找到
1087
篇与
heyuan
相关的结果
-
 How do layer 2s really differ from execution sharding? How do layer 2s really differ from execution sharding?2024 May 23 See all posts How do layer 2s really differ from execution sharding? One of the points that I made in my post two and half years ago on "the Endgame" is that the different future development paths for a blockchain, at least technologically, look surprisingly similar. In both cases, you have a very large number of transactions onchain, and processing them requires (i) a large amount of computation, and (ii) a large amount of data bandwidth. Regular Ethereum nodes, such as the 2 TB reth archive node running on the laptop I'm using to write this article, are not powerful enough to verify such a huge amount of data and computation directly, even with heroic software engineering work and Verkle trees. Instead, in both "L1 sharding" and a rollup-centric world, ZK-SNARKs are used to verify computation, and DAS to verify data availability. The DAS in both cases is the same. The ZK-SNARKs in both cases are the same tech, except in one case they are smart contract code and in the other case they are an enshrined feature of the protocol. In a very real technical sense, Ethereum is doing sharding, and rollups are shards. This raises a natural question: what is the difference between these two worlds? One answer is that the consequences of code bugs are different: in a rollup world, coins get lost, and in a shard chain world, you have consensus failures. But I expect that as protocol solidify, and as formal verification technology improves, the importance of bugs will decrease. So what are the differences between the two visions that we can expect will stick into the long term?Diversity of execution environmentsOne of the ideas that we briefly played around with in Ethereum in 2019 was execution environments. Essentially, Ethereum would have different "zones" that could have different rules for how accounts work (including totally different approaches like UTXOs), how the virtual machine works, and other features. This would enable a diversity of approaches in parts of the stack where it would be difficult to achieve if Ethereum were to try to do everything by itself.In the end, we ended up abandoning some of the more ambitious plans, and simply kept the EVM. However, Ethereum L2s (including rollups, valdiums and Plasmas) arguably ended up serving the role of execution environments. Today, we generally focus on EVM-equivalent L2s, but this ignores the diversity of many alternative approaches:Arbitrum Stylus, which adds a second virtual machine based on WASM alongside the EVM. Fuel, which uses a Bitcoin-like (but more feature-complete) UTXO-based architecture. Aztec, which introduces a new language and programming paradigm designed around ZK-SNARK-based privacy-preserving smart contracts. UTXO-based architecture. Source: Fuel documentation. We could try to make the EVM into a super-VM that covers all possible paradigms, but that would have led to much less effective implementations of each of these concepts than allowing platforms like these to specialize.Security tradeoffs: scale and speedEthereum L1 provides a really strong security guarantee. If some piece of data is inside a block that is finalized on L1, the entire consensus (including, in extreme situations, social consensus) works to ensure that the data will not be edited in a way that goes against the rules of the application that put that data there, that any execution triggered by the data will not be reverted, and that the data will remain accessible. To achieve these guarantees, Ethereum L1 is willing to accept high costs. At the time of this writing, the transaction fees are relatively low: layer 2s charge less than a cent per transaction, and even the L1 is under $1 for a basic ETH transfer. These costs may remain low in the future if technology improves fast enough that available block space grows to keep up with demand - but they may not. And even $0.01 per transaction is too high for many non-financial applications, eg. social media or gaming.But social media and gaming do not require the same security model as L1. It's ok if someone can pay a million dollars to revert a record of them losing a chess game, or make one of your twitter posts look like it was published three days after it actually was. And so these applications should not have to pay for the same security costs. An L2-centric approach enables this, by supporting a spectrum of data availability approaches from rollups to plasma to validiums. Different L2 types for different use cases. Read more here. Another security tradeoff arises around the issue of passing assets from L2 to L2. In the limit (5-10 years into the future), I expect that all rollups will be ZK rollups, and hyper-efficient proof systems like Binius and Circle STARKs with lookups, plus proof aggregation layers, will make it possible for L2s to provide finalized state roots in each slot. For now, however, we have a complicated mix of optimistic rollups and ZK rollups with various proof time windows. If we had implemented execution sharding in 2021, the security model to keep shards honest would have been optimistic rollups, not ZK - and so L1 would have had to manage the systemically-complex fraud proof logic on-chain and have a week-long withdrawal period for moving assets from shard to shard. But like code bugs, I think this issue is ultimately temporary.A third, and once again more lasting, dimension of security tradeoff is transaction speed. Ethereum has blocks every 12 seconds, and is unwilling to go much faster because that would overly centralize the network. Many L2s, however, are exploring block times of a few hundred milliseconds. 