring ETH needs to cost 9000 gas when other kinds of storage-editing operations are much cheaper. And indeed, two EIPs ([1] [2]) related to the upcoming Verkle tree transition actually try to do that. But even if we do that, there is one huge reason why enshrined protocol features are going to inevitably be significantly cheaper than EVM code, no matter how efficient the EVM becomes: enshrined code does not need to pay gas for being pre-loaded.Fully functional ERC-4337 wallets are big. This implementation, compiled and put on chain, takes up ~12,800 bytes. Of course, you can deploy that big piece of code once, and use DELEGATECALL to allow each individual wallet to call into it, but that code still needs to be accessed in each block that uses it. Under the Verkle tree gas costs EIP, 12,800 bytes would make up 413 chunks, and accessing those chunks would require paying 2x WITNESS_BRANCH_COST (3,800 gas total) and 413x WITNESS_CHUNK_COST (82,600 gas total). And this does not even begin to mention the ERC-4337 entry-point itself, with 23,689 bytes onchain in version 0.6.0 (under the Verkle tree EIP rules, ~158,700 gas to load).This leads to a problem: the gas costs of actually accessing this code would have to be split among transactions somehow. The current approach that ERC-4337 uses is not great: the first transaction in a bundle eats up one-time storage/code reading costs, making it much more expensive than the rest of the transactions. Enshrinement in-protocol would allow these commonly-shared libraries to simply be part of the protocol, accessible to all with no fees.What can we learn from this example about when to enshrine things more generally?In this example, we saw a few different rationales for enshrining aspects of account abstraction in the protocol."Move complexity to the edges" market-based approaches break down the most when there are high fixed costs. And indeed, the long term account abstraction roadmap looks like it's going to have lots of fixed costs per block. 244,100 gas for loading standardized wallet code is one thing; but aggregation (see my presentation from this summer for more details) potentially adds hundreds of thousands more gas for ZK-SNARK validation plus onchain costs for proof verification. There isn't a way to charge users for these costs without introducing lots of market inefficiencies, whereas making some of these functionalities into protocol features accessible to all with no fees cleanly solves that problem. Community-wide response to code bugs. If some set of pieces of code are used by all users, or a very wide class of users, then it often makes more sense for the blockchain community to take on itself the responsibility to hard-fork to fix any bugs that arise. ERC-4337 introduced a large amount of globally shared code, and in the long term it makes more sense for bugs in that code to be fixed by hard forks than to lead to users losing a large amount of ETH. Sometimes, a stronger form of a feature can be implemented by directly taking advantage of the powers of the protocol. The key example here is in-protocol censorship resistance features like inclusion lists: in-protocol inclusion lists can do a better job of guaranteeing censorship resistance than extra-protocol approaches, in order for user-level operations to actually benefit from in-protocol inclusion lists, individual user-level operations need to be "legible" to the protocol. Another lesser-known example is that 2017-era Ethereum proof of stake designs had account abstraction for staking keys, and this was abandoned in favor of enshrining BLS because BLS supported an "aggregation" mechanism, which would have to be implemented at protocol and network level, that could make handling a very large number of signatures much more efficient. But it is important to remember that even enshrined in-protocol account abstraction is still a massive "de-enshrinement" compared to the status quo. Today, top-level Ethereum transactions can only be initiated from externally owned accounts (EOAs) which use a single secp256k1 elliptic curve signature for verification. Account abstraction de-enshrines this, and leaves verification conditions open for users to define. And so, in this story about account abstraction, we also saw the biggest argument against enshrinement: being flexible to diverse users' needs. Let us try to fill in the story further, by looking at a few other examples of features that have recently been considered for enshrinement. We'll particularly focus on: ZK-EVMs, proposer-builder separation, private mempools, liquid staking and new precompiles.Enshrining ZK-EVMsLet us switch focus to another potential target for enshrining into the Ethereum protocol: ZK-EVMs. Currently, we have a large number of ZK-rollups that all have to write fairly similar code to verify execution of Ethereum-like blocks inside a ZK-SNARK. There is a pretty diverse ecosystem of independent implementations: the PSE ZK-EVM, Kakarot, the Polygon ZK-EVM, Linea, Zeth, and the list goes on.One of the recent controversies in the EVM ZK-rollup space has to do with how to deal with the possibility of bugs in the ZK-code. Currently, all of these systems that are live have some form of "security council" mechanism that can override the proving system in case of a bug. In this post last year, I tried to create a standardized framework to encourage projects to be clear about what level of trust they put in the proving system and what level in the security council, and move toward giving less and less powers to the security council over time. In the medium term, rollups could rely on multiple proving systems, and the security council would only have any power at all in the extreme case where two different proving systems disagree with each other. However, there is a sense in which some of this work feels superfluous. We already have the Ethereum base layer, which has an EVM, and we already have a working mechanism for dealing with bugs in implementations: if there's a bug, the clients that have the bug update to fix the bug, and the chain goes on. Blocks that appeared finalized from the perspective of a buggy client would end up no-longer-finalized, but at least we would not see users losing funds. Similarly, if a rollup just wants to be and remain EVM-equivalent, it feels wrong that they need to implement their own governance to keep changing their internal ZK-EVM rules to match upgrades to the Ethereum base layer, when ultimately they're building on top of the Ethereum base layer itself, which knows when it's being upgraded and to what new rules.Since these L2 ZK-EVMs are basically using the exact same EVM as Ethereum, can't we somehow make "verify EVM execution in ZK" into a protocol feature, and deal with exceptional situations like bugs and upgrades by just applying Ethereum's social consensus, the same way we already do for base-layer EVM execution itself?This is an important and challenging topic. There are a few nuances:We want to be compatible with Ethereum's multi-client philosophy. This means that we want to allow different clients to use different proving systems. This in turn implies that for any EVM execution that gets proven with one ZK-SNARK system, we want a guarantee that the underlying data is available, so that proofs can be generated for other ZK-SNARK systems. While the tech is immature, we probably want auditability. In practice, this means the exact same thing: if any execution gets proven, we want the underlying data to be available, so that if anything goes wrong, users and developers can inspect it. We need much faster proving times, so that if one type of proof is made, other types of proof can be generated quickly enough that other clients can validate them. One could get around this by making a precompile that has an asynchronous response after some time window longer than a slot (eg. 3 hours), but this adds complexity. We want to support not just copies of the EVM, but also "almost-EVMs". Part of the attraction of L2s is the ability to innovate on the execution layer, and make extensions to the EVM. If a given L2's VM differs from the EVM only a little bit, it would be nice if the L2 could still use a native in-protocol ZK-EVM for the parts that are identical to the EVM, and only rely on their own code for the parts that are different. This could be done by designing the ZK-EVM precompile in such a way that it allows the caller to specify a bitfield or list of opcodes or addresses that get handled by an externally supplied table instead of the EVM itself. We could also make gas costs open to customization to a limited extent. One likely topic of contention with data availability in a native ZK-EVM is statefulness. ZK-EVMs are much more data-efficient if they do not have to carry "witness" data. That is, if a particular piece of data was already read or written in some previous block, we can simply assume that provers have access to it, and we don't have to make it available again. This goes beyond not re-loading storage and code; it turns out that if a rollup properly compresses data, the compression being stateful allows for up to 3x data savings compared to the compression being stateless. This means that for a ZK-EVM precompile, we have two options:The precompile requires all data to be available in the same block. This means that provers can be stateless, but it also means that ZK-rollups using such a precompile become much more expensive than rollups using custom code. The precompile allows pointers to data used or generated by previous executions. This allows ZK-rollups to be near-optimal, but it's more complicated and introduces a new kind of state that has to be stored by provers. What lessons can we take away from this? There is a pretty good argument to enshrine ZK-EVM validation somehow: rollups are already building their own custom versions of it, and it feels wrong that Ethereum is willing to put the weight of its multiple implementations and off-chain social consensus behind EVM execution on L1, but L2s doing the exact same work have to instead implement complicated gadgets involving security councils. But on the other hand, there is a big devil in the details: there are different versions of an enshrined ZK-EVM that have different costs and benefits. The stateful vs stateless divide only scratches the surface; attempting to support "almost-EVMs" that have custom code proven by other systems will likely reveal an even larger design space. Hence, enshrining ZK-EVMs presents both promise and challenges.Enshrining proposer-builder separation (ePBS)The rise of MEV has made block production into an economies-of-scale-heavy activity, with sophisticated actors being able to produce blocks that generate much more revenue than default algorithms that simply watch the mempool for transactions and include them. The Ethereum community has so far attempted to deal with this by using extra-protocol proposer-builder separation schemes like MEV-Boost, which allow regular validators ("proposers") to outsource block building to specialized actors ("builders").However, MEV-Boost carries a trust assumption in a new category of actor, called a relay. For the past two years, there have been many proposals to create "enshrined PBS". What is the benefit of this? In this case, the answer is pretty simple: the PBS that can be built by directly using the powers of the protocol is simply stronger (in the sense of having weaker trust assumptions) than the PBS that can be built without them. It's a similar case to the case for enshrining in-protocol price oracles - though, in that situation, there is also a strong counterargument.Enshrining private mempoolsWhen a user sends a transaction, that transaction becomes immediately public and visible to all, even before it gets included on chain. This makes users of many applications vulnerable to economic attacks such as frontrunning: if a user makes a large trade on eg. Uniswap, an attacker could put in a transaction right before them, increasing the price at which they buy, and collecting an arbitrage profit.Recently, there has been a number of projects specializing in creating "private mempools" (or "encrypted mempools"), which keep users' transactions encrypted until the moment they get irreversibly accepted into a block.The problem is, however, that schemes like this require a particular kind of encryption: to prevent users from flooding the system and frontrunning the decryption process itself, the encryption must auto-decrypt once the transaction actually does get irreversibly accepted.To implement such a form of encryption, there are various different technologies with different tradeoffs, described well in this post by Jon Charbonneau (and this video and slides):Encryption to a centralized operator, eg. Flashbots Protect. Time-lock encryption, a form of encryption which can be decrypted by anyone after a certain number of sequential computational steps, which cannot be parallelized. Threshold encryption, trusting an honest majority committee to decrypt the data. See the shutterized beacon chain concept for a concrete proposal. Trusted hardware such as SGX. Unfortunately, each of these have varying weaknesses. A centralized operator is not acceptable for inclusion in-protocol for obvious reasons. Traditional time lock encryption is too expensive to run across thousands of transactions in a public mempool. A more powerful primitive called delay encryption allows efficient decryption of an unlimited number of messages, but it's hard to construct in practice, and attacks on existing constructions still sometimes get discovered. Much like with hash functions, we'll likely need a period of more years of research and analysis before delay encryption becomes sufficiently mature. Threshold encryption requires trusting a majority to not collude, in a setting where they can collude undetectably (unlike 51% attacks, where it's immediately obvious who participated). SGX creates a dependency on a single trusted manufacturer.While for each solution, there is some subset of users that is comfortable trusting it, there is no single solution that is trusted enough that it can practically be accepted into layer 1. Hence, enshrining anti-frontrunning at layer 1 seems like a difficult proposition at least until delay encrypted is perfected or there is some other technological breakthrough, even while it's a valuable enough functionality that lots of application solutions will already emerge.Enshrining liquid stakingA common demand among Ethereum defi users is the ability to use their ETH for staking and as collateral in other applications at the same time. Another common demand is simply for convenience: users want to be able to stake without the complexity of running a node and keeping it online all the time (and protecting their now-online staking keys).By far the simplest possible "interface" for staking, which satisfies both of these needs, is just an ERC20 token: convert your ETH into "staked ETH", hold it, and then later convert back. And indeed, liquid staking providers such as Lido and Rocketpool have emerged to do just that. However, liquid staking has some natural centralizing mechanics at play: people naturally go into the biggest version of staked ETH because it's most familiar and most liquid (and most well-supported by applications, who in turn support it because it's more familiar and because it's the one the most users will have heard of).Each version of staked ETH needs to have some mechanism determining who can be the underlying node operators. It can't be unrestricted, because then attackers would join and amplify their attacks with users' funds. Currently, the top two are Lido, which has a DAO whitelisting node operators, and Rocket Pool, which allows anyone to run a node if they put down 8 ETH (ie. 1/4 of the capital) as a deposit. These two approaches have different risks: the Rocket Pool approach allows attackers to 51% attack the network, and force users to pay most of the costs. With the DAO approach, if a single such staking token dominates, that leads to a single, potentially attackable governance gadget controlling a very large portion of all Ethereum validators. To the credit of protocols like Lido, they have implemented safeguards against this, but one layer of defense may not be enough. In the short term, one option is to socially encourage ecosystem participants to use a diversity of liquid staking providers, to reduce the chance that any single one becomes too large to be a systemic risk. In the longer term, however, this is an unstable equilibrium, and there is peril in relying too much on moralistic pressure to solve problems. One natural question arises: might it make sense to enshrine some kind of in-protocol functionality to make liquid staking less centralizing?Here, the key question is: what kind of in-protocol functionality? Simply creating an in-protocol fungible "staked ETH" token has the problem that it would have to either have an enshrined Ethereum-wide governance to choose who runs the nodes, or be open-entry, turning it into a vehicle for attackers.One interesting idea is Dankrad Feist's writings on liquid staking maximalism. First, we bite the bullet that if Ethereum gets 51% attacked, only perhaps 5% of the attacking ETH gets slashed. This is a reasonable tradeoff; right now there is over 26 million ETH being staked, and a cost of attack of 1/3 of that (~8 million ETH) is way overkill, especially considering how many kinds of "outside-the-model" attacks can be pulled off for much less. Indeed, a similar tradeoff has already been explored in the "super-committee" proposal for implementing single-slot finality. If we accept that only 5% of attacking ETH gets slashed, then over 90% of staked ETH would be invulnerable to slashing, and so 90% of staked ETH could be put into an in-protocol fungible liquid staking token that can then be used by other applications.This path is interesting. But it still leaves open the question: what is the specific thing that would get enshrined? RocketPool already works in a way very similar to this: each node operator puts up some capital, and liquid stakers put up the rest. We could simply tweak a few constants, bounding the maximum slashing penalty to eg. 2 ETH, and Rocket Pool's existing rETH would become risk-free.There are other clever things that we can do with simple protocol tweaks. For example, imagine that we want a system where there are two "tiers" of staking: node operators (high collateral requirement) and depositors (no minimum, can join and leave any time), but we still want to guard against node operator centralization by giving a randomly-sampled committee of depositors powers like suggesting lists of transactions that have to be included (for anti-censorship reasons), controlling the fork choice during an inactivity leak, or needing to sign off on blocks. This could be done in a mostly-out-of-protocol way, by tweaking the protocol to require each validator to provide (i) a regular staking key, and (ii) an ETH address that can be called to output a secondary staking key during each slot. The protocol would give powers to these two keys, but the mechanism for choosing the second key in each slot could be left to staking pool protocols. It may still be better to enshrine some things outright, but it's valuable to note that this "enshrine some things, leave other things to users" design space exists.Enshrining more precompilesPrecompiles (or "precompiled contracts") are Ethereum contracts that implement complex cryptographic operations, whose logic is natively implemented in client code, instead of EVM smart contract code. Precompiles were a compromise adopted at the beginning of Ethereum's development: because the overhead of a VM is too much for certain kinds of very complex and highly specialized code, we can implement a few key operations valuable to important kinds of applications in native code to make them faster. Today, this basically includes a few specific hash functions and elliptic curve operations.There is currently a push to add a precompile for secp256r1, an elliptic curve slightly different from the secp256k1 used for basic Ethereum accounts, because it is well-supported by trusted hardware modules and thus widespread use of it could improve wallet security. In recent years, there have also been pushes to add precompiles for BLS-12-377, BW6-761, generalized pairings and other features.The counterargument to these requests for more precompiles is that many of the precompiles that have been added before (eg. RIPEMD and BLAKE) have ended up gotten used much less than anticipated, and we should learn from that. Instead of adding more precompiles for specific operations, we should perhaps focus on a more moderate approach based on ideas like EVM-MAX and the dormant-but-always-revivable SIMD proposal, which would allow EVM implementations to execute wide classes of code less expensively. Perhaps even existing little-used precompiles could be removed and replaced with (unavoidably less efficient) EVM code implementations of the same function. That said, it is still possible that there are specific cryptographic operations that are valuable enough to accelerate that it makes sense to add them as precompiles.What do we learn from all this?The desire to enshrine as little as possible is understandable and good; it hails from the Unix philosophy tradition of creating software that is minimalist and can be easily adapted to different needs by its users, avoiding the curses of software bloat. However, blockchains are not personal-computing operating systems; they are social systems. This means that there are rationales for enshrining certain features in the protocol that go beyond the rationales that exist in a purely personal-computing context.In many cases, these other examples re-capped similar lessons to what we saw in account abstraction. But there are also a few new lessons that have been learned as well:Enshrining features can help avoid centralization risks in other areas of the stack. Often, keeping the base protocol minimal and simple pushes the complexity to some outside-the-protocol ecosystem. From a Unix philosophy perspective, this is good. Sometimes, however, there are risks that that outside-the-protocol ecosystem will centralize, often (but not just) because of high fixed costs. Enshrining can sometimes decrease de-facto centralization. Enshrining too much can over-extend the trust and governance load of the protocol. This is the topic of this earlier post about not overloading Ethereum's consensus: if enshrining a particular feature weakens the trust model, and makes Ethereum as a whole much more "subjective", that weakens Ethereum's credible neutrality. In those cases, it's better to leave that particular feature as a mechanism on top of Ethereum, and not try to bring it inside Ethereum itself. Here, encrypted mempools are the best example of something that may be a bit too difficult to enshrine, at least until/unless delay encryption technology improves. Enshrining too much can over-complicate the protocol. Protocol complexity is a systemic risk, and adding too many features in-protocol increases that risk. Precompiles are the best example of this. Enshrining can backfire in the long term, as users' needs are unpredictable. A feature that many people think is important and will be used by many users may well turn out not to be used much in practice. Additionally, the liquid staking, ZK-EVM and precompile cases show the possibility of a middle road: minimal viable enshrinement. Rather than enshrining an entire functionality, the protocol could enshrine a specific piece that solves the key challenges with making that functionality easy to implement, without being too opinionated or narrowly focused. Examples of this include:Rather than enshrining a full liquid staking system, changing staking penalty rules to make trustless liquid staking more viable Rather than enshrining more precompiles, enshrine EVM-MAX and/or SIMD to make a wider class of operations simpler to implement efficiently Rather than enshrining the whole concept of rollups, we could simply enshrine EVM verification. We can extend our diagram from earlier in the post as follows: Sometimes, it may even make sense to de-enshrine a few things. De-enshrining little-used precompiles is one example. Account abstraction as a whole, as mentioned earlier, is also a significant form of de-enshrinement. If we want to support backwards-compatibility for existing users, then the mechanism may actually be surprisingly similar to that for de-enshrining precompiles: one of the proposals is EIP-5003, which would allow EOAs to convert their account in-place into a contract that has the same (or better) functionality.What features should be brought into the protocol and what features should be left to other layers of the ecosystem is a complicated tradeoff, and we should expect the tradeoff to continue to evolve over time as our understanding of users' needs and our suite of available ideas and technologies continues to improve.