12 seconds is already not that bad: on average, a user who submits a transaction needs to wait ~6-7 seconds to get included into a block (not just 6 because of the possibility that the next block will not include them). This is comparable to what I have to wait when making a payment on my credit card. But many applications demand much higher speed, and L2s provide it.To provide this higher speed, L2s rely on preconfirmation mechanisms: the L2's own validators digitally sign a promise to include the transaction at a particular time, and if the transaction does not get included, they can be penalized. A mechanism called StakeSure generalizes this further. L2 preconfirmations. Now, we could try to do all of this on layer 1. Layer 1 could incorporate a "fast pre-confirmation" and "slow final confirmation" system. It could incorporate different shards with different levels of security. However, this would add a lot of complexity to the protocol. Furthermore, doing it all on layer 1 would risk overloading the consensus, because a lot of the higher-scale or faster-throughput approaches have higher centralization risks or require stronger forms of "governance", and if done at L1, the effects of those stronger demands would spill over to the rest of the protocol. By offering these tradeoffs through layer 2s, Ethereum can mostly avoid these risks.The benefits of layer 2s on organization and cultureImagine that a country gets split in half, and one half becomes capitalist and the other becomes highly government-driven (unlike when this happens in reality, assume that in this thought experiment it's not the result of any kind of traumatic war; rather, one day a border magically goes up and that's it). In the capitalist part, the restaurants are all run by various combinations of decentralized ownership, chains and franchises. In the government-driven part, they are all branches of the government, like police stations. On the first day, not much would change. People largely follow their existing habits, and what works and what doesn't work depends on technical realities like labor skill and infrastructure. A year later, however, you would expect to see large changes, because the differing structures of incentives and control lead to large changes in behavior, which affect who comes, who stays and who goes, what gets built, what gets maintained, and what gets left to rot.Industrial organization theory covers a lot of these distinctions: it talks about the differences not just between a government-run economy and a capitalist economy, but also between an economy dominated by large franchises and an economy where eg. each supermarket is run by an independent entrepreneur. I would argue that the difference between a layer-1-centric ecosystem and a layer-2-centric ecosystem falls along similar lines. A "core devs run everything" architecture gone very wrong. I would phrase the key benefit to Ethereum of being a layer-2-centric ecosystem as follows:Because Ethereum is a layer-2-centric ecosystem, you are free to go independently build a sub-ecosystem that is yours with your unique features, and is at the same time a part of a greater Ethereum.If you're just building an Ethereum client, you're part of a greater Ethereum, and while you have some room for creativity, it's far less than what's available to L2s. And if you're building a completely independent chain, you have maximal room for creativity, but you lose the benefits like shared security and shared network effects. Layer 2s form a happy medium.Layer 2s do not just create a technical opportunity to experiment with new execution environments and security tradeoffs to achieve scale, flexibility and speed: they also create an incentive to: both for the developers to build and maintain it, and for the community to form around and support it.The fact that each L2 is isolated also means that deploying new approaches is permissionless: there's no need to convince all the core devs that your new approach is "safe" for the rest of the chain. If your L2 fails, that's on you. Anyone can work on totally weird ideas (eg. Intmax's approach to Plasma), and even if they get completely ignored by the Ethereum core devs, they can keep building and eventually deploy. L1 features and precompiles are not like this, and even in Ethereum, what succeeds and what fails in L1 development often ends up depending on politics to a higher degree than we would like. Regardless of what theoretically could get built, the distinct incentives created by an L1-centric ecosystem and an L2-centric ecosystem end up heavily influencing what does get built in practice, with what level of quality and in what order.What challenges does Ethereum's layer-2-centric ecosystem have? A layer 1 + layer 2 architecture gone very wrong. Source. There is a key challenge to this kind of layer-2-centric approach, and it's a problem that layer 1-centric ecosystems do not have to face to nearly the same extent: coordination. In other words, while Ethereum branches out, the challenge is in preserving the fundamental property that it still all feels like "Ethereum", and has the network effects of being Ethereum rather than being N separate chains. Today, the situation is suboptimal in many ways:Moving tokens from one layer 2 to another requires often centralized bridge platforms, and is complicated for the average user. If you have coins on Optimism, you can't just paste someone's Arbitrum address into your wallet, and send them funds. Cross-chain smart contract wallet support is not great - both for personal smart contract wallets and for organizational wallets (including DAOs). If you change your key on one L2, you also need to go change your key on every other L2. Decentralized validation infrastructure is often lacking. Ethereum is finally starting to have decent light clients, such as Helios. However, there is no point in this if activity is all happening on layer 2s that all require their own centralized RPCs. In principle, once you have the Ethereum header chain, making light clients for L2s is not hard; in practice, there's far too little emphasis on it. There are efforts working to improve all three. For cross-chain token exchange, the ERC-7683 standard is an emerging option, and unlike existing "centralized bridges" it does not have any enshrined central operator, token or