-
What do I think about Community Notes? What do I think about Community Notes?2023 Aug 16 See all posts What do I think about Community Notes? Special thanks to Dennis Pourteaux and Jay Baxter for feedback and review.The last two years of Twitter X have been tumultuous, to say the least. After the platform was bought not bought bought by Elon Musk for $44 billion last year, Elon enacted sweeping changes to the company's staffing, content moderation and business model, not to mention changes to the culture on the site that may well have been a result of Elon's soft power more than any specific policy decision. But in the middle of these highly contentious actions, one new feature on Twitter grew rapidly in importance, and seems to be beloved by people across the political spectrum: Community Notes. Community Notes is a fact-checking tool that sometimes attaches context notes, like the one on Elon's tweet above, to tweets as a fact-checking and anti-misinformation tool. It was originally called Birdwatch, and was first rolled out as a pilot project in January 2021. Since then, it has expanded in stages, with the most rapid phase of its expansion coinciding with Twitter's takeover by Elon last year. Today, Community Notes appear frequently on tweets that get a very large audience on Twitter, including those on contentious political topics. And both in my view, and in the view of many people across the political spectrum I talk to, the notes, when they appear, are informative and valuable.But what interests me most about Community Notes is how, despite not being a "crypto project", it might be the closest thing to an instantiation of "crypto values" that we have seen in the mainstream world. Community Notes are not written or curated by some centrally selected set of experts; rather, they can be written and voted on by anyone, and which notes are shown or not shown is decided entirely by an open source algorithm. The Twitter site has a detailed and extensive guide describing how the algorithm works, and you can download the data containing which notes and votes have been published, run the algorithm locally, and verify that the output matches what is visible on the Twitter site. It's not perfect, but it's surprisingly close to satisfying the ideal of credible neutrality, all while being impressively useful, even under contentious conditions, at the same time.How does the Community Notes algorithm work?Anyone with a Twitter account matching some criteria (basically: active for 6+ months, no recent rule violations, verified phone number) can sign up to participate in Community Notes. Currently, participants are slowly and randomly being accepted, but eventually the plan is to let in anyone who fits the criteria. Once you are accepted, you can at first participate in rating existing notes, and once you've made enough good ratings (measured by seeing which ratings match with the final outcome for that note), you can also write notes of your own.When you write a note, the note gets a score based on the reviews that it receives from other Community Notes members. These reviews can be thought of as being votes along a 3-point scale of HELPFUL, SOMEWHAT_HELPFUL and NOT_HELPFUL, but a review can also contain some other tags that have roles in the algorithm. Based on these reviews, a note gets a score. If the note's score is above 0.40, the note is shown; otherwise, the note is not shown.The way that the score is calculated is what makes the algorithm unique. Unlike simpler algorithms, which aim to simply calculate some kind of sum or average over users' ratings and use that as the final result, the Community Notes rating algorithm explicitly attempts to prioritize notes that receive positive ratings from people across a diverse range of perspectives. That is, if people who usually disagree on how they rate notes end up agreeing on a particular note, that note is scored especially highly.Let us get into the deep math of how this works. We have a set of users and a set of notes; we can create a matrix \(M\), where the cell \(M_\) represents how the i'th user rated the j'th note. For any given note, most users have not rated that note, so most entries in the matrix will be zero, but that's fine. The goal of the algorithm is to create a four-column model of users and notes, assigning each user two stats that we can call "friendliness" and "polarity", and each note two stats that we can call "helpfulness" and "polarity". The model is trying to predict the matrix as a function of these values, using the following formula: Note that here I am introducing both the terminology used in the Birdwatch paper, and my own terms to provide a less mathematical intuition for what the variables mean:μ is a "general public mood" parameter that accounts for how high the ratings are that users give in general \(i_u\) is a user's "friendliness": how likely that particular user is to give high ratings \(i_n\) is a note's "helpfulness": how likely that particular note is to get rated highly. Ultimately, this is the variable we care about. \(f_u\) or \(f_n\) is user or note's "polarity": its position among the dominant axis of political polarization. In practice, negative polarity roughly means "left-leaning" and positive polarity means "right-leaning", but note that the axis of polarization is discovered emergently from analyzing users and notes; the concepts of leftism and rightism are in no way hard-coded. The algorithm uses a pretty basic machine learning model (standard gradient descent) to find values for these variables that do the best possible job of predicting the matrix values. The helpfulness that a particular note is assigned is the note's final score. If a note's helpfulness is at least +0.4, the note gets shown.The core clever idea here is that the "polarity" terms absorb the properties of a note that cause it to be liked by some users and not others, and the "helpfulness" term only measures the properties that a note has that cause it to be liked by all. Thus, selecting for helpfulness identifies notes that get cross-tribal approval, and selects against notes that get cheering from one tribe at the expense of disgust from the other tribe.I made a simplified implementation of the basic algorithm; you can find it here, and are welcome to play around with it.Now, the above is only a description of the central core of the algorithm. In reality, there are a lot of extra mechanisms bolted on top. Fortunately, they are described in the public documentation. These mechanisms include the following:The algorithm gets run many times, each time adding some randomly generated extreme "pseudo-votes" to the votes. This means that the algorithm's true output for each note is a range of values, and the final result depends on a "lower confidence bound" taken from this range, which is checked against a threshold of 0.32. If many users (especially users with a similar polarity to the note) rate a note "Not Helpful", and furthermore they specify the same "tag" (eg. "Argumentative or biased language", "Sources do not support note") as the reason for their rating, the helpfulness threshold required for the note to be published increases from 0.4 to 0.5 (this looks small but it's very significant in practice) If a note is accepted, the threshold that its helpfulness must drop below to de-accept it is 0.01 points lower than the threshold that a note's helpfulness needed to reach for the note to be originally accepted The algorithm gets run even more times with multiple models, and this can sometimes promote notes whose original helpfulness score is somewhere between 0.3 and 0.4 All in all, you get some pretty complicated python code that amounts to 6282 lines stretching across 22 files. But it is all open, you can download the note and rating data and run it yourself, and see if the outputs correspond to what is actually on Twitter at any given moment.So how does this look in practice?Probably the single most important idea in this algorithm that distinguishes it from naively taking an average score from people's votes is what I call the "polarity" values. The algorithm documentation calls them \(f_u\) and \(f_n\), using \(f\) for factor because these are the two terms that get multiplied with each other; the more general language is in part because of a desire to eventually make \(f_u\) and \(f_n\) multi-dimensional.Polarity is assigned to both users and notes. The link between user IDs and the underlying Twitter accounts is intentionally kept hidden, but notes are public. In practice, the polarities generated by the algorithm, at least for the English-language data set, map very closely to the left vs right political spectrum.Here are some examples of notes that have gotten polarities around -0.8: Note Polarity Anti-trans rhetoric has been amplified by some conservative Colorado lawmakers, including U.S. Rep. Lauren Boebert, who narrowly won re-election in Colorado's GOP-leaning 3rd Congressional District, which does not include Colorado Springs. https://coloradosun.com/2022/11/20/colorado-springs-club-q-lgbtq-trans/ -0.800 President Trump explicitly undermined American faith in election results in the months leading up to the 2020 election. https://www.npr.org/2021/02/08/965342252/timeline-what-trump-told-supporters-for-months-before-they-attacked Enforcing Twitter's Terms of Service is not election interference. -0.825 The 2020 election was conducted in a free and fair manner. https://www.npr.org/2021/12/23/1065277246/trump-big-lie-jan-6-election -0.818 Note that I am not cherry-picking here; these are literally the first three rows in the scored_notes.tsv spreadsheet generated by the algorithm when I ran it locally that have a polarity score (called coreNoteFactor1 in the spreadsheet) of less than -0.8.Now, here are some notes that have gotten polarities around +0.8. It turns out that many of these are either people talking about Brazilian politics in Portuguese or Tesla fans angrily refuting criticism of Tesla, so let me cherry-pick a bit to find a few that are not: Note Polarity As of 2021 data, 64% of "Black or African American" children lived in single-parent families. https://datacenter.aecf.org/data/tables/107-children-in-single-parent-families-by-race-and-ethnicity +0.809 Contrary to Rolling Stones push to claim child trafficking is "a Qanon adjacent conspiracy," child trafficking is a real and huge issue that this movie accurately depicts. Operation Underground Railroad works with multinational agencies to combat this issue. https://ourrescue.org/ +0.840 Example pages from these LGBTQ+ children's books being banned can be seen here: https://i.imgur.com/8SY6cEx.png These books are obscene, which is not protected by the US constitution as free speech. https://www.justice.gov/criminal-ceos/obscenity "Federal law strictly prohibits the distribution of obscene matter to minors. +0.806 Once again, it is worth reminding ourselves that the "left vs right divide" was not in any way hardcoded into the algorithm; it was discovered emergently by the calculation. This suggests that if you apply this algorithm in other cultural contexts, it could automatically detect what their primary political divides are, and bridge across those too.Meanwhile, notes that get the highest helpfulness look like this. This time, because these notes are actually shown on Twitter, I can just screenshot one directly: And another one: The second one touches on highly partisan political themes more directly, but it's a clear, high-quality and informative note, and so it gets rated highly. So all in all, the algorithm seems to work, and the ability to verify the outputs of the algorithm by running the code seems to work.What do I think of the algorithm?The main thing that struck me when analyzing the algorithm is just how complex it is. There is the "academic paper version", a gradient descent which finds a best fit to a five-term vector and matrix equation, and then the real version, a complicated series of many different executions of the algorithm with lots of arbitrary coefficients along the way.Even the academic paper version hides complexity under the hood. The equation that it's optimizing is a degree-4 equation (as there's a degree-2 \(f_u * f_n\) term in the prediction formula, and compounding that the cost function measures error squared). While optimizing a degree-2 equation over any number of variables almost always has a unique solution, which you can calculate with fairly basic linear algebra, a degree-4 equation over many variables often has many solutions, and so multiple rounds of a gradient descent algorithm may well arrive at different answers. Tiny changes to the input may well cause the descent to flip from one local minimum to another, significantly changing the output.The distinction between this, and algorithms that I helped work on such as quadratic funding, feels to me like a distinction between an economist's algorithm and an engineer's algorithm. An economist's algorithm, at its best, values being simple, being reasonably easy to analyze, and having clear mathematical properties that show why it's optimal (or least-bad) for the task that it's trying to solve, and ideally proves bounds on how much damage someone can do by trying to exploit it. An engineer's algorithm, on the other hand, is a result of iterative trial and error, seeing what works and what doesn't in the engineer's operational context. Engineer's algorithms are pragmatic and do the job; economist's algorithms don't go totally crazy when confronted with the unexpected.Or, as was famously said on a related topic by the esteemed internet philosopher roon (aka tszzl): Of course, I would say that the "theorycel aesthetic" side of crypto is necessary precisely to distinguish protocols that are actually trustless from janky constructions that look fine and seem to work well but under the hood require trusting a few centralized actors - or worse, actually end up being outright scams.Deep learning works when it works, but it has inevitable vulnerabilities to all kinds of adversarial machine learning attacks. Nerd traps and sky-high abstraction ladders, if done well, can be quite robust against them. And so one question I have is: could we turn Community Notes itself into something that's more like an economist algorithm?To give a view of what this would mean in practice, let's explore an algorithm I came up with a few years ago for a similar purpose: pairwise-bounded quadratic funding. The goal of pairwise-bounded quadratic funding is to plug a hole in "regular" quadratic funding, where if even two participants collude with each other, they can each contribute a very high amount of money to a fake project that sends the money back to them, and get a large subsidy that drains the entire pool. In pairwise quadratic funding, we assign each pair of participants a limited budget \(M\). The algorithm walks over all possible pairs of participants, and if the algorithm decides to add a subsidy to some project \(P\) because both participant \(A\) and participant \(B\) supported it, that subsidy comes out of the budget assigned to the pair \((A, B)\). Hence, even if \(k\) participants were to collude, the amount they could steal from the mechanism is at most \(k * (k-1) * M\).An algorithm of exactly this form is not very applicable to the Community Notes context, because each user makes very few votes: on average, any two users would have exactly zero votes in common, and so the algorithm would learn nothing about users' polarities by just looking at each pair of users separately. The goal of the machine learning model is precisely to try to "fill in" the matrix from very sparse source data that cannot be analyzed in this way directly. But the challenge of this approach is that it takes extra effort to do it in a way that does not make the result highly volatile in the face of a few bad votes.Does Community Notes actually fight polarization?One thing that we could do is analyze whether or not the Community Notes algorithm, as is, actually manages to fight polarization at all - that is, whether or not it actually does any better than a naive voting algorithm. Naive voting algorithms already fight polarization to some limited extent: a post with 200 upvotes and 100 downvotes does worse than a post that just gets the 200 upvotes. But does Community Notes do better than that?Looking at the algorithm abstractly, it's hard to tell. Why wouldn't a high-average-rating but polarizing post get a strong polarity and a high helpfulness? The idea is that polarity is supposed to "absorb" the properties of a note that cause it to get a lot of votes if those votes are conflicting, but does it actually do that?To check this, I ran my own simplified implementation for 100 rounds. The average results were:Quality averages: Group 1 (good): 0.30032841807271166 Group 2 (good but extra polarizing): 0.21698871680927437 Group 3 (neutral): 0.09443120045416832 Group 4 (bad): -0.1521160965793673In this test, "Good" notes received a rating of +2 from users in the same political tribe and +0 from users in the opposite political tribe, and "Good but extra polarizing" notes received a rating of +4 from same-tribe users and -2 from opposite-tribe users. Same average, but different polarity. And it seems to actually be the case that "Good" notes get a higher average helpfulness than "Good but extra polarizing" notes.One other benefit of having something closer to an "economist's algorithm" would be having a clearer story for how the algorithm is penalizing polarization.How useful is this all in high-stakes situations?We can see some of how this works out by looking at one specific situation. About a month ago, Ian Bremmer complained that a highly critical Community Note that was added to a tweet by a Chinese government official had been removed. The note, which is now no longer visible. Screenshot by Ian Bremmer. This is heavy stuff. It's one thing to do mechanism design in a nice sandbox Ethereum community environment where the largest complaint is $20,000 going to a polarizing Twitter influencer. It's another to do it for political and geopolitical questions that affect many millions of people and where everyone, often quite understandably, is assuming maximum bad faith. But if mechanism designers want to have a significant impact into the world, engaging with these high-stakes environments is ultimately necessary.In the case of Twitter, there is a clear reason why one might suspect centralized manipulation to be behind the Note's removal: Elon has a lot of business interests in China, and so there is a possibility that Elon forced the Community Notes team to interfere with the algorithm's outputs and delete this specific one.Fortunately, the algorithm is open source and verifiable, so we can actually look under the hood! Let's do that. The URL of the original tweet is https://twitter.com/MFA_China/status/1676157337109946369. The number at the end, 1676157337109946369, is the tweet ID. We can search for that in the downloadable data, and identify the specific row in the spreadsheet that has the above note: Here we get the ID of the note itself, 1676391378815709184. We then search for that in the scored_notes.tsv and note_status_history.tsv files generated by running the algorithm. We get: The second column in the first output is the note's current rating. The second output shows the note's history: its current status is in the seventh column (NEEDS_MORE_RATINGS), and the first status that's not NEEDS_MORE_RATINGS that it received earlier on is in the fifth column (CURRENTLY_RATED_HELPFUL). Hence, we see that the algorithm itself first showed the note, and then removed it once its rating dropped somewhat - seemingly no centralized intervention involved.We can see this another way by looking at the votes themselves. We can scan the ratings-00000.tsv file to isolate all the ratings for this note, and see how many rated HELPFUL vs NOT_HELPFUL: But if you sort them by timestamp, and look at the first 50 votes, you see 40 HELPFUL votes and 9 NOT_HELPFUL votes. And so we see the same conclusion: the note's initial audience viewed the note more favorably then the note's later audience, and so its rating started out higher and dropped lower over time.Unfortunately, the exact story of how the note changed status is complicated to explain: it's not a simple matter of "before the rating was above 0.40, now it's below 0.40, so it got dropped". Rather, the high volume of NOT_HELPFUL replies triggered one of the outlier conditions, increasing the helpfulness score that the note needs to stay over the threshold.This is a good learning opportunity for another lesson: making a credibly neutral algorithm truly credible requires keeping it simple. If a note moves from being accepted to not being accepted, there should be a simple and legible story as to why.Of course, there is a totally different way in which this vote could have been manipulated: brigading. Someone who sees a note that they disapprove of could call upon a highly engaged community (or worse, a mass of fake accounts) to rate it NOT_HELPFUL, and it may not require that many votes to drop the note from being seen as "helpful" to being seen as "polarized". Properly minimizing the vulnerability of this algorithm to such coordinated attacks will require a lot more analysis and work. One possible improvement would be not allowing any user to vote on any note, but instead using the "For you" algorithmic feed to randomly allocate notes to raters, and only allow raters to rate those notes that they have been allocated to.Is Community Notes not "brave" enough?The main criticism of Community Notes that I have seen is basically that it does not do enough. Two recent articles that I have seen make this point. Quoting one:The program is severely hampered by the fact that for a Community Note to be public, it has to be generally accepted by a consensus of people from all across the political spectrum."It has to have ideological consensus," he said. "That means people on the left and people on the right have to agree that that note must be appended to that tweet."Essentially, it requires a "cross-ideological agreement on truth, and in an increasingly partisan environment, achieving that consensus is almost impossible, he said.This is a difficult issue, but ultimately I come down on the side that it is better to let ten misinformative tweets go free than it is to have one tweet covered by a note that judges it unfairly. We have seen years of fact-checking that is brave, and does come from the perspective of "well, actually we know the truth, and we know that one side lies much more often than the other". And what happened as a result? Honestly, some pretty widespread distrust of fact-checking as a concept. One strategy here is to say: ignore the haters, remember that the fact checking experts really do know the facts better than any voting system, and stay the course. But going all-in on this approach seems risky. There is value in building cross-tribal institutions that are at least somewhat respected by everyone. As with William Blackstone's dictum and the courts, it feels to me that maintaining such respect requires a system that commits far more sins of omission than it does sins of commission. And so it seems valuable to me that there is at least one major organization that is taking this alternate path, and treating its rare cross-tribal respect as a resource to be cherished and built upon.Another reason why I think it is okay for Community Notes to be conservative is that I do not think it is the goal for every misinformative tweet, or even most misinformative tweets, to receive a corrective note. Even if less than one percent of misinformative tweets get a note providing context or correcting them, Community Notes is still providing an exceedingly valuable service as an educational tool. The goal is not to correct everything; rather, the goal is to remind people that multiple perspectives exist, that certain kinds of posts that look convincing and engaging in isolation are actually quite incorrect, and you, yes you, can often go do a basic internet search to verify that it's incorrect.Community Notes cannot be, and is not meant to be, a miracle cure that solves all problems in public epistemology. Whatever problems it does not solve, there is plenty of room for other mechanisms, whether newfangled gadgets such as prediction markets or good old-fashioned organizations hiring full-time staff with domain expertise, to try to fill in the gaps.ConclusionsCommunity Notes, in addition to being a fascinating social media experiment, is also an instance of a fascinating new and emerging genre of mechanism design: mechanisms that intentionally try to identify polarization, and favor things that bridge across divides rather than perpetuate them.The two other things in this category that I know about are (i) pairwise quadratic funding, which is being used in Gitcoin Grants and (ii) Polis, a discussion tool that uses clustering algorithms to help communities identify statements that are commonly well-received across people who normally have different viewpoints. This area of mechanism design is valuable, and I hope that we can see a lot more academic work in this field.Algorithmic transparency of the type that Community Notes offers is not quite full-on decentralized social media - if you disagree with how Community Notes works, there's no way to go see a view of the same content with a different algorithm. But it's the closest that very-large-scale applications are going to get within the next couple of years, and we can see that it provides a lot of value already, both by preventing centralized manipulation and by ensuring that platforms that do not engage in such manipulation can get proper credit for doing so.I look forward to seeing both Community Notes, and hopefully many more algorithms of a similar spirit, develop and grow over the next decade.
-
What do I think about biometric proof of personhood? What do I think about biometric proof of personhood?2023 Jul 24 See all posts What do I think about biometric proof of personhood? Special thanks to the Worldcoin team, the Proof of Humanity community and Andrew Miller for discussion.One of the trickier, but potentially one of the most valuable, gadgets that people in the Ethereum community have been trying to build is a decentralized proof-of-personhood solution. Proof of personhood, aka the "unique-human problem", is a limited form of real-world identity that asserts that a given registered account is controlled by a real person (and a different real person from every other registered account), ideally without revealing which real person it is.There have been a few efforts at tackling this problem: Proof of Humanity, BrightID, Idena and Circles come up as examples. Some of them come with their own applications (often a UBI token), and some have found use in Gitcoin Passport to verify which accounts are valid for quadratic voting. Zero-knowledge tech like Sismo adds privacy to many of these solutions. More recently, we have seen the rise of a much larger and more ambitious proof-of-personhood project: Worldcoin.Worldcoin was co-founded by Sam Altman, who is best known for being the CEO of OpenAI. The philosophy behind the project is simple: AI is going to create a lot of abundance and wealth for humanity, but it also may kill very many people's jobs and make it almost impossible to tell who even is a human and not a bot, and so we need to plug that hole by (i) creating a really good proof-of-personhood system so that humans can prove that they actually are humans, and (ii) giving everyone a UBI. Worldcoin is unique in that it relies on highly sophisticated biometrics, scanning each user's iris using a piece of specialized hardware called "the Orb": The goal is to produce a large number of these Orbs and widely distribute them around the world and put them in public places to make it easy for anyone to get an ID. To Worldcoin's credit, they have also committed to decentralize over time. At first, this means technical decentralization: being an L2 on Ethereum using the Optimism stack, and protecting users' privacy with ZK-SNARKs and other cryptographic techniques. Later on, it includes decentralizing governance of the system itself.Worldcoin has been criticized for privacy and security concerns around the Orb, design issues in its "coin", and for ethical issues around some choices that the company has made. Some of the criticisms are highly specific, focusing on decisions made by the project that could easily have been made in another way - and indeed, that the Worldcoin project itself may be willing to change. Others, however, raise the more fundamental concern of whether or not biometrics - not just the eye-scanning biometrics of Worldcoin, but also the simpler face-video-uploads and verification games used in Proof of Humanity and Idena - are a good idea at all. And still others criticize proof of personhood in general. Risks include unavoidable privacy leaks, further erosion of people's ability to navigate the internet anonymously, coercion by authoritarian governments, and the potential impossibility of being secure at the same time as being decentralized. This post will talk about these issues, and go through some arguments that can help you decide whether or not bowing down and scanning your eyes (or face, or voice, or...) before our new spherical overlords is a good idea, and whether or not the natural alternatives - either using social-graph-based proof of personhood or giving up on proof of personhood entirely - are any better.What is proof of personhood and why is it important?The simplest way to define a proof-of-personhood system is: it creates a list of public keys where the system guarantees that each key is controlled by a unique human. In other words, if you're a human, you can put one key on the list, but you can't put two keys on the list, and if you're a bot you can't put any keys on the list.Proof of personhood is valuable because it solves a lot of anti-spam and anti-concentration-of-power problems that many people have, in a way that avoids dependence on centralized authorities and reveals the minimal information possible. If proof of personhood is not solved, decentralized governance (including "micro-governance" like votes on social media posts) becomes much easier to capture by very wealthy actors, including hostile governments. Many services would only be able to prevent denial-of-service attacks by setting a price for access, and sometimes a price high enough to keep out attackers is also too high for many lower-income legitimate users.Many major applications in the world today deal with this issue by using government-backed identity systems such as credit cards and passports. This solves the problem, but it makes large and perhaps unacceptable sacrifices on privacy, and can be trivially attacked by governments themselves. How many proof of personhood proponents see the two-sided risk that we are facing. Image source. In many proof-of-personhood projects - not just Worldcoin, but also Proof of Humanity, Circles and others - the "flagship application" is a built-in "N-per-person token" (sometimes called a "UBI token"). Each user registered in the system receives some fixed quantity of tokens each day (or hour, or week). But there are plenty of other applications:Airdrops for token distributions Token or NFT sales that give more favorable terms to less-wealthy users Voting in DAOs A way to "seed" graph-based reputation systems Quadratic voting (and funding, and attention payments) Protection against bots / sybil attacks in social media An alternative to captchas for preventing DoS attacks In many of these cases, the common thread is a desire to create mechanisms that are open and democratic, avoiding both centralized control by a project's operators and domination by its wealthiest users. The latter is especially important in decentralized governance. In many of these cases, existing solutions today rely on some combination of (i) highly opaque AI algorithms that leave lots of room to undetectably discriminate against users that the operators simply do not like, and (ii) centralized IDs, aka "KYC". An effective proof-of-personhood solution would be a much better alternative, achieving the security properties that those applications need without the pitfalls of the existing centralized approaches.What are some early attempts at proof of personhood?There are two main forms of proof of personhood: social-graph-based and biometric. Social-graph based proof of personhood relies on some form of vouching: if Alice, Bob, Charlie and David are all verified humans, and they all say that Emily is a verified human, then Emily is probably also a verified human. Vouching is often enhanced with incentives: if Alice says that Emily is a human, but it turns out that she is not, then Alice and Emily may both get penalized. Biometric proof of personhood involves verifying some physical or behavioral trait of Emily, that distinguishes humans from bots (and individual humans from each other). Most projects use a combination of the two techniques.The four systems I mentioned at the beginning of the post work roughly as follows:Proof of Humanity: you upload a video of yourself, and provide a deposit. To be approved, an existing user needs to vouch for you, and an amount of time needs to pass during which you can be challenged. If there is a challenge, a Kleros decentralized court determines whether or not your video was genuine; if it is not, you lose your deposit and the challenger gets a reward. BrightID: you join a video call "verification party" with other users, where everyone verifies each other. Higher levels of verification are available via Bitu, a system in which you can get verified if enough other Bitu-verified users vouch for you. Idena: you play a captcha game at a specific point in time (to prevent people from participating multiple times); part of the captcha game involves creating and verifying captchas that will then be used to verify others. Circles: an existing Circles user vouches for you. Circles is unique in that it does not attempt to create a "globally verifiable ID"; rather, it creates a graph of trust relationships, where someone's trustworthiness can only be verified from the perspective of your own position in that graph. How does Worldcoin work?Each Worldcoin user installs an app on their phone, which generates a private and public key, much like an Ethereum wallet. They then go in-person to visit an "Orb". The user stares into the Orb's camera, and at the same time shows the Orb a QR code generated by their Worldcoin app, which contains their public key. The Orb scans the user's eyes, and uses complicated hardware scanning and machine-learned classifiers to verify that:The user is a real human The user's iris does not match the iris of any other user that has previously used the system If both scans pass, the Orb signs a message approving a specialized hash of the user's iris scan. The hash gets uploaded to a database - currently a centralized server, intended to be replaced with a decentralized on-chain system once they are sure the hashing mechanism works. The system does not store full iris scans; it only stores hashes, and these hashes are used to check for uniqueness. From that point forward, the user has a "World ID".A World ID holder is able to prove that they are a unique human by generating a ZK-SNARK proving that they hold the private key corresponding to a public key in the database, without revealing which key they hold. Hence, even if someone re-scans your iris, they will not be able to see any actions that you have taken.What are the major issues with Worldcoin's construction?There are four major risks that immediately come to mind:Privacy. The registry of iris scans may reveal information. At the very least, if someone else scans your iris, they can check it against the database to determine whether or not you have a World ID. Potentially, iris scans might reveal more information. Accessibility. World IDs are not going to be reliably accessible unless there are so many Orbs that anyone in the world can easily get to one. Centralization. The Orb is a hardware device, and we have no way to verify that it was constructed correctly and does not have backdoors. Hence, even if the software layer is perfect and fully decentralized, the Worldcoin Foundation still has the ability to insert a backdoor into the system, letting it create arbitrarily many fake human identities. Security. Users' phones could be hacked, users could be coerced into scanning their irises while showing a public key that belongs to someone else, and there is the possibility of 3D-printing "fake people" that can pass the iris scan and get World IDs. It's important to distinguish between (i) issues specific to choices made by Worldcoin, (ii) issues that any biometric proof of personhood will inevitably have, and (iii) issues that any proof of personhood in general will have. For example, signing up to Proof of Humanity means publishing your face on the internet. Joining a BrightID verification party doesn't quite do that, but still exposes who you are to a lot of people. And joining Circles publicly exposes your social graph. Worldcoin is significantly better at preserving privacy than either of those. On the other hand, Worldcoin depends on specialized hardware, which opens up the challenge of trusting the orb manufacturers to have constructed the orbs correctly - a challenge which has no parallels in Proof of Humanity, BrightID or Circles. It's even conceivable that in the future, someone other than Worldcoin will create a different specialized-hardware solution that has different tradeoffs.How do biometric proof-of-personhood schemes address privacy issues?The most obvious, and greatest, potential privacy leak that any proof-of-personhood system has is linking each action that a person takes to a real-world identity. This data leak is very large, arguably unacceptably large, but fortunately it is easy to solve with zero