governance. For cross-chain accounts, the approach most wallets are taking is to use cross-chain replayable messages to update keys in the short term, and keystore rollups in the longer term. Light clients for L2s are starting to emerge, eg. Beerus for Starknet. Additionally, recent improvements in user experience through next-generation wallets have already solved much more basic problems like removing the need for users to manually switch to the right network to access a dapp. Rabby showing an integrated view of asset balances across multiple chains. In the not-so-long-ago dark old days, wallets did not do this! But it is important to recognize that layer-2-centric ecosystems do swim against the current to some extent when trying to coordinate. Individual layer 2s don't have a natural economic incentive to build the infrastructure to coordinate: small ones don't, because they would only see a small share of the benefit of their contributions, and large ones don't, because they would benefit as much or more from strengthening their own local network effects. If each layer 2 is separately optimizing its individual piece, and no one is thinking about how each piece fits into the broader whole, we get failures like the urbanism dystopia in the picture a few paragraphs above.I do not claim to have magical perfect solutions to this problem. The best I can say is that the ecosystem needs to more fully recognize that cross-L2 infrastructure is a type of Ethereum infrastructure, alongside L1 clients, dev tools and programming languages, and should be valorized and funded as such. We have Protocol Guild; maybe we need Basic Infrastructure Guild.Conclusions"Layer 2s" and "sharding" often get described in public discourse as being two opposite strategies for how to scale a blockchain. But when you look at the underlying technology, there is a puzzle: the actual underlying approaches to scaling are exactly the same. You have some kind of data sharding. You have fraud provers or ZK-SNARK provers. You have solutions for cross- communication. The main difference is: who is responsible for building and updating those pieces, and how much autonomy do they have?A layer-2-centric ecosystem is sharding in a very real technical sense, but it's sharding where you can go create your own shard with your own rules. This is powerful, and enables a lot of creativity and independent innovation. But it also has key challenges, particularly around coordination. For a layer-2-centric ecosystem like Ethereum to succeed, it needs to understand those challenges, and address them head-on, in order to get as many of the benefits of layer-1-centric ecosystems as possible, and come as close as possible to having the best of both worlds.
How do layer 2s really differ from execution sharding? How do layer 2s really differ from execution sharding?2024 May 23 See all posts How do layer 2s really differ from execution sharding? One of the points that I made in my post two and half years ago on "the Endgame" is that the different future development paths for a blockchain, at least technologically, look surprisingly similar. In both cases, you have a very large number of transactions onchain, and processing them requires (i) a large amount of computation, and (ii) a large amount of data bandwidth. Regular Ethereum nodes, such as the 2 TB reth archive node running on the laptop I'm using to write this article, are not powerful enough to verify such a huge amount of data and computation directly, even with heroic software engineering work and Verkle trees. Instead, in both "L1 sharding" and a rollup-centric world, ZK-SNARKs are used to verify computation, and DAS to verify data availability. The DAS in both cases is the same. The ZK-SNARKs in both cases are the same tech, except in one case they are smart contract code and in the other case they are an enshrined feature of the protocol. In a very real technical sense, Ethereum is doing sharding, and rollups are shards. This raises a natural question: what is the difference between these two worlds? One answer is that the consequences of code bugs are different: in a rollup world, coins get lost, and in a shard chain world, you have consensus failures. But I expect that as protocol solidify, and as formal verification technology improves, the importance of bugs will decrease. So what are the differences between the two visions that we can expect will stick into the long term?Diversity of execution environmentsOne of the ideas that we briefly played around with in Ethereum in 2019 was execution environments. Essentially, Ethereum would have different "zones" that could have different rules for how accounts work (including totally different approaches like UTXOs), how the virtual machine works, and other features. This would enable a diversity of approaches in parts of the stack where it would be difficult to achieve if Ethereum were to try to do everything by itself.In the end, we ended up abandoning some of the more ambitious plans, and simply kept the EVM. However, Ethereum L2s (including rollups, valdiums and Plasmas) arguably ended up serving the role of execution environments. Today, we generally focus on EVM-equivalent L2s, but this ignores the diversity of many alternative approaches:Arbitrum Stylus, which adds a second virtual machine based on WASM alongside the EVM. Fuel, which uses a Bitcoin-like (but more feature-complete) UTXO-based architecture. Aztec, which introduces a new language and programming paradigm designed around ZK-SNARK-based privacy-preserving smart contracts. UTXO-based architecture. Source: Fuel documentation. We could try to make the EVM into a super-VM that covers all possible paradigms, but that would have led to much less effective implementations of each of these concepts than allowing platforms like these to specialize.Security tradeoffs: scale and speedEthereum L1 provides a really strong security guarantee. If some piece of data is inside a block that is finalized on L1, the entire consensus (including, in extreme situations, social