knowledge proof technology. Instead of directly making a signature with a private key whose corresponding public key is in the database, a user could make a ZK-SNARK proving that they own the private key whose corresponding public key is somewhere in the database, without revealing which specific key they have. This can be done generically with tools like Sismo (see here for the Proof of Humanity-specific implementation), and Worldcoin has its own built-in implementation. It's important to give "crypto-native" proof of personhood credit here: they actually care about taking this basic step to provide anonymization, whereas basically all centralized identity solutions do not.A more subtle, but still important, privacy leak is the mere existence of a public registry of biometric scans. In the case of Proof of Humanity, this is a lot of data: you get a video of each Proof of Humanity participant, making it very clear to anyone in the world who cares to investigate who all the Proof of Humanity participants are. In the case of Worldcoin, the leak is much more limited: the Orb locally computes and publishes only a "hash" of each person's iris scan. This hash is not a regular hash like SHA256; rather, it is a specialized algorithm based on machine-learned Gabor filters that deals with the inexactness inherent in any biometric scan, and ensures that successive hashes taken of the same person's iris have similar outputs. Blue: percent of bits that differ between two scans of the same person's iris. Orange: percent of bits that differ between two scans of two different people's irises. These iris hashes leak only a small amount of data. If an adversary can forcibly (or secretly) scan your iris, then they can compute your iris hash themselves, and check it against the database of iris hashes to see whether or not you participated in the system. This ability to check whether or not someone signed up is necessary for the system itself to prevent people from signing up multiple times, but there's always the possibility that it will somehow be abused. Additionally, there is the possibility that the iris hashes leak some amount of medical data (sex, ethnicity, perhaps medical conditions), but this leak is far smaller than what could be captured by pretty much any other mass data-gathering system in use today (eg. even street cameras). On the whole, to me the privacy of storing iris hashes seems sufficient.If others disagree with this judgement and decide that they want to design a system with even more privacy, there are two ways to do so:If the iris hashing algorithm can be improved to make the difference between two scans of the same person much lower (eg. reliably under 10% bit flips), then instead of storing full iris hashes, the system can store a smaller number of error correction bits for iris hashes (see: fuzzy extractors). If the difference between two scans is under 10%, then the number of bits that needs to be published would be at least 5x less. If we want to go further, we could store the iris hash database inside a multi-party computation (MPC) system which could only be accessed by Orbs (with a rate limit), making the data unaccessible entirely, but at the cost of significant protocol complexity and social complexity in governing the set of MPC participants. This would have the benefit that users would not be able to prove a link between two different World IDs that they had at different times even if they wanted to. Unfortunately, these techniques are not applicable to Proof of Humanity, because Proof of Humanity requires the full video of each participant to be publicly available so that it can be challenged if there are signs that it is fake (including AI-generated fakes), and in such cases investigated in more detail.On the whole, despite the "dystopian vibez" of staring into an Orb and letting it scan deeply into your eyeballs, it does seem like specialized hardware systems can do quite a decent job of protecting privacy. However, the flip side of this is that specialized hardware systems introduce much greater centralization concerns. Hence, we cypherpunks seem to be stuck in a bind: we have to trade off one deeply-held cypherpunk value against another.What are the accessibility issues in biometric proof-of-personhood systems?Specialized hardware introduces accessibility concerns because, well, specialized hardware is not very accessible. Somewhere between 51% and 64% of sub-Saharan Africans now have smartphones, and this seems to be projected to increase to 87% by 2030. But while there are billions of smartphones, there are only a few hundred Orbs. Even with much higher-scale distributed manufacturing, it would be hard to get to a world where there's an Orb within five kilometers of everyone. But to the team's credit, they have been trying! It is also worth noting that many other forms of proof of personhood have accessibility problems that are even worse. It is very difficult to join a social-graph-based proof-of-personhood system unless you already know someone who is in the social graph. This makes it very easy for such systems to remain restricted to a single community in a single country.Even centralized identity systems have learned this lesson: India's Aadhaar ID system is biometric-based, as that was the only way to quickly onboard its massive population while avoiding massive fraud from duplicate and fake accounts (resulting in huge cost savings), though of course the Aadhaar system as a whole is far weaker on privacy than anything being proposed on a large scale within the crypto community.The best-performing systems from an accessibility perspective are actually systems like Proof of Humanity, which you can sign up to using only a smartphone - though, as we have seen and as we will see, such systems come with all kinds of other tradeoffs.What are the centralization issues in biometric proof-of-personhood systems?There are three:Centralization risks in the system's top-level governance (esp. the system that makes final top-level resolutions if different actors in the system disagree on subjective judgements). Centralization risks unique to systems that use specialized hardware. Centralization risks if proprietary algorithms are used to determine who is an authentic participant. Any proof-of-personhood system must contend with (1), perhaps with the exception of systems where the set of "accepted" IDs is completely subjective. If a system uses incentives denominated in outside assets (eg. ETH, USDC, DAI), then it cannot be fully subjective, and so governance risks become unavoidable.[2] is a much bigger risk for Worldcoin than for Proof of Humanity (or BrightID), because Worldcoin depends on specialized hardware and other systems do not.[3] is a risk particularly in "logically centralized" systems where there is a single system doing the verification, unless all of the algorithms are open-source and we have an assurance that they are actually running the code that they claim they are. For systems that rely purely on users verifying other users (like Proof of Humanity), it is not a risk.How does Worldcoin address hardware centralization issues?Currently, a Worldcoin-affiliated entity called Tools for Humanity is the only organization that is making Orbs. However, the Orb's source code is mostly public: you can see the hardware specs in this github repository, and other parts of the source code are expected to be published soon. The license is another one of those "shared source but not technically open source until four years from now" licenses similar to the Uniswap BSL, except in addition to preventing forking it also prevents what they consider unethical behavior - they specifically list mass surveillance and three international civil rights declarations.The team's stated goal is to allow and encourage other organizations to create Orbs, and over time transition from Orbs being created by Tools for Humanity to having some kind of DAO that approves and manages which organizations can make Orbs that are recognized by the system.There are two ways in which this design can fail:It fails to actually decentralize. This could happen because of the common trap of federated protocols: one manufacturer ends up dominating in practice, causing the system to re-centralize. Presumably, governance could limit how many valid Orbs each manufacturer can produce, but this would need to be managed carefully, and it puts a lot of pressure on governance to be both decentralized and monitor the ecosystem and respond to threats effectively: a much harder task than eg. a fairly static DAO that just handles top-level dispute resolution tasks. It turns out that it's not possible to make such a distributed manufacturing mechanism secure. Here, there are two risks that I see: Fragility against bad Orb manufacturers: if even one Orb manufacturer is malicious or hacked, it can generate an unlimited number of fake iris scan hashes, and give them World IDs. Government restriction of Orbs: governments that do not want their citizens participating in the Worldcoin ecosystem can ban Orbs from their country. Furthermore, they could even force their citizens to get their irises scanned, allowing the government to get their accounts, and the citizens would have no way to respond. To make the system more robust against bad Orb manufacturers, the Worldcoin team is proposing to perform regular audits on Orbs, verifying that they are built correctly and key hardware components were built according to specs and were not tampered with after the fact. This is a challenging task: it's basically something like the IAEA nuclear inspections bureaucracy but for Orbs. The hope is that even a very imperfect implementation of an auditing regime could greatly cut down on the number of fake Orbs.To limit the harm caused by any bad Orb that does slip through, it makes sense to have a second mitigation. World IDs registered with different Orb manufacturers, and ideally with different Orbs, should be distinguishable from each other. It's okay if this information is private and only stored on the World ID holder's device; but it does need to be provable on demand. This makes it possible for the ecosystem to respond to (inevitable) attacks by removing individual Orb manufacturers, and perhaps even individual Orbs, from the whitelist on-demand. If we see the North Korea government going around and forcing people to scan their eyeballs, those Orbs and any accounts produced by them could be immediately retroactively disabled.Security issues in proof of personhood in generalIn addition to issues specific to Worldcoin, there are concerns that affect proof-of-personhood designs in general. The major ones that I can think of are:3D-printed fake people: one could use AI to generate photographs or even 3D prints of fake people that are convincing enough to get accepted by the Orb software. If even one group does this, they can generate an unlimited number of identities. Possibility of selling IDs: someone can provide someone else's public key instead of their own when registering, giving that person control of their registered ID, in exchange for money. This seems to be happening already. In addition to selling, there's also the possibility of renting IDs to use for a short time in one application. Phone hacking: if a person's phone gets hacked, the hacker can steal the key that controls their World ID. Government coercion to steal IDs: a government could force their citizens to get verified while showing a QR code belonging to the government. In this way, a malicious government could gain access to millions of IDs. In a biometric system, this could even be done covertly: governments could use obfuscated Orbs to extract World IDs from everyone entering their country at the passport control booth. [1] is specific to biometric proof-of-personhood systems. [2] and [3] are common to both biometric and non-biometric designs. [4] is also common to both, though the techniques that are required would be quite different in both cases; in this section I will focus on the issues in the biometric case.These are pretty serious weaknesses. Some already have been addressed in existing protocols, others can be addressed with future improvements, and still others seem to be fundamental limitations.How can we deal with fake people?This is significantly less of a risk for Worldcoin than it is for Proof of Humanity-like systems: an in-person scan can examine many features of a person, and is quite hard to fake, compared to merely deep-faking a video. Specialized hardware is inherently harder to fool than commodity hardware, which is in turn harder to fool than digital algorithms verifying pictures and videos that are sent remotely.Could someone 3D-print something that can fool even specialized hardware eventually? Probably. I expect that at some point we will see growing tensions between the goal of keeping the mechanism open and keeping it secure: open-source AI algorithms are inherently more vulnerable to adversarial machine learning. Black-box algorithms are more protected, but it's hard to tell that a black-box algorithm was not trained to include backdoors. Perhaps ZK-ML technologies could give us the best of both worlds. Though at some point in the even further future, it is likely that even the best AI algorithms will be fooled by the best 3D-printed fake people.However, from my discussions with both the Worldcoin and Proof of Humanity teams, it seems like at the present moment neither protocol is yet seeing significant deep fake attacks, for the simple reason that hiring real low-wage workers to sign up on your behalf is quite cheap and easy.Can we prevent selling IDs?In the short term, preventing this kind of outsourcing is difficult, because most people in the world are not even aware of proof-of-personhood protocols, and if you tell them to hold up a QR code and scan their eyes for $30 they will do that. Once more people are aware of what proof-of-personhood protocols are, a fairly simple mitigation becomes possible: allowing people who have a registered ID to re-register, canceling the previous ID. This makes "ID selling" much less credible, because someone who sells you their ID can just go and re-register, canceling the ID that they just sold. However, getting to this point requires the protocol to be very widely known, and Orbs to be very widely accessible to make on-demand registration practical.This is one of the reasons why having a UBI coin integrated into a proof-of-personhood system is valuable: a UBI coin provides an easily understandable incentive for people to (i) learn about the protocol and sign up, and (ii) immediately re-register if they register on behalf of someone else. Re-registration also prevents phone hacking.Can we prevent coercion in biometric proof-of-personhood systems?This depends on what kind of coercion we are talking about. Possible forms of coercion include:Governments scanning people's eyes (or faces, or...) at border control and other routine government checkpoints, and using this to register (and frequently re-register) their citizens Governments banning Orbs within the country to prevent people from independently re-registering Individuals buying IDs and then threatening to harm the seller if they detect that the ID has been invalidated due to re-registration (Possibly government-run) applications requiring people to "sign in" by signing with their public key directly, letting them see the corresponding biometric scan, and hence the link between the user's current ID and any future IDs they get from re-registering. A common fear is that this makes it too easy to create "permanent records" that stick with a person for their entire life. All your UBI and voting power are belong to us. Image source. Especially in the hands of unsophisticated users, it seems quite tough to outright prevent these situations. Users could leave their country to (re-)register at an Orb in a safer country, but this is a difficult process and high cost. In a truly hostile legal environment, seeking out an independent Orb seems too difficult and risky.What is feasible is making this kind of abuse more annoying to implement and detectable. The Proof of Humanity approach of requiring a person to speak a specific phrase when registering is a good example: it may be enough to prevent hidden scanning, requiring coercion to be much more blatant, and the registration phrase could even include a statement confirming that the respondent knows that they have the right to re-register independently and may get UBI coin or other rewards. If coercion is detected, the devices used to perform coercive registrations en masse could have their access rights revoked. To prevent applications linking people's current and previous IDs and attempting to leave "permanent records", the default proof of personhood app could lock the user's key in trusted hardware, preventing any application from using the key directly without the anonymizing ZK-SNARK layer in between. If a government or application developer wants to get around this, they would need to mandate the use of their own custom app.With a combination of these techniques and active vigilance, locking out those regimes that are truly hostile, and keeping honest those regimes that are merely medium-bad (as much of the world is), seems possible. This can be done either by a project like Worldcoin or Proof of Humanity maintaining its own bureaucracy for this task, or by revealing more information about how an ID was registered (eg. in Worldcoin, which Orb it came from), and leaving this classification task to the community.Can we prevent renting IDs (eg. to sell votes)?Renting out your ID is not prevented by re-registration. This is okay in some applications: the cost of renting out your right to collect the day's share of UBI coin is going to be just the value of the day's share of UBI coin. But in applications such as voting, easy vote selling is a huge problem.Systems like MACI can prevent you from credibly selling your vote, by allowing you to later cast another vote that invalidates your previous vote, in such a way that no one can tell whether or not you in fact cast such a vote. However, if the briber controls which key you get at registration time, this does not help.I see two solutions here:Run entire applications inside an MPC. This would also cover the re-registration process: when a person registers to the MPC, the MPC assigns them an ID that is separate from, and not linkable to, their proof of personhood ID, and when a person re-registers, only the MPC would know which account to deactivate. This prevents users from making proofs about their actions, because every important step is done inside an MPC using private information that is only known to the MPC. Decentralized registration ceremonies. Basically, implement something like this in-person key-registration protocol that requires four randomly selected local participants to work together to register someone. This could ensure that registration is a "trusted" procedure that an attacker cannot snoop in during. Social-graph-based systems may actually perform better here, because they can create local decentralized registration processes automatically as a byproduct of how they work.How do biometrics compare with the other leading candidate for proof of personhood, social graph-based verification?Aside from biometric approaches, the main other contender for proof of personhood so far has been social-graph-based verification. Social-graph-based verification systems all operate on the same principle: if there are a whole bunch of existing verified identities that all attest to the validity of your identity, then you probably are valid and should also get verified status. If only a few real users (accidentally or maliciously) verify fake users, then you can use basic graph-theory techniques to put an upper bound on how many fake users get verified by the system. Source: https://www.sciencedirect.com/science/article/abs/pii/S0045790622000611. Proponents of social-graph-based verification often describe it as being a better alternative to biometrics for a few reasons:It does not rely on special-purpose hardware, making it much easier to deploy It avoids a permanent arms race between manufacturers trying to create fake people and the Orb needing to be updated to reject such fake people It does not require collecting biometric data, making it more privacy-friendly It is potentially more friendly to pseudonymity, because if someone chooses to split their internet life across multiple identities that they keep separate from each other, both of those identities could potentially be verified (but maintaining multiple genuine and separate identities sacrifices network effects and has a high cost, so it's not something that attackers could do easily) Biometric approaches give a binary score of "is a human" or "is not a human", which is fragile: people who are accidentally rejected would end up with no UBI at all, and potentially no ability to participate in online life. Social-graph-based approaches can give a more nuanced numerical score, which may of course be moderately unfair to some participants but is unlikely to "un-person" someone completely. My perspective on these arguments is that I largely agree with them! These are genuine advantages of social-graph-based approaches and should be taken seriously. However, it's worth also taking into account the weaknesses of social-graph-based approaches:Bootstrapping: for a user to join a social-graph-based system, that user must know someone who is already in the graph. This makes large-scale adoption difficult, and risks excluding entire regions of the world that do not get lucky in the initial bootstrapping process. Privacy: while social-graph-based approaches avoid collecting biometric data, they often end up leaking info about a person's social relationships, which may lead to even greater risks. Of course, zero-knowledge technology can mitigate this (eg. see this proposal by Barry Whitehat), but the interdependency inherent in a graph and the need to perform mathematical analyses on the graph makes it harder to achieve the same level of data-hiding that you can with biometrics. Inequality: each person can only have one biometric ID, but a wealthy and socially well-connected person could use their connections to generate many IDs. Essentially, the same flexibility that might allow a social-graph-based system to give multiple pseudonyms to someone (eg. an activist) that really needs that feature would likely also imply that more powerful and well-connected people can gain more pseudonyms than less powerful and well-connected people. Risk of collapse into centralization: most people are too lazy to spend time reporting into an internet app who is a real person and who is not. As a result, there is a risk that the system will come over time to favor "easy" ways to get inducted that depend on centralized authorities, and the "social graph" that the system users will de-facto become the social graph of which countries recognize which people as citizens - giving us centralized KYC with needless extra steps. Is proof of personhood compatible with pseudonymity in the real world?In principle, proof of personhood is compatible with all kinds of pseudonymity. Applications could be designed in such a way that someone with a single proof of personhood ID can create up to five profiles within the application, leaving room for pseudonymous accounts. One could even use quadratic formulas: N accounts for a cost of $N². But will they?A pessimist, however, might argue that it is naive to try to create a more privacy-friendly form of ID and hope that it will actually get adopted in the right way, because the powers-that-be are not privacy-friendly, and if a powerful actor gets a tool that could be used to get much more information about a person, they will use it that way. In such a world, the argument goes, the only realistic approach is, unfortunately, to throw sand in the gears of any identity solution, and defend a world with full anonymity and digital islands of high-trust communities.I see the reasoning behind this way of thinking, but I worry that such an approach would, even if successful, lead to a world where there's no way for anyone to do anything to counteract wealth concentration and governance centralization, because one person could always pretend to be ten thousand. Such points of centralization would, in turn, be easy for the powers-that-be to capture. Rather, I would favor a moderate approach, where we vigorously advocate for proof-of-personhood solutions to have strong privacy, potentially if desired even include a "N accounts for $N²" mechanism at protocol layer, and create something that has privacy-friendly values and has a chance of getting accepted by the outside world.So... what do I think?There is no ideal form of proof of personhood. Instead, we have at least three different paradigms of approaches that all have their own unique strengths and weaknesses. A comparison chart might look as follows: Social-graph-based General-hardware biometric Specialized-hardware biometric Privacy Low Fairly low Fairly high Accessibility / scalability Fairly low High Medium Robustness of decentralization Fairly high Fairly high Fairly low Security against "fake people" High (if done well) Low Medium What we should ideally do is treat these three techniques as complementary, and combine them all. As India's Aadhaar has shown at scale, specialized-hardware biometrics have their benefits of being secure at scale. They are very weak at decentralization, though this can be addressed by holding individual Orbs accountable. General-purpose biometrics can be adopted very easily today, but their security is rapidly dwindling, and they may only work for another 1-2 years. Social-graph-based systems bootstrapped off of a few hundred people who are socially close to the founding team are likely to face constant tradeoffs between completely missing large parts of the world and being vulnerable to attacks within communities they have no visibility into. A social-graph-based system bootstrapped off tens of millions of biometric ID holders, however, could actually work. Biometric bootstrapping may work better short-term, and social-graph-based techniques may be more robust long-term, and take on a larger share of the responsibility over time as their algorithms improve. A possible hybrid path. All of these teams are in a position to make many mistakes, and there are inevitable tensions between business interests and the needs of the wider community, so it's important to exercise a lot of vigilance. As a community, we can and should push all participants' comfort zones on open-sourcing their tech, demand third-party audits and even third-party-written software, and other checks and balances. We also need more alternatives in each of the three categories.At the same time it's important to recognize the work already done: many of the teams running these systems have shown a willingness to take privacy much more seriously than pretty much any government or major corporate-run identity systems, and this is a success that we should build on.The problem of making a proof-of-personhood system that is effective and reliable, especially in the hands of people distant from the existing crypto community, seems quite challenging. I definitely do not envy the people attempting the task, and it will likely take years to find a formula that works. The concept of proof-of-personhood in principle seems very valuable, and while the various implementations have their risks, not having any proof-of-personhood at all has its risks too: a world with no proof-of-personhood seems more likely to be a world dominated by centralized identity solutions, money, small closed communities, or some combination of all three. I look forward to seeing more progress on all types of proof of personhood, and hopefully seeing the different approaches eventually come together into a coherent whole.
-
Deeper dive on cross-L2 reading for wallets and other use cases Deeper dive on cross-L2 reading for wallets and other use cases2023 Jun 20 See all posts Deeper dive on cross-L2 reading for wallets and other use cases Special thanks to Yoav Weiss, Dan Finlay, Martin Koppelmann, and the Arbitrum, Optimism, Polygon, Scroll and SoulWallet teams for feedback and review.In this post on the Three Transitions, I outlined some key reasons why it's valuable to start thinking explicitly about L1 + cross-L2 support, wallet security, and privacy as necessary basic features of the ecosystem stack, rather than building each of these things as addons that can be designed separately by individual wallets.This post will focus more directly on the technical aspects of one specific sub-problem: how to make it easier to read L1 from L2, L2 from L1, or an L2 from another L2. Solving this problem is crucial for implementing an asset / keystore separation architecture, but it also has valuable use cases in other areas, most notably optimizing reliable cross-L2 calls, including use cases like moving assets between L1 and L2s.Recommended pre-readsPost on the Three Transitions Ideas from the Safe team on holding assets across multiple chains Why we need wide adoption of social recovery wallets ZK-SNARKs, and some privacy applications Dankrad on KZG commitments Verkle trees Table of contentsWhat is the goal? What does a cross-chain proof look like? What kinds of proof schemes can we use? Merkle proofs ZK SNARKs Special purpose KZG proofs Verkle tree proofs Aggregation Direct state reading How does L2 learn the recent Ethereum state root? Wallets on chains that are not L2s Preserving privacy Summary What is the goal?Once L2s become more mainstream, users will have assets across multiple L2s, and possibly L1 as well. Once smart contract wallets (multisig, social recovery or otherwise) become mainstream, the keys needed to access some account are going to change over time, and old keys would need to no longer be valid. Once both of these things happen, a user will need to have a way to change the keys that have authority to access many accounts which live in many different places, without making an extremely high number of transactions.Particularly, we need a way to handle counterfactual addresses: addresses that have not yet been "registered" in any way on-chain, but which nevertheless need to receive and securely hold funds. We all depend on counterfactual addresses: when you use Ethereum for the first time, you are able to generate an ETH address that someone can use to pay you, without "registering" the address on-chain (which would require paying txfees, and hence already holding some ETH).With EOAs, all addresses start off as counterfactual addresses. With smart contract wallets, counterfactual addresses are still possible, largely thanks to CREATE2, which allows you to have an ETH address that can only be filled by a smart contract that has code matching a particular hash. EIP-1014 (CREATE2) address calculation algorithm. However, smart contract wallets introduce a new challenge: the possibility of access keys changing. The address, which is a hash of the initcode, can only contain the wallet's initial verification key. The current verification key would be stored in the wallet's storage, but that storage record does not magically propagate to other L2s.If a user has many addresses on many L2s, including addresses that (because they are counterfactual) the L2 that they are on does not know about, then it seems like there is only one way to allow users to change their keys: asset / keystore separation architecture. Each user has (i) a "keystore contract" (on L1 or on one particular L2), which stores the verification key for all wallets along with the rules for changing the key, and (ii) "wallet contracts" on L1 and many L2s, which read cross-chain to get the verification key. There are two ways to implement this:Light version (check only to update keys): each wallet stores the verification key locally, and contains a function which can be called to check a cross-chain proof of the keystore's current state, and update its locally stored verification key to match. When a wallet is used for the first time on a particular L2, calling that function to obtain the current verification key from the keystore is mandatory. Upside: uses cross-chain proofs sparingly, so it's okay if cross-chain proofs are expensive. All funds are only spendable with the current keys, so it's still secure. Downside: To change the verification key, you have to make an on-chain key change in both the keystore and in every wallet that is already initialized (though not counterfactual ones). This could cost a lot of gas. Heavy version (check for every tx): a cross-chain proof showing the key currently in the keystore is necessary for each transaction. Upside: less systemic complexity, and keystore updating is cheap. Downside: expensive per-tx, so requires much more engineering to make cross-chain proofs acceptably cheap. Also not easily compatible with ERC-4337, which currently does not support cross-contract reading of mutable objects during validation. What does a cross-chain proof look like?To show the full complexity, we'll explore the most difficult case: where the keystore is on one L2, and the wallet is on a different L2. If either the keystore or the wallet is on L1, then only half of this design is needed. Let's assume that the keystore is on Linea, and the wallet is on Kakarot. A full proof of the keys to the wallet consists of:A proof proving the current Linea state root, given the current Ethereum state root that Kakarot knows about A proof proving the current keys in the keystore, given the current Linea state root There are two primary tricky implementation questions here:What kind of proof do we use? (Is it Merkle proofs? something else?) How does the L2 learn the recent L1 (Ethereum) state root (or, as we shall see, potentially the full L1 state) in the first place? And alternatively, how does the L1 learn the L2 state root? In both cases, how long are the delays between something happening on one side, and that thing being provable to the other side? What kinds of proof schemes can we use?There are five major options:Merkle proofs General-purpose ZK-SNARKs Special-purpose proofs (eg. with KZG) Verkle proofs, which are somewhere between KZG and ZK-SNARKs on both infrastructure workload and cost. No proofs and rely on direct state reading In terms of infrastructure work required and cost for users, I rank them roughly as follows: "Aggregation" refers to the idea of aggregating all the proofs supplied by users within each block into a big meta-proof that combines all of them. This is possible for SNARKs, and for KZG, but not for Merkle branches (you can combine Merkle branches a little bit, but it only saves you log(txs per block) / log(total number of keystores), perhaps 15-30% in practice, so it's probably not worth the cost).Aggregation only becomes worth it once the scheme has a substantial number of users, so realistically it's okay for a version-1 implementation to leave aggregation out, and implement that for version 2.How would Merkle proofs work?This one is simple: follow the diagram in the previous section directly. More precisely, each "proof" (assuming the max-difficulty case of proving one L2 into another L2) would contain:A Merkle branch proving the state-root of the keystore-holding L2, given the most recent state root of Ethereum that the L2 knows about. The keystore-holding L2's state root is stored at a known storage slot of a known address (the contract on L1 representing the L2), and so the path through the tree could be hardcoded. A Merkle branch proving the current verification keys, given the state-root of the keystore-holding L2. Here once again, the verification key is stored at a known storage slot of a known address, so the path can be hardcoded. Unfortunately, Ethereum state proofs are complicated, but there exist libraries for verifying them, and if you use these libraries, this mechanism is not too complicated to implement.The larger problem is cost. Merkle proofs are long, and Patricia trees are unfortunately ~3.9x longer than necessary (precisely: an ideal Merkle proof into a tree holding N objects is 32 * log2(N) bytes long, and because Ethereum's Patricia trees have 16 leaves per child, proofs for those trees are 32 * 15 * log16(N) ~= 125 * log2(N) bytes long). In a state with roughly 250 million (~2²⁸) accounts, this makes each proof 125 * 28 = 3500 bytes, or about 56,000 gas, plus extra costs for decoding and verifying hashes.Two proofs together would end up costing around 100,000 to 150,000 gas (not including signature verification if this is used per-transaction) - significantly more than the current base 21,000 gas per transaction. But the disparity gets worse if the proof is being verified on L2. Computation inside an L2 is cheap, because computation is done off-chain and in an ecosystem with much fewer nodes than L1. Data, on the other hand, has to be posted to L1. Hence, the comparison is not 21000 gas vs 150,000 gas; it's 21,000 L2 gas vs 100,000 L1 gas.We can calculate what this means by looking at comparisons between L1 gas costs and L2 gas costs: L1 is currently about 15-25x more expensive than L2 for simple sends, and 20-50x more expensive for token swaps. Simple sends are relatively data-heavy, but swaps are much more computationally heavy. Hence, swaps are a better benchmark to approximate cost of L1 computation vs L2 computation. Taking all this into account, if we assume a 30x cost ratio between L1 computation cost and L2 computation cost, this seems to imply that putting a Merkle proof on L2 will cost the equivalent of perhaps fifty regular transactions.Of course, using a binary Merkle tree can cut costs by ~4x, but even still, the cost is in most cases going to be too high - and if we're willing to make the sacrifice of no longer being compatible with Ethereum's current hexary state tree, we might as well seek even better options.How would ZK-SNARK proofs work?Conceptually, the use of ZK-SNARKs is also easy to understand: you simply replace the Merkle proofs in the diagram above with a ZK-SNARK proving that those Merkle proofs exist. A ZK-SNARK costs ~400,000 gas of computation, and about 400 bytes (compare: 21,000 gas and 100 bytes for a basic transaction, in the future reducible to ~25 bytes with compression). Hence, from a computational perspective, a ZK-SNARK costs 19x the cost of a basic transaction today, and from a data perspective, a ZK-SNARK costs 4x as much as a basic transaction today, and 16x what a basic transaction may cost in the future.These numbers are a massive improvement over Merkle proofs, but they are still quite expensive. There are two ways to improve on this: (i) special-purpose KZG proofs, or (ii) aggregation, similar to ERC-4337 aggregation but using more fancy math. We can look into both.How would special-purpose KZG proofs work?Warning, this section is much more mathy than other sections. This is because we're going beyond general-purpose tools and building something special-purpose to be cheaper, so we have to go "under the hood" a lot more. If you don't like deep math, skip straight to the next section.First, a recap of how KZG commitments work:We can represent a set of data [D_1 ... D_n] with a KZG proof of a polynomial derived from the data: specifically, the polynomial P where P(w) = D_1, P(w²) = D_2 ... P(wⁿ) = D_n. w here is a "root of unity", a value where wᴺ = 1 for some evaluation domain size N (this is all done in a finite field). To "commit" to P, we create an elliptic curve point com(P) = P₀ * G + P₁ * S₁ + ... + Pₖ * Sₖ. Here: G is the generator point of the curve Pᵢ is the i'th-degree coefficient of the polynomial P Sᵢ is the i'th point in the trusted setup To prove P(z) = a, we create a quotient polynomial Q = (P - a) / (X - z), and create a commitment com(Q) to it. It is only possible to create such a polynomial if P(z) actually equals a. To verify a proof, we check the equation Q * (X - z) = P - a by doing an elliptic curve check on the proof com(Q) and the polynomial commitment com(P): we check e(com(Q), com(X - z)) ?