consensus) works to ensure that the data will not be edited in a way that goes against the rules of the application that put that data there, that any execution triggered by the data will not be reverted, and that the data will remain accessible. To achieve these guarantees, Ethereum L1 is willing to accept high costs. At the time of this writing, the transaction fees are relatively low: layer 2s charge less than a cent per transaction, and even the L1 is under $1 for a basic ETH transfer. These costs may remain low in the future if technology improves fast enough that available block space grows to keep up with demand - but they may not. And even $0.01 per transaction is too high for many non-financial applications, eg. social media or gaming.But social media and gaming do not require the same security model as L1. It's ok if someone can pay a million dollars to revert a record of them losing a chess game, or make one of your twitter posts look like it was published three days after it actually was. And so these applications should not have to pay for the same security costs. An L2-centric approach enables this, by supporting a spectrum of data availability approaches from rollups to plasma to validiums. Different L2 types for different use cases. Read more here. Another security tradeoff arises around the issue of passing assets from L2 to L2. In the limit (5-10 years into the future), I expect that all rollups will be ZK rollups, and hyper-efficient proof systems like Binius and Circle STARKs with lookups, plus proof aggregation layers, will make it possible for L2s to provide finalized state roots in each slot. For now, however, we have a complicated mix of optimistic rollups and ZK rollups with various proof time windows. If we had implemented execution sharding in 2021, the security model to keep shards honest would have been optimistic rollups, not ZK - and so L1 would have had to manage the systemically-complex fraud proof logic on-chain and have a week-long withdrawal period for moving assets from shard to shard. But like code bugs, I think this issue is ultimately temporary.A third, and once again more lasting, dimension of security tradeoff is transaction speed. Ethereum has blocks every 12 seconds, and is unwilling to go much faster because that would overly centralize the network. Many L2s, however, are exploring block times of a few hundred milliseconds. 12 seconds is already not that bad: on average, a user who submits a transaction needs to wait ~6-7 seconds to get included into a block (not just 6 because of the possibility that the next block will not include them). This is comparable to what I have to wait when making a payment on my credit card. But many applications demand much higher speed, and L2s provide it.To provide this higher speed, L2s rely on preconfirmation mechanisms: the L2's own validators digitally sign a promise to include the transaction at a particular time, and if the transaction does not get included, they can be penalized. A mechanism called StakeSure generalizes this further. L2 preconfirmations. Now, we could try to do all of this on layer 1. Layer 1 could incorporate a "fast pre-confirmation" and "slow final confirmation" system. It could incorporate different shards with different levels of security. However, this would add a lot of complexity to the protocol. Furthermore, doing it all on layer 1 would risk overloading the consensus, because a lot of the higher-scale or faster-throughput approaches have higher centralization risks or require stronger forms of "governance", and if done at L1, the effects of those stronger demands would spill over to the rest of the protocol. By offering these tradeoffs through layer 2s, Ethereum can mostly avoid these risks.The benefits of layer 2s on organization and cultureImagine that a country gets split in half, and one half becomes capitalist and the other becomes highly government-driven (unlike when this happens in reality, assume that in this thought experiment it's not the result of any kind of traumatic war; rather, one day a border magically goes up and that's it). In the capitalist part, the restaurants are all run by various combinations of decentralized ownership, chains and franchises. In the government-driven part, they are all branches of the government, like police stations. On the first day, not much would change. People largely follow their existing habits, and what works and what doesn't work depends on technical realities like labor skill and infrastructure. A year later, however, you would expect to see large changes, because the differing structures of incentives and control lead to large changes in behavior, which affect who comes, who stays and who goes, what gets built, what gets maintained, and what gets left to rot.Industrial organization theory covers a lot of these distinctions: it talks about the differences not just between a government-run economy and a capitalist economy, but also between an economy dominated by large franchises and an economy where eg. each supermarket is run by an independent entrepreneur. I would argue that the difference between a layer-1-centric ecosystem and a layer-2-centric ecosystem falls along similar lines. A "core devs run everything" architecture gone very wrong. I would phrase the key benefit to Ethereum of being a layer-2-centric ecosystem as follows:Because Ethereum is a layer-2-centric ecosystem, you are free to go independently build a sub-ecosystem that is yours with your unique features, and is at the same time a part of a greater Ethereum.If you're just building an Ethereum client, you're part of a greater Ethereum, and while you have some room for creativity, it's far less than what's available to L2s. And if you're building a completely independent chain, you have maximal room for creativity, but you lose the benefits like shared security and shared network effects. Layer 2s form a happy medium.Layer 2s do not just create a technical opportunity to experiment with new execution environments and security tradeoffs to