= e(com(P) - com(a), com(1)) Some key properties that are important to understand are:A proof is just the com(Q) value, which is 48 bytes com(P₁) + com(P₂) = com(P₁ + P₂) This also means that you can "edit" a value into an existing a commitment. Suppose that we know that D_i is currently a, we want to set it to b, and the existing commitment to D is com(P). A commitment to "P, but with P(wⁱ) = b, and no other evaluations changed", then we set com(new_P) = com(P) + (b-a) * com(Lᵢ), where Lᵢ is a the "Lagrange polynomial" that equals 1 at wⁱ and 0 at other wʲ points. To perform these updates efficiently, all N commitments to Lagrange polynomials (com(Lᵢ)) can be pre-calculated and stored by each client. Inside a contract on-chain it may be too much to store all N commitments, so instead you could make a KZG commitment to the set of com(L_i) (or hash(com(L_i)) values, so whenever someone needs to update the tree on-chain they can simply provide the appropriate com(L_i) with a proof of its correctness. Hence, we have a structure where we can just keep adding values to the end of an ever-growing list, though with a certain size limit (realistically, hundreds of millions could be viable). We then use that as our data structure to manage (i) a commitment to the list of keys on each L2, stored on that L2 and mirrored to L1, and (ii) a commitment to the list of L2 key-commitments, stored on the Ethereum L1 and mirrored to each L2.Keeping the commitments updated could either become part of core L2 logic, or it could be implemented without L2 core-protocol changes through deposit and withdraw bridges. A full proof would thus require:The latest com(key list) on the keystore-holding L2 (48 bytes) KZG proof of com(key list) being a value inside com(mirror_list), the commitment to the list of all key list comitments (48 bytes) KZG proof of your key in com(key list) (48 bytes, plus 4 bytes for the index) It's actually possible to merge the two KZG proofs into one, so we get a total size of only 100 bytes.Note one subtlety: because the key list is a list, and not a key/value map like the state is, the key list will have to assign positions sequentially. The key commitment contract would contain its own internal registry mapping each keystore to an ID, and for each key it would store hash(key, address of the keystore) instead of just key, to unambiguously communicate to other L2s which keystore a particular entry is talking about.The upside of this technique is that it performs very well on L2. The data is 100 bytes, ~4x shorter than a ZK-SNARK and waaaay shorter than a Merkle proof. The computation cost is largely one size-2 pairing check, or about 119,000 gas. On L1, data is less important than computation, and so unfortunately KZG is somewhat more expensive than Merkle proofs.How would Verkle trees work?Verkle trees essentially involve stacking KZG commitments (or IPA commitments, which can be more efficient and use simpler cryptography) on top of each other: to store 2⁴⁸ values, you can make a KZG commitment to a list of 2²⁴ values, each of which itself is a KZG commitment to 2²⁴ values. Verkle trees are being strongly considered for the Ethereum state tree, because Verkle trees can be used to hold key-value maps and not just lists (basically, you can make a size-2²⁵⁶ tree but start it empty, only filling in specific parts of the tree once you actually need to fill them). What a Verkle tree looks like. In practice, you might give each node a width of 256 == 2⁸ for IPA-based trees, or 2²⁴ for KZG-based trees. Proofs in Verkle trees are somewhat longer than KZG; they might be a few hundred bytes long. They are also difficult to verify, especially if you try to aggregate many proofs into one.Realistically, Verkle trees should be considered to be like Merkle trees, but more viable without SNARKing (because of the lower data costs), and cheaper with SNARKing (because of lower prover costs).The largest advantage of Verkle trees is the possibility of harmonizing data structures: Verkle proofs could be used directly over L1 or L2 state, without overlay structures, and using the exact same mechanism for L1 and L2. Once quantum computers become an issue, or once proving Merkle branches becomes efficient enough, Verkle trees could be replaced in-place with a binary hash tree with a suitable SNARK-friendly hash function.AggregationIf N users make N transactions (or more realistically, N ERC-4337 UserOperations) that need to prove N cross-chain claims, we can save a lot of gas by aggregating those proofs: the builder that would be combining those transactions into a block or bundle that goes into a block can create a single proof that proves all of those claims simultaneously.This could mean:A ZK-SNARK proof of N Merkle branches A KZG multi-proof A Verkle multi-proof (or a ZK-SNARK of a multi-proof) In all three cases, the proofs would only cost a few hundred thousand gas each. The builder would need to make one of these on each L2 for the users in that L2; hence, for this to be useful to build, the scheme as a whole needs to have enough usage that there are very often at least a few transactions within the same block on multiple major L2s.If ZK-SNARKs are used, the main marginal cost is simply "business logic" of passing numbers around between contracts, so perhaps a few thousand L2 gas per user. If KZG multi-proofs are used, the prover would need to add 48 gas for each keystore-holding L2 that is used within that block, so the marginal cost of the scheme per user would add another ~800 L1 gas per L2 (not per user) on top. But these costs are much lower than the costs of not aggregating, which inevitably involve over 10,000 L1 gas and hundreds of thousands of L2 gas per user. For Verkle trees, you can either use Verkle multi-proofs directly, adding around 100-200 bytes per user, or you can make a ZK-SNARK of a Verkle multi-proof, which has similar costs to ZK-SNARKs of Merkle branches but is significantly cheaper to prove.From an implementation perspective, it's probably best to have bundlers aggregate cross-chain proofs through the ERC-4337 account abstraction standard. ERC-4337 already has a mechanism for builders to aggregate parts of UserOperations in custom ways. There is even an implementation of this for BLS signature aggregation, which could reduce gas costs on L2 by 1.5x to 3x depending on what other forms of compression are included. Diagram from a BLS wallet implementation post showing the workflow of BLS aggregate signatures within an earlier version of ERC-4337. The workflow of aggregating cross-chain proofs will likely look very similar.Direct state readingA final possibility, and one only usable for L2 reading L1 (and not L1 reading L2), is to modify L2s to let them make static calls to contracts on L1 directly.This could be done with an opcode or a precompile, which allows calls into L1 where you provide the destination address, gas and calldata, and it returns the output, though because these calls are static-calls they cannot actually change any L1 state. L2s have to be aware of L1 already to process deposits, so there is nothing fundamental stopping such a thing from being implemented; it is mainly a technical implementation challenge (see: this RFP from Optimism to support static calls into L1).Notice that if the keystore is on L1, and L2s integrate L1 static-call functionality, then no proofs are required at all! However, if L2s don't integrate L1 static-calls, or if the keystore is on L2 (which it may eventually have to be, once L1 gets too expensive for users to use even a little bit), then proofs will be required.How does L2 learn the recent Ethereum state root?All of the schemes above require the L2 to access either the recent L1 state root, or the entire recent L1 state. Fortunately, all L2s have some functionality to access the recent L1 state already. This is because they need such a functionality to process messages coming in from L1 to the L2, most notably deposits.And indeed, if an L2 has a deposit feature, then you can use that L2 as-is to move L1 state roots into a contract on the L2: simply have a contract on L1 call the BLOCKHASH opcode, and pass it to L2 as a deposit message. The full block header can be received, and its state root extracted, on the L2 side. However, it would be much better for every L2 to have an explicit way to access either the full recent L1 state, or recent L1 state roots, directly.The main challenge with optimizing how L2s receive recent L1 state roots is simultaneously achieving safety and low latency:If L2s implement "direct reading of L1" functionality in a lazy way, only reading finalized L1 state roots, then the delay will normally be 15 minutes, but in the extreme case of inactivity leaks (which you have to tolerate), the delay could be several weeks. L2s absolutely can be designed to read much more recent L1 state roots, but because L1 can revert (even with single slot finality, reverts can happen during inactivity leaks), L2 would need to be able to revert as well. This is technically challenging from a software engineering perspective, but at least Optimism already has this capability. If you use the deposit bridge to bring L1 state roots into L2, then simple economic viability might require a long time between deposit updates: if the full cost of a deposit is 100,000 gas, and we assume ETH is at $1800, and fees are at 200 gwei, and L1 roots are brought into L2 once per day, that would be a cost of $36 per L2 per day, or $13148 per L2 per year to maintain the system. With a delay of one hour, that goes up to $315,569 per L2 per year. In the best case, a constant trickle of impatient wealthy users covers the updating fees and keep the system up to date for everyone else. In the worst case, some altruistic actor would have to pay for it themselves. "Oracles" (at least, the kind of tech that some defi people call "oracles") are not an acceptable solution here: wallet key management is a very security-critical low-level functionality, and so it should depend on at most a few pieces of very simple, cryptographically trustless low-level infrastructure. Additionally, in the opposite direction (L1s reading L2):On optimistic rollups, state roots take one week to reach L1 because of the fraud proof delay. On ZK rollups it takes a few hours for now because of a combination of proving times and economic limits, though future technology will reduce this. Pre-confirmations (from sequencers, attesters, etc) are not an acceptable solution for L1 reading L2. Wallet management is a very security-critical low-level functionality, and so the level of security of the L2 -> L1 communication must be absolute: it should not even be possible to push a false L1 state root by taking over the L2 validator set. The only state roots the L1 should trust are state roots that have been accepted as final by the L2's state-root-holding contract on L1. Some of these speeds for trustless cross-chain operations are unacceptably slow for many defi use cases; for those cases, you do need faster bridges with more imperfect security models. For the use case of updating wallet keys, however, longer delays are more acceptable: you're not delaying transactions by hours, you're delaying key changes. You'll just have to keep the old keys around longer. If you're changing keys because keys are stolen, then you do have a significant period of vulnerability, but this can be mitigated, eg. by wallets having a freeze function.Ultimately, the best latency-minimizing solution is for L2s to implement direct reading of L1 state roots in an optimal way, where each L2 block (or the state root computation log) contains a pointer to the most recent L1 block, so if L1 reverts, L2 can revert as well. Keystore contracts should be placed either on mainnet, or on L2s that are ZK-rollups and so can quickly commit to L1. Blocks of the L2 chain can have dependencies on not just previous L2 blocks, but also on an L1 block. If L1 reverts past such a link, the L2 reverts too. It's worth noting that this is also how an earlier (pre-Dank) version of sharding was envisioned to work; see here for code. How much connection to Ethereum does another chain need to hold wallets whose keystores are rooted on Ethereum or an L2?Surprisingly, not that much. It actually does not even need to be a rollup: if it's an L3, or a validium, then it's okay to hold wallets there, as long as you hold keystores either on L1 or on a ZK rollup. The thing that you do need is for the chain to have direct access to Ethereum state roots, and a technical and social commitment to be willing to reorg if Ethereum reorgs, and hard fork if Ethereum hard forks.One interesting research problem is identifying to what extent it is possible for a chain to have this form of connection to multiple other chains (eg. Ethereum and Zcash). Doing it naively is possible: your chain could agree to reorg if Ethereum or Zcash reorg (and hard fork if Ethereum or Zcash hard fork), but then your node operators and your community more generally have double the technical and political dependencies. Hence such a technique could be used to connect to a few other chains, but at increasing cost. Schemes based on ZK bridges have attractive technical properties, but they have the key weakness that they are not robust to 51% attacks or hard forks. There may be more clever solutions.Preserving privacyIdeally, we also want to preserve privacy. If you have many wallets that are managed by the same keystore, then we want to make sure:It's not publicly known that those wallets are all connected to each other. Social recovery guardians don't learn what the addresses are that they are guarding. This creates a few issues:We cannot use Merkle proofs directly, because they do not preserve privacy. If we use KZG or SNARKs, then the proof needs to provide a blinded version of the verification key, without revealing the location of the verification key. If we use aggregation, then the aggregator should not learn the location in plaintext; rather, the aggregator should receive blinded proofs, and have a way to aggregate those. We can't use the "light version" (use cross-chain proofs only to update keys), because it creates a privacy leak: if many wallets get updated at the same time due to an update procedure, the timing leaks the information that those wallets are likely related. So we have to use the "heavy version" (cross-chain proofs for each transaction). With SNARKs, the solutions are conceptually easy: proofs are information-hiding by default, and the aggregator needs to produce a recursive SNARK to prove the SNARKs. The main challenge of this approach today is that aggregation requires the aggregator to create a recursive SNARK, which is currently quite slow.With KZG, we can use this work on non-index-revealing KZG proofs (see also: a more formalized version of that work in the Caulk paper) as a starting point. Aggregation of blinded proofs, however, is an open problem that requires more attention.Directly reading L1 from inside L2, unfortunately, does not preserve privacy, though implementing direct-reading functionality is still very useful, both to minimize latency and because of its utility for other applications.SummaryTo have cross-chain social recovery wallets, the most realistic workflow is a wallet that maintains a keystore in one location, and wallets in many locations, where wallet reads the keystore either (i) to update their local view of the verification key, or (ii) during the process of verifying each transaction. A key ingredient of making this possible is cross-chain proofs. We need to optimize these proofs hard. Either ZK-SNARKs, waiting for Verkle proofs, or a custom-built KZG solution, seem like the best options. In the longer term, aggregation protocols where bundlers generate aggregate proofs as part of creating a bundle of all the UserOperations that have been submitted by users will be necessary to minimize costs. This should probably be integrated into the ERC-4337 ecosystem, though changes to ERC-4337 will likely be required. L2s should be optimized to minimize the latency of reading L1 state (or at least the state root) from inside the L2. L2s directly reading L1 state is ideal and can save on proof space. Wallets can be not just on L2s; you can also put wallets on systems with lower levels of connection to Ethereum (L3s, or even separate chains that only agree to include Ethereum state roots and reorg or hard fork when Ethereum reorgs or hardforks). However, keystores should be either on L1 or on high-security ZK-rollup L2 . Being on L1 saves a lot of complexity, though in the long run even that may be too expensive, hence the need for keystores on L2. Preserving privacy will require additional work and make some options more difficult. However, we should probably move toward privacy-preserving solutions anyway, and at the least make sure that anything we propose is forward-compatible with preserving privacy.