achieve scale, flexibility and speed: they also create an incentive to: both for the developers to build and maintain it, and for the community to form around and support it.The fact that each L2 is isolated also means that deploying new approaches is permissionless: there's no need to convince all the core devs that your new approach is "safe" for the rest of the chain. If your L2 fails, that's on you. Anyone can work on totally weird ideas (eg. Intmax's approach to Plasma), and even if they get completely ignored by the Ethereum core devs, they can keep building and eventually deploy. L1 features and precompiles are not like this, and even in Ethereum, what succeeds and what fails in L1 development often ends up depending on politics to a higher degree than we would like. Regardless of what theoretically could get built, the distinct incentives created by an L1-centric ecosystem and an L2-centric ecosystem end up heavily influencing what does get built in practice, with what level of quality and in what order.What challenges does Ethereum's layer-2-centric ecosystem have? A layer 1 + layer 2 architecture gone very wrong. Source. There is a key challenge to this kind of layer-2-centric approach, and it's a problem that layer 1-centric ecosystems do not have to face to nearly the same extent: coordination. In other words, while Ethereum branches out, the challenge is in preserving the fundamental property that it still all feels like "Ethereum", and has the network effects of being Ethereum rather than being N separate chains. Today, the situation is suboptimal in many ways:Moving tokens from one layer 2 to another requires often centralized bridge platforms, and is complicated for the average user. If you have coins on Optimism, you can't just paste someone's Arbitrum address into your wallet, and send them funds. Cross-chain smart contract wallet support is not great - both for personal smart contract wallets and for organizational wallets (including DAOs). If you change your key on one L2, you also need to go change your key on every other L2. Decentralized validation infrastructure is often lacking. Ethereum is finally starting to have decent light clients, such as Helios. However, there is no point in this if activity is all happening on layer 2s that all require their own centralized RPCs. In principle, once you have the Ethereum header chain, making light clients for L2s is not hard; in practice, there's far too little emphasis on it. There are efforts working to improve all three. For cross-chain token exchange, the ERC-7683 standard is an emerging option, and unlike existing "centralized bridges" it does not have any enshrined central operator, token or governance. For cross-chain accounts, the approach most wallets are taking is to use cross-chain replayable messages to update keys in the short term, and keystore rollups in the longer term. Light clients for L2s are starting to emerge, eg. Beerus for Starknet. Additionally, recent improvements in user experience through next-generation wallets have already solved much more basic problems like removing the need for users to manually switch to the right network to access a dapp. Rabby showing an integrated view of asset balances across multiple chains. In the not-so-long-ago dark old days, wallets did not do this! But it is important to recognize that layer-2-centric ecosystems do swim against the current to some extent when trying to coordinate. Individual layer 2s don't have a natural economic incentive to build the infrastructure to coordinate: small ones don't, because they would only see a small share of the benefit of their contributions, and large ones don't, because they would benefit as much or more from strengthening their own local network effects. If each layer 2 is separately optimizing its individual piece, and no one is thinking about how each piece fits into the broader whole, we get failures like the urbanism dystopia in the picture a few paragraphs above.I do not claim to have magical perfect solutions to this problem. The best I can say is that the ecosystem needs to more fully recognize that cross-L2 infrastructure is a type of Ethereum infrastructure, alongside L1 clients, dev tools and programming languages, and should be valorized and funded as such. We have Protocol Guild; maybe we need Basic Infrastructure Guild.Conclusions"Layer 2s" and "sharding" often get described in public discourse as being two opposite strategies for how to scale a blockchain. But when you look at the underlying technology, there is a puzzle: the actual underlying approaches to scaling are exactly the same. You have some kind of data sharding. You have fraud provers or ZK-SNARK provers. You have solutions for cross- communication. The main difference is: who is responsible for building and updating those pieces, and how much autonomy do they have?A layer-2-centric ecosystem is sharding in a very real technical sense, but it's sharding where you can go create your own shard with your own rules. This is powerful, and enables a lot of creativity and independent innovation. But it also has key challenges, particularly around coordination. For a layer-2-centric ecosystem like Ethereum to succeed, it needs to understand those challenges, and address them head-on, in order to get as many of the benefits of layer-1-centric ecosystems as possible, and come as close as possible to having the best of both worlds. -