-
The Three Transitions The Three Transitions2023 Jun 09 See all posts The Three Transitions Special thanks to Dan Finlay, Karl Floersch, David Hoffman, and the Scroll and SoulWallet teams for feedback and review and suggestions.As Ethereum transitions from a young experimental technology into a mature tech stack that is capable of actually bringing an open, global and permissionless experience to average users, there are three major technical transitions that the stack needs to undergo, roughly simultaneously:The L2 scaling transition - everyone moving to rollups The wallet security transition - everyone moving to smart contract wallets The privacy transition - making sure privacy-preserving funds transfers are available, and making sure all of the other gadgets that are being developed (social recovery, identity, reputation) are privacy-preserving The ecosystem transition triangle. You can only pick 3 out of 3. Without the first, Ethereum fails because each transaction costs $3.75 ($82.48 if we have another bull run), and every product aiming for the mass market inevitably forgets about the chain and adopts centralized workarounds for everything.Without the second, Ethereum fails because users are uncomfortable storing their funds (and non-financial assets), and everyone moves onto centralized exchanges.Without the third, Ethereum fails because having all transactions (and POAPs, etc) available publicly for literally anyone to see is far too high a privacy sacrifice for many users, and everyone moves onto centralized solutions that at least somewhat hide your data.These three transitions are crucial for the reasons above. But they are also challenging because of the intense coordination involved to properly resolve them. It's not just features of the protocol that need to improve; in some cases, the way that we interact with Ethereum needs to change pretty fundamentally, requiring deep changes from applications and wallets.The three transitions will radically reshape the relationship between users and addressesIn an L2 scaling world, users are going to exist on lots of L2s. Are you a member of ExampleDAO, which lives on Optimism? Then you have an account on Optimism! Are you holding a CDP in a stablecoin system on ZkSync? Then you have an account on ZkSync! Did you once go try some application that happened to live on Kakarot? Then you have an account on Kakarot! The days of a user having only one address will be gone. I have ETH in four places, according to my Brave Wallet view. And yes, Arbitrum and Arbitrum Nova are different. Don't worry, it will get more confusing over time! Smart contract wallets add more complexity, by making it much more difficult to have the same address across L1 and the various L2s. Today, most users are using externally owned accounts, whose address is literally a hash of the public key that is used to verify signatures - so nothing changes between L1 and L2. With smart contract wallets, however, keeping one address becomes more difficult. Although a lot of work has been done to try to make addresses be hashes of code that can be equivalent across networks, most notably CREATE2 and the ERC-2470 singleton factory, it's difficult to make this work perfectly. Some L2s (eg. "type 4 ZK-EVMs") are not quite EVM equivalent, often using Solidity or an intermediate assembly instead, preventing hash equivalence. And even when you can have hash equivalence, the possibility of wallets changing ownership through key changes creates other unintuitive consequences.Privacy requires each user to have even more addresses, and may even change what kinds of addresses we're dealing with. If stealth address proposals become widely used, instead of each user having only a few addresses, or one address per L2, users might have one address per transaction. Other privacy schemes, even existing ones such as Tornado Cash, change how assets are stored in a different way: many users' funds are stored in the same smart contract (and hence at the same address). To send funds to a specific user, users will need to rely on the privacy scheme's own internal addressing system.As we've seen, each of the three transitions weaken the "one user ~= one address" mental model in different ways, and some of these effects feed back into the complexity of executing the transitions. Two particular points of complexity are:If you want to pay someone, how will you get the information on how to pay them? If users have many assets stored in different places across different chains, how do they do key changes and social recovery? The three transitions and on-chain payments (and identity)I have coins on Scroll, and I want to pay for coffee (if the "I" is literally me, the writer of this article, then "coffee" is of course a metonymy for "green tea"). You are selling me the coffee, but you are only set up to receive coins on Taiko. Wat do?There are basically two solutions:Receiving wallets (which could be merchants, but also could just be regular individuals) try really hard to support every L2, and have some automated functionality for consolidating funds asynchronously. The recipient provides their L2 alongside their address, and the sender's wallet automatically routes funds to the destination L2 through some cross-L2 bridging system. Of course, these solutions can be combined: the recipient provides the list of L2s they're willing to accept, and the sender's wallet figures out payment, which could involve either a direct send if they're lucky, or otherwise a cross-L2 bridging path.But this is only one example of a key challenge that the three transitions introduce: simple actions like paying someone start to require a lot more information than just a 20-byte address.A transition to smart contract wallets is fortunately not a large burden on the addressing system, but there are still some technical issues in other parts of the application stack that need to be worked through. Wallets will need to be updated to make sure that they do not send only 21000 gas along with a transaction, and it will be even more important to ensure that the payment receiving side of a wallet tracks not only ETH transfers from EOAs, but also ETH sent by smart contract code. Apps that rely on the assumption that address ownership is immutable (eg. NFTs that ban smart contracts to enforce royalties) will have to find other ways of achieving their goals. Smart contract wallets will also make some things easier - notably, if someone receives only a non-ETH ERC20 token, they will be able to use ERC-4337 paymasters to pay for gas with that token.Privacy, on the other hand, once again poses major challenges that we have not really dealt with yet. The original Tornado Cash did not introduce any of these issues, because it did not support internal transfers: users could only deposit into the system and withdraw out of it. Once you can make internal transfers, however, users will need to use the internal addressing scheme of the privacy system. In practice, a user's "payment information" would need to contain both (i) some kind of "spending pubkey", a commitment to a secret that the recipient could use to spend, and (ii) some way for the sender to send encrypted information that only the recipient can decrypt, to help the recipient discover the payment.Stealth address protocols rely on a concept of meta-addresses, which work in this way: one part of the meta-address is a blinded version of the sender's spending key, and another part is the sender's encryption key (though a minimal implementation could set those two keys to be the same). Schematic overview of an abstract stealth address scheme based on encryption and ZK-SNARKs. A key lesson here is that in a privacy-friendly ecosystem, a user will have both spending pubkeys and encryption pubkeys, and a user's "payment information" will have to include both keys. There are also good reasons other than payments to expand in this direction. For example, if we want Ethereum-based encrypted email, users will need to publicly provide some kind of encryption key. In "EOA world", we could re-use account keys for this, but in a safe smart-contract-wallet world, we probably should have more explicit functionality for this. This would also help in making Ethereum-based identity more compatible with non-Ethereum decentralized privacy ecosystems, most notably PGP keys.The three transitions and key recoveryThe default way to implement key changes and social recovery in a many-address-per-user world is to simply have users run the recovery procedure on each address separately. This can be done in one click: the wallet can include software to execute the recovery procedure across all of a user's addresses at the same time. However, even with such UX simplifications, naive multi-address recovery has three issues:Gas cost impracticality: this one is self-explanatory. Counterfactual addresses: addresses for which the smart contract has not yet been published (in practice, this will mean an account that you have not yet sent funds from). You as a user have a potentially unlimited number of counterfactual addresses: one or more on every L2, including L2s that do not yet exist, and a whole other infinite set of counterfactual addresses arising from stealth address schemes. Privacy: if a user intentionally has many addresses to avoid linking them to each other, they certainly do not want to publicly link all of them by recovering them at or around the same time! Solving these problems is hard. Fortunately, there is a somewhat elegant solution that performs reasonably well: an architecture that separates verification logic and asset holdings. Each user has a keystore contract, which exists in one location (could either be mainnet or a specific L2). Users then have addresses on different L2s, where the verification logic of each of those addresses is a pointer to the keystore contract. Spending from those addresses would require a proof going into the keystore contract showing the current (or, more realistically, very recent) spending public key.The proof could be implemented in a few ways:Direct read-only L1 access inside the L2. It's possible to modify L2s to give them a way to directly read L1 state. If the keystore contract is on L1, this would mean that contracts inside L2 can access the keystore "for free" Merkle branches. Merkle branches can prove L1 state to an L2, or L2 state to an L1, or you can combine the two to prove parts of the state of one L2 to another L2. The main weakness of Merkle proofs is high gas costs due to proof length: potentially 5 kB for a proof, though this will reduce to < 1 kB in the future due to Verkle trees. ZK-SNARKs. You can reduce data costs by using a ZK-SNARK of a Merkle branch instead of the branch itself. It's possible to build off-chain aggregation techniques (eg. on top of EIP-4337) to have one single ZK-SNARK verify all cross-chain state proofs in a block. KZG commitments. Either L2s, or schemes built on top of them, could introduce a sequential addressing system, allowing proofs of state inside this system to be a mere 48 bytes long. Like with ZK-SNARKs, a multiproof scheme could merge all of these proofs into a single proof per block. If we want to avoid making one proof per transaction, we can implement a lighter scheme that only requires a cross-L2 proof for recovery. Spending from an account would depend on a spending key whose corresponding pubkey is stored within that account, but recovery would require a transaction that copies over the current spending_pubkey in the keystore. Funds in counterfactual addresses are safe even if your old keys are not: "activating" a counterfactual address to turn it into a working contract would require making a cross-L2 proof to copy over the current spending_pubkey. This thread on the Safe forums describes how a similar architecture might work.To add privacy to such a scheme, then we just encrypt the pointer, and we do all of our proving inside ZK-SNARKs:With more work (eg. using this work as a starting point), we could also strip out most of the complexity of ZK-SNARKs and make a more bare-bones KZG-based scheme.These schemes can get complex. On the plus side, there are many potential synergies between them. For example, the concept of "keystore contracts" could also be a solution to the challenge of "addresses" mentioned in the previous section: if we want users to have persistent addresses, that do not change every time the user updates a key, we could put stealth meta-addresses, encryption keys, and other information into the keystore contract, and use the address of the keystore contract as a user's "address".Lots of secondary infrastructure needs to updateUsing ENS is expensive. Today, in June 2023, the situation is not too bad: the transaction fee is significant, but it's still comparable to the ENS domain fee. Registering zuzalu.eth cost me roughly $27, of which $11 was transaction fees. But if we have another bull market, fees will skyrocket. Even without ETH price increases, gas fees returning to 200 gwei would raise the tx fee of a domain registration to $104. And so if we want people to actually use ENS, especially for use cases like decentralized social media where users demand nearly-free registration (and the ENS domain fee is not an issue because these platforms offer their users sub-domains), we need ENS to work on L2.Fortunately, the ENS team has stepped up, and ENS on L2 is actually happening! ERC-3668 (aka "the CCIP standard"), together with ENSIP-10, provide a way to have ENS subdomains on any L2 automatically be verifiable. The CCIP standard requires setting up a smart contract that describes a method for verifying proofs of data on L2, and a domain (eg. Optinames uses ecc.eth) can be put under the control of such a contract. Once the CCIP contract controls ecc.eth on L1, accessing some subdomain.ecc.eth will automatically involve finding and verifying a proof (eg. Merkle branch) of the state in L2 that actually stores that particular subdomain. Actually fetching the proofs involves going to a list of URLs stored in the contract, which admittedly feels like centralization, though I would argue it really isn't: it's a 1-of-N trust model (invalid proofs get caught by the verification logic in the CCIP contract's callback function, and as long as even one of the URLs returns a valid proof, you're good). The list of URLs could contain dozens of them.The ENS CCIP effort is a success story, and it should be viewed as a sign that radical reforms of the kind that we need are actually possible. But there's a lot more application-layer reform that will need to be done. A few examples:Lots of dapps depend on users providing off-chain signatures. With externally-owned accounts (EOAs), this is easy. ERC-1271 provides a standardized way to do this for smart contract wallets. However, lots of dapps still don't support ERC-1271; they will need to. Dapps that use "is this an EOA?" to discriminate between users and contracts (eg. to prevent transfer or enforce royalties) will break. In general, I advise against attempting to find a purely technical solution here; figuring out whether or not a particular transfer of cryptographic control is a transfer of beneficial ownership is a difficult problem and probably not solvable without resolving to some off-chain community-driven mechanisms. Most likely, applications will have to rely less on preventing transfers and more on techniques like Harberger taxes. How wallets interact with spending and encryption keys will have to be improved. Currently, wallets often use deterministic signatures to generate application-specific keys: signing a standard nonce (eg. the hash of the application's name) with an EOA's private key generates a deterministic value that cannot be generated without the private key, and so it's secure in a purely technical sense. However, these techniques are "opaque" to the wallet, preventing the wallet from implementing user-interface level security checks. In a more mature ecosystem, signing, encryption and related functionalities will have to be handled by wallets more explicitly. Light clients (eg. Helios) will have to verify L2s and not just the L1. Today, light clients focus on checking the validity of the L1 headers (using the light client sync protocol), and verifying Merkle branches of L1 state and transactions rooted in the L1 header. Tomorrow, they will also need to verify a proof of L2 state rooted in the state root stored in the L1 (a more advanced version of this would actually look at L2 pre-confirmations). Wallets will need to secure both assets and dataToday, wallets are in the business of securing assets. Everything lives on-chain, and the only thing that the wallet needs to protect is the private key that is currently guarding those assets. If you change the key, you can safely publish your previous private key on the internet the next day. In a ZK world, however, this is no longer true: the wallet is not just protecting authentication credentials, it's also holding your data.We saw the first signs of such a world with Zupass, the ZK-SNARK-based identity system that was used at Zuzalu. Users had a private key that they used to authenticate to the system, which could be used to make basic proofs like "prove I'm a Zuzalu resident, without revealing which one". But the Zupass system also began to have other apps built on top, most notably stamps (Zupass's version of POAPs). One of my many Zupass stamps, confirming that I am a proud member of Team Cat. The key feature that stamps offer over POAPs is that stamps are private: you hold the data locally, and you only ZK-prove a stamp (or some computation over the stamps) to someone if you want them to have that information about you. But this creates added risk: if you lose that information, you lose your stamps.Of course, the problem of holding data can be reduced to the problem of holding a single encryption key: some third party (or even the chain) can hold an encrypted copy of the data. This has the convenient advantage that actions you take don't change the encryption key, and so do not require any interactions with the system holding your encryption key safe. But even still, if you lose your encryption key, you lose everything. And on the flip side, if someone sees your encryption key, they see everything that was encrypted to that key.Zupass's de-facto solution was to encourage people to store their key on multiple devices (eg. laptop and phone), as the chance that they would lose access to all devices at the same time is tiny. We could go further, and use secret sharing to store the key, split between multiple guardians.This kind of social recovery via MPC is not a sufficient solution for wallets, because it means that not only current guardians but also previous guardians could collude to steal your assets, which is an unacceptably high risk. But privacy leaks are generally a lower risk than total asset loss, and someone with a high-privacy-demanding use case could always accept a higher risk of loss by not backing up the key associated with those privacy-demanding actions.To avoid overwheming the user with a byzantine system of multiple recovery paths, wallets that support social recovery will likely need to manage both recovery of assets and recovery of encryption keys.Back to identityOne of the common threads of these changes is that the concept of an "address", a cryptographic identifier that you use to represent "you" on-chain, will have to radically change. "Instructions for how to interact with me" would no longer just be an ETH address; they would have to be, in some form, some combination of multiple addresses on multiple L2s, stealth meta-addresses, encryption keys, and other data.One way to do this is to make ENS your identity: your ENS record could just contain all of this information, and if you send someone bob.eth (or bob.ecc.eth, or...), they could look up and see everything about how to pay and interact with you, including in the more complicated cross-domain and privacy-preserving ways.But this ENS-centric approach has two weaknesses:It ties too many things to your name. Your name is not you, your name is one of many attributes of you. It should be possible to change your name without moving over your entire identity profile and updating a whole bunch of records across many applications. You can't have trustless counterfactual names. One key UX feature of any blockchain is the ability to send coins to people who have not interacted with the chain yet. Without such a functionality, there is a catch-22: interacting with the chain requires paying transaction fees, which requires... already having coins. ETH addresses, including smart contract addresses with CREATE2, have this feature. ENS names don't, because if two Bobs both decide off-chain that they are bob.ecc.eth, there's no way to choose which one of them gets the name. One possible solution is to put more things into the keystore contract mentioned in the architecture earlier in this post. The keystore contract could contain all of the various information about you and how to interact with you (and with CCIP, some of that info could be off-chain), and users would use their keystore contract as their primary identifier. But the actual assets that they receive would be stored in all kinds of different places. Keystore contracts are not tied to a name, and they are counterfactual-friendly: you can generate an address that can provably only be initialized by a keystore contract that has certain fixed initial parameters.Another category of solutions has to do with abandoning the concept of user-facing addresses altogether, in a similar spirit to the Bitcoin payment protocol. One idea is to rely more heavily on direct communication channels between the sender and the recipient; for example, the sender could send a claim link (either as an explicit URL or a QR code) which the recipient could use to accept the payment however they wish. Regardless of whether the sender or the recipient acts first, greater reliance on wallets directly generating up-to-date payment information in real time could reduce friction. That said, persistent identifiers are convenient (especially with ENS), and the assumption of direct communication between sender and recipient is a really tricky one in practice, and so we may end up seeing a combination of different techniques.In all of these designs, keeping things both decentralized and understandable to users is paramount. We need to make sure that users have easy access to an up-to-date view of what their current assets are and what messages have been published that are intended for them. These views should depend on open tools, not proprietary solutions. It will take hard work to avoid the greater complexity of payment infrastructure from turning into an opaque "tower of abstraction" where developers have a hard time making sense of what's going on and adapting it to new contexts. Despite the challenges, achieving scalability, wallet security, and privacy for regular users is crucial for Ethereum's future. It is not just about technical feasibility but about actual accessibility for regular users. We need to rise to meet this challenge.