The near and mid-term future of improving the Ethereum network's permissionlessness and decentralization The near and mid-term future of improving the Ethereum network's permissionlessness and decentralization2024 May 17 See all posts The near and mid-term future of improving the Ethereum network's permissionlessness and decentralization Special thanks to Dankrad Feist, Caspar Schwarz-Schilling and Francesco for rapid feedback and review.I am sitting here writing this on the final day of an Ethereum developer interop in Kenya, where we made a large amount of progress implementing and ironing out technical details of important upcoming Ethereum improvements, most notably PeerDAS, the Verkle tree transition and decentralized approaches to storing history in the context of EIP 4444. From my own perspective, it feels like the pace of Ethereum development, and our capacity to ship large and important features that meaningfully improve the experience for node operators and (L1 and L2) users, is increasing. Ethereum client teams working together to ship the Pectra devnet. Given this greater technical capacity, one important question to be asking is: are we building toward the right goals? One prompt for thinking about this is a recent series of unhappy tweets from the long-time Geth core developer Peter Szilagyi: These are valid concerns. They are concerns that many people in the Ethereum community have expressed. They are concerns that I have on many occasions had personally. However, I also do not think that the situation is anywhere near as hopeless as Peter's tweets imply; rather, many of the concerns are already being addressed by protocol features that are already in-progress, and many others can be addressed by very realistic tweaks to the current roadmap.In order to see what this means in practice, let us go through the three examples that Peter provided one by one. The goal is not to focus on Peter specifically; they are concerns that are widely shared among many community members, and it's important to address them.MEV, and builder dependenceIn the past, Ethereum blocks were created by miners, who used a relatively simple algorithm to create blocks. Users send transactions to a public p2p network often called the "mempool" (or "txpool"). Miners listen to the mempool, and accept transactions that are valid and pay fees. They include the transactions they can, and if there is not enough space, they prioritize by highest-fee-first.This was a very simple system, and it was friendly toward decentralization: as a miner, you can just run default software, and you can get the same levels of fee revenue from a block that you could get from highly professional mining farms. Around 2020, however, people started exploiting what was called miner extractable value (MEV): revenue that could only be gained by executing complex strategies that are aware of activities happening inside of various defi protocols.For example, consider decentralized exchanges like Uniswap. Suppose that at time T, the USD/ETH exchange rate - on centralized exchanges and on Uniswap - is $3000. At time T+11, the USD/ETH exchange rate on centralized exchanges rises to $3005. But Ethereum has not yet had its next block. At time T+12, it does. Whoever creates the block can make their first transaction be a series of Uniswap buys, buying up all of the ETH available on Uniswap at prices from $3000 to $3004. This is extra revenue, and is called MEV. Applications other than DEXes have their own analogues to this problem. The Flash Boys 2.0 paper published in 2019 goes into this in detail. A chart from the Flash Boys 2.0 paper that shows the amount of revenue capturable using the kinds of approaches described above.The problem is that this breaks the story for why mining (or, post-2022, block proposing) can be "fair": now, large actors who have better ability to optimize these kinds of extraction algorithms can get a better return per block.Since then there has been a debate between two strategies, which I will call MEV minimization and MEV quarantining. MEV minimization comes in two forms: (i) aggressively work on MEV-free alternatives to Uniswap (eg. Cowswap), and (ii) build in-protocol techniques, like encrypted mempools, that reduce the information available to block producers, and thus reduce the revenue that they can capture. In particular, encrypted mempools prevent strategies such as sandwich attacks, which put transactions right before and after users' trades in order to financially exploit them ("front-running").MEV quarantining works by accepting MEV, but trying to limit its impact on staking centralization by separating the market into two kinds of actors: validators are responsible for attesting and proposing blocks, but the task of choosing the block's contents gets outsourced to specialized builders through an auction protocol. Individual stakers now no longer need to worry about optimizing defi arbitrage themselves; they simply join the auction protocol, and accept the highest bid. This is called proposer/builder separation (PBS). This approach has precedents in other industries: a major reason why restaurants are able to remain so decentralized is that they often rely on a fairly concentrated set of providers for various operations that do have large economies of scale. So far, PBS has been reasonably successful at ensuring that small validators and large validators are on a fair playing field, at least as far as MEV is concerned. However, it creates another problem: the task of choosing which transactions get included becomes more concentrated.My view on this has always been that MEV minimization is good and we should pursue it (I personally use Cowswap regularly!) - though encrypted mempools have a lot of challenges, but MEV minimization will likely be insufficient; MEV will not go down to zero, or even near-zero. Hence, we need some kind of MEV quarantining too. This creates an interesting task: how do we make the "MEV quarantine box" as small as possible? How do we give builders the least possible power, while still keeping them capable of absorbing the role of optimizing arbitrage and other forms of MEV collecting?If builders have the power to exclude transactions from a block entirely, there are attacks that can quite easily arise. Suppose that you have a collateralized debt position (CDP) in a defi protocol, backed by an asset whose price is rapidly dropping. You want to either bump up your collateral or exit the CDP. Malicious builders could try to collude to refuse to include your transaction, delaying it until prices drop by enough that they can forcibly liquidate your CDP. If that happens, you