-
Don't overload Ethereum's consensus Don't overload Ethereum's consensus2023 May 21 See all posts Don't overload Ethereum's consensus Special thanks to Karl Floersch and Justin Drake for feedback and reviewThe Ethereum network's consensus is one of the most highly secured cryptoeconomic systems out there. 18 million ETH (~$34 billion) worth of validators finalize a block every 6.4 minutes, running many different implementations of the protocol for redundancy. And if the cryptoeconomic consensus fails, whether due to a bug or an intentional 51% attack, a vast community of many thousands of developers and many more users are watching carefully to make sure the chain recovers correctly. Once the chain recovers, protocol rules ensure that attackers will likely be heavily penalized.Over the years there have been a number of ideas, usually at the thought experiment stage, to also use the Ethereum validator set, and perhaps even the Ethereum social consensus, for other purposes:The ultimate oracle: a proposal where users can vote on what facts are true by sending ETH, with a SchellingCoin mechanism: everyone who sent ETH to vote for the majority answer gets a proportional share of all the ETH sent to vote for the minority answer. The description continues: "So in principle this is an symmetric game. What breaks the symmetry is that a) the truth is the natural point to coordinate on and more importantly b) the people betting on the truth can make a credible thread of forking Ethereum if they loose." Re-staking: a set of techniques, used by many protocols including EigenLayer, where Ethereum stakers can simultaneously use their stake as a deposit in another protocol. In some cases, if they misbehave according to the other protocol's rules, their deposit also gets slashed. In other cases, there are no in-protocol incentives and stake is simply used to vote. L1-driven recovery of L2 projects: it has been proposed on many occasions that if an L2 has a bug, the L1 could fork to recover it. One recent example is this design for using L1 soft forks to recover L2 failures. The purpose of this post will be to explain in detail the argument why, in my view, a certain subset of these techniques brings high systemic risks to the ecosystem and should be discouraged and resisted.These proposals are generally made in a well-intentioned way, and so the goal is not to focus on individuals or projects; rather, the goal is to focus on techniques. The general rule of thumb that this post will attempt to defend is as follows: dual-use of validator staked ETH, while it has some risks, is fundamentally fine, but attempting to "recruit" Ethereum social consensus for your application's own purposes is not.Examples of the distinction between re-using validators (low-risk) and overloading social consensus (high-risk)Alice creates a web3 social network where if you cryptographically prove that you control the key of an active Ethereum validator, you automatically gain "verified" status. Low-risk. Bob cryptographically proves that he controls the key of ten active Ethereum validators as a way of proving that he has enough wealth to satisfy some legal requirement. Low-risk. Charlie claims to have disproven the twin primes conjecture, and claims to know the largest p such that p and p+2 are both prime. He changes his staking withdrawal address to a smart contract where anyone can submit a claimed counterexample q > p, along with a SNARK proving that q and q+2 are both prime. If someone makes a valid claim, then Charlie's validator is forcibly exited, and the submitter gets whatever of Charlie's ETH is left. Low-risk. Dogecoin decides to switch to proof of stake, and to increase the size of its security pool it allows Ethereum stakers to "dual-stake" and simultaneously join its validator set. To do so, Ethereum stakers would have to change their staking withdrawal address to a smart contract where anyone can submit a proof that they violated the Dogecoin staking rules. If someone does submit such a proof, then the staker's validator is forcibly exited, and whatever of their ETH is left is used to buy-and-burn DOGE. Low-risk. eCash does the same as Dogecoin, but the project leaders further announce: if the majority of participating ETH validators collude to censor eCash transactions, they expect that the Ethereum community will hard-fork to delete those validators. They argue that it will be in Ethereum's interest to do so as those validators are proven to be malicious and unreliable. High-risk. Fred creates an ETH/USD price oracle, which functions by allowing Ethereum validators to participate and vote. There are no incentives. Low-risk. George creates an ETH/USD price oracle, which functions by allowing ETH holders to participate and vote. To protect against laziness and creeping bribes, they add an incentive mechanism where the participants that give an answer within 1% of the median answer get 1% of the ETH of any participants that gave an answer further than 1% from the median. When asked "what if someone credibly offers to bribe all the participants, everyone starts submitting the wrong answer, and so honest people get 10 million of their ETH taken away?", George replies: then Ethereum will have to fork out the bad participants' money. High-risk. George conspicuously stays away from making replies. Medium-high risk (as the project could create incentives to attempt such a fork, and hence the expectation that it will be attmpted, even without formal encouragement) George replies: "then the attacker wins, and we'll give up on using this oracle". Medium-low risk (not quite "low" only because the mechanism does create a large set of actors who in a 51% attack might be incentivized to indepently advocate for a fork to protect their deposits) Hermione creates a successful layer 2, and argues that because her layer 2 is the largest, it is inherently the most secure, because if there is a bug that causes funds to be stolen, the losses will be so large that the community will have no choice but to fork to recover the users' funds. High-risk. If you're designing a protocol where, even if everything completely breaks, the losses are kept contained to the validators and users who opted in to participating in and using your protocol, this is low-risk. If, on the other hand, you have the intent to rope in the broader Ethereum ecosystem social consensus to fork or reorg to solve your problems, this is high-risk, and I argue that we should strongly resist all attempts to create such expectations.A middle ground is situations that start off in the low-risk category but give their participants incentives to slide into the higher-risk category; SchellingCoin-style techniques, especially mechanisms with heavy penalties for deviating from the majority, are a major example.So what's so wrong with stretching Ethereum consensus, anyway?It is the year 2025. Frustrated with the existing options, a group has decided to make a new ETH/USD price oracle, which works by allowing validators to vote on the price every hour. If a validator votes, they would be unconditionally rewarded with a portion of fees from the system. But soon participants became lazy: they connected to centralized APIs, and when those APIs got cyber-attacked, they either dropped out or started reporting false values. To solve this, incentives were introduced: the oracle also votes retrospectively on the price one week ago, and if your (real time or retrospective) vote is more than 1% away from the median retrospective vote, you are heavily penalized, with the penalty going to those who voted "correctly".Within a year, over 90% of validators are participating. Someone asked: what if Lido bands together with a few other large stakers to 51% attack the vote, forcing through a fake ETH/USD price value, extracting heavy penalties from everyone who does not participate in the attack? The oracle's proponents, at this point heavily invested in the scheme, reply: well if that happens, Ethereum will surely fork to kick the bad guys out.At first, the scheme is limited to ETH/USD, and it appears resilient and stable. But over the years, other indices get added: ETH/EUR, ETH/CNY, and eventually rates for all countries in the G20.But in 2034, things start to go wrong. Brazil has an unexpectedly severe political crisis, leading to a disputed election. One political party ends up in control of the capital and 75% of the country, but another party ends up in control of some northern areas. Major Western media argue that the northern party is clearly the legitimate winner because it acted legally and the southern party acted illegally (and by the way are fascist). Indian and Chinese official sources, and Elon Musk, argue that the southern party has actual control of most of the country, and the international community should not try to be a world police and should instead accept the outcome.By this point, Brazil has a CBDC, which splits into two forks: the (northern) BRL-N, and the (southern) BRL-S. When voting in the oracle, 60% of Ethereum stakers provide the ETH/BRL-S rate. Major community leaders and businesses decry the stakers' craven capitulation to fascism, and propose to fork the chain to only include the "good stakers" providing the ETH/BRL-N rate, and drain the other stakers' balances to near-zero. Within their social media bubble, they believe that they will clearly win. However, once the fork hits, the BRL-S side proves unexpectedly strong. What they expected to be a landslide instead proves to be pretty much a 50-50 community split.At this point, the two sides are in their two separate universes with their two chains, with no practical way of coming back together. Ethereum, a global permissionless platform created in part to be a refuge from nations and geopolitics, instead ends up cleaved in half by any one of the twenty G20 member states having an unexpectedly severe internal issue.That's a nice scifi story you got there. Could even make a good movie. But what can we actually learn from it?A blockchain's "purity", in the sense of it being a purely mathematical construct that attempts to come to consensus only on purely mathematical things, is a huge advantage. As soon as a blockchain tries to "hook in" to the outside world, the outside world's conflicts start to impact on the blockchain too. Given a sufficiently extreme political event - in fact, not that extreme a political event, given that the above story was basically a pastiche of events that have actually happened in various major (>25m population) countries all within the past decade - even something as benign as a currency oracle could tear the community apart.Here are a few more possible scenarios:One of the currencies that the oracle tracks (which could even be USD) simply hyperinflates, and markets break down to the point that at some points in time there is no clear specific market price. If Ethereum adds a price oracle to another cryptocurrency, then a controversial split like in the story above is not hypothetical: it's something that has already happened, including in the histories of both Bitcoin and Ethereum itself. If strict capital controls become operational, then which price to report as the legitimate market price between two currencies becomes a political question. But more importantly, I'd argue that there is a Schelling fence at play: once a blockchain starts incorporating real-world price indices as a layer-1 protocol feature, it could easily succumb to interpreting more and more real-world information. Introducing layer-1 price indices also expands the blockchain's legal attack surface: instead of being just a neutral technical platform, it becomes much more explicitly a financial tool.What about risks from examples other than price indices?Any expansion of the "duties" of Ethereum's consensus increases the costs, complexities and risks of running a validator. Validators become required to take on the human effort of paying attention and running and updating additional software to make sure that they are acting correctly according to whatever other protocols are being introduced. Other communities gain the ability to externalize their dispute resolution needs onto the Ethereum community. Validators and the Ethereum community as a whole become forced to make far more decisions, each of which has some risk of causing a community split. Even if there is no split, the desire to avoid such pressure creates additional incentives to externalize the decisions to centralized entities through stake-pooling.The possibility of a split would also greatly strengthen perverse too-big-to-fail mechanics. There are so many layer-2 and application-layer projects on Ethereum that it would be impractical for Ethereum social consensus to be willing to fork to solve all of their problems. Hence, larger projects would inevitably get a larger chance of getting a bailout than smaller ones. This would in turn lead to larger projects getting a moat: would you rather have your coins on Arbitrum or Optimism, where if something goes wrong Ethereum will fork to save the day, or on Taiko, where because it's smaller (and non-Western, hence less socially connected to core dev circles), an L1-backed rescue is much less likely?But bugs are a risk, and we need better oracles. So what should we do?The best solutions to these problems are, in my view, case-by-case, because the various problems are inherently so different from each other. Some solutions include:Price oracles: either not-quite-cryptoeconomic decentralized oracles, or validator-voting-based oracles that explicitly commit to their emergency recovery strategies being something other than appealing to L1 consensus for recovery (or some combination of both). For example, a price oracle could count on a trust assumption that voting participants get corrupted slowly, and so users would have early warning of an attack and could exit any systems that depend on the oracle. Such an oracle could intentionally give its reward only after a long delay, so that if that instance of the protocol falls into disuse (eg. because the oracle fails and the community forks toward another version), the participants do not get the reward. More complex truth oracles reporting on facts more subjective than price: some kind of decentralized court system built on a not-quite-cryptoeconomic DAO. Layer 2 protocols: In the short term, rely on partial training wheels (what this post calls stage 1) In the medium term, rely on multiple proving systems. Trusted hardware (eg. SGX) could be included here; I strongly anti-endorse SGX-like systems as a sole guarantor of security, but as a member of a 2-of-3 system they could be valuable. In the longer term, hopefully complex functionalities such as "EVM validation" will themselves eventually be enshrined in the protocol Cross-chain bridges: similar logic as oracles, but also, try to minimize how much you rely on bridges at all: hold assets on the chain where they originate and use atomic swap protocols to move value between different chains. Using the Ethereum validator set to secure other chains: one reason why the (safer) Dogecoin approach in the list of examples above might be insufficient is that while it does protect against 51% finality-reversion attacks, it does not protect against 51% censorship attacks. However, if you are already relying on Ethereum validators, then one possible direction to take is to move away from trying to manage an independent chain entirely, and become a validium with proofs anchored into Ethereum. If a chain does this, its protection against finality-reversion attacks becomes as strong as Ethereum's, and it becomes secure against censorship up to 99% attacks (as opposed to 49%). ConclusionsBlockchain communities' social consensus is a fragile thing. It's necessary - because upgrades happen, bugs happen, and 51% attacks are always a possibility - but because it has such a high risk of causing chain splits, in mature communities it should be used sparingly. There is a natural urge to try to extend the blockchain's core with more and more functionality, because the blockchain's core has the largest economic weight and the largest community watching it, but each such extention makes the core itself more fragile.We should be wary of application-layer projects taking actions that risk increasing the "scope" of blockchain consensus to anything other than verifying the core Ethereum protocol rules. It is natural for application-layer projects to attempt such a strategy, and indeed such ideas are often simply conceived without appreciation of the risks, but its result can easily become very misaligned with the goals of the community as a whole. Such a process has no limiting principle, and could easily lead to a blockchain community having more and more "mandates" over time, pushing it into an uncomfortable choice between a high yearly risk of splitting and some kind of de-facto formalized bureaucracy that has ultimate control of the chain.We should instead preserve the chain's minimalism, support uses of re-staking that do not look like slippery slopes to extending the role of Ethereum consensus, and help developers find alternate strategies to achieve their security goals.