would have to pay a large penalty, and the builders would get a large share of it. So how can we prevent builders from excluding transactions and accomplishing these kinds of attacks?This is where inclusion lists come in. Source: this ethresear.ch post. Inclusion lists allow block proposers (meaning, stakers) to choose transactions that are required to go into the block. Builders can still reorder transactions or insert their own, but they must include the proposer's transactions. Eventually, inclusion lists were modified to constrain the next block rather than the current block. In either case, they take away the builder's ability to push transactions out of the block entirely.The above was all a deep rabbit hole of complicated background. But MEV is a complicated issue; even the above description misses lots of important nuances. As the old adage goes, "you may not be looking for MEV, but MEV is looking for you". Ethereum researchers are already quite aligned on the goal of "minimizing the quarantine box", reducing the harm that builders can do (eg. by excluding or delaying transactions as a way of attacking specific applications) as much as possible.That said, I do think that we can go even further. Historically, inclusion lists have often been conceived as an "off-to-the-side special-case feature": normally, you would not think about them, but just in case malicious builders start doing crazy things, they give you a "second path". This attitude is reflected in current design decisions: in the current EIP, the gas limit of an inclusion list is around 2.1 million. But we can make a philosophical shift in how we think about inclusion lists: think of the inclusion list as being the block, and think of the builder's role as being an off-to-the-side function of adding a few transactions to collect MEV. What if it's builders that have the 2.1 million gas limit?I think ideas in this direction - really pushing the quarantine box to be as small as possible - are really interesting, and I'm in favor of going in that direction. This is a shift from "2021-era philosophy": in 2021-era philosophy, we were more enthusiastic about the idea that, since we now have builders, we can "overload" their functionality and have them serve users in more complicated ways, eg. by supporting ERC-4337 fee markets. In this new philosophy, the transaction validation parts of ERC-4337 would have to be enshrined into the protocol. Fortunately, the ERC-4337 team is already increasingly warm about this direction.Summary: MEV thought has already been going back in the direction of empowering block producers, including giving block producers the authority to directly ensure the inclusion of users' transactions. Account abstraction proposals are already going back in the direction of removing reliance on centralized relayers, and even bundlers. However, there is a good argument that we are not going far enough, and I think pressure pushing the development process to go further in that direction is highly welcome.Liquid stakingToday, solo stakers make up a relatively small percentage of all Ethereum staking, and most staking is done by various providers - some centralized operators, and others DAOs, like Lido and RocketPool. I have done my own research - various polls [1] [2], surveys, in-person conversations, asking the question "why are you - specifically you - not solo staking today?" To me, a robust solo staking ecosystem is by far my preferred outcome for Ethereum staking, and one of the best things about Ethereum is that we actually try to support a robust solo staking ecosystem instead of just surrendering to delegation. However, we are far from that outcome. In my polls and surveys, there are a few consistent trends:The great majority of people who are not solo staking cite their primary reason as being the 32 ETH minimum. Out of those who cite other reasons, the highest is technical challenge of running and maintaining a validator node. The loss of instant availability of ETH, the security risks of "hot" private keys, and the loss of ability to simultaneously participate in defi protocols, are significant but smaller concerns. The main reasons why people are not solo staking, according to Farcaster polls. There are two key questions for staking research to resolve:How do we solve these concerns? If, despite effective solutions to most of these concerns, most people still don't want to solo stake, how do we keep the protocol stable and robust against attacks despite that fact? Many ongoing research and development items are aimed precisely at solving these problems:Verkle trees plus EIP-4444 allow staking nodes to function with very low hard disk requirements. Additionallty, they allow staking nodes to sync almost instantly, greatly simplifying the setup process, as well as operations such as switching from one implementation to another. They also make Ethereum light clients much more viable, by reducing the data bandwidth needed to provide proofs for every state access. Research (eg. these proposals) into ways to allow a much larger valdiator set (enabling much smaller staking minimums) while at the same time reducing consensus node overhead. These ideas can be implemented as part of single slot finality. Doing this would also makes light clients safer, as they would be able to verify the full set of signatures instead of relying on sync committees). Ongoing Ethereum client optimizations keep reducing the cost and difficulty of running a validator node, despite growing history. Research on penalties capping could potentially mitigate concerns around private key risk, and make it possible for stakers to simultaneously stake their ETH in defi protocols if that's what they wish to do. 0x01 Withdrawal credentials allow stakers to set an ETH address as their withdrawal address. This makes decentralized staking pools more viable, giving them a leg up against centralized staking pools. However, once again there is more that we could do. It is theoretically possible to allow validators to withdraw much more quickly: Casper FFG continues to be safe even if the validator set changes by a few percent ever time it finalizes (ie. once per epoch). Hence, we could reduce the withdrawal period much more if we put effort into it. If we wanted to greatly reduce the minimum deposit size, we could make a hard decision to trade off in other directions, eg. if we increase the finality time by 4x, that would allow a 4x minimum deposit size decrease. Single slot finality would later clean this up by moving beyond the "every staker participates in every epoch" model entirely.Another important part of this whole question is the economics of staking. A key question is: do we want staking to be a relatively niche activity, or do we want everyone or almost everyone to stake all of their ETH? If everyone is staking, then what is the responsibility that we want everyone to take on? If people end up simply delegating this responsibility because they are lazy, that could end up leading to centralization. There are important and deep philosophical questions here. Incorrect answers could lead Ethereum down a path of centralization and "re-creating the traditional financial system with extra steps"; correct answers could create a shining example of a successful ecosystem with a wide and diverse set of solo stakers and highly decentralized staking pools. These are questions that touch on core Ethereum economics and values, and so we need more diverse participation here.Hardware requirements of nodesMany of the key questions in Ethereum decentralization end up coming down to a question that has defined blockchain politics for a decade: how accessible do we want to make running a node, and how?Today, running a node is hard. Most people do not do it. On the laptop that I am using to write this post, I have a reth node, and it takes up 2.1 terabytes - already the result of heroic software engineering and optimization. I needed to go and buy an extra 4 TB hard drive to put into my laptop in order to store this node. We all want running a node to be easier. In my ideal world, people would be able to run nodes on their phones.As I wrote above, EIP-4444 and Verkle trees are two key technologies that get us closer to this ideal. If both are implemented, hardware requirements of a node could plausibly eventually decrease to less than a hundred gigabytes, and perhaps to near-zero if we eliminate the history storage responsibility (perhaps only for non-staking nodes) entirely. Type 1 ZK-EVMs would remove the need to run EVM computation yourself, as you could instead simply verify a proof that the execution was correct. In my ideal world, we stack all of these technologies together, and even Ethereum browser extension wallets (eg. Metamask, Rabby) have a built-in node that verifies these proofs, does data availability sampling, and is satisfied that the chain is correct. The vision described above is often called "The Verge". This is all known and understood, even by people raising the concerns about Ethereum node size. However, there is an important concern: if we are offloading the responsibility to maintain state and provide proofs, then is that not a centralization vector? Even if they can't cheat by providing invalid data, doesn't it still go against the principles of Ethereum to get too dependent on them?One very near-term version of this concern is many people's discomfort toward EIP-4444: if regular Ethereum nodes no longer need to store old history, then who does? A common answer is: there are certainly enough big actors (eg. block explorers, exchanges, layer 2s) who have the incentive to hold that data, and compared to the 100 petabytes stored by the Wayback Machine, the Ethereum chain is tiny. So it's ridiculous to think that any history will actually be lost.However, this arguments relies on dependence on a small number of large actors. In my taxonomy of trust models, it's a 1-of-N assumption, but the N is pretty small. This has its tail risks. One thing that we could do instead is to store old history in a peer-to-peer network, where each node only stores a small percentage of the data. This kind of network would still do enough copying to ensure robustness: there would be thousands of copies of each piece of data, and in the future we could use erasure coding (realistically, by putting history into EIP-4844-style blobs, which already have erasure coding built in) to increase robustness further. Blobs have erasure coding within blobs and between blobs. The easiest way to make ultra-robust storage for all of Ethereum's history may well be to just put beacon and execution blocks into blobs. Image source: codex.storage For a long time, this work has been on the backburner; Portal Network exists, but realistically it has not gotten the level of attention commensurate with its importance in Ethereum's future. Fortunately, there is now strong interest in momentum toward putting far more resources into a minimized version of Portal that focuses on distributed storage, and accessibility, of history. This momentum should be built on, and we should make a concerted effort to implement EIP-4444 soon, paired with a robust decentralized peer-to-peer network for storing and retrieving old history.For state and ZK-EVMs, this kind of distributed approach is harder. To build an efficient block, you simply have to have the full state. In this case, I personally favor a pragmatic approach: we define, and stick to, some level of hardware requirements needed to have a "node that does everything", which is higher than the (ideally ever-decreasing) cost of simply validating the chain, but still low enough to be affordable to hobbyists. We rely on a 1-of-N assumption, where we ensure that the N is quite large. For example, this could be a high-end consumer laptop.ZK-EVM proving is likely to be the trickiest piece, and real-time ZK-EVM provers are likely to require considerably beefier hardware than an archive node, even with advancements like Binius, and worst-case-bounding with multidimensional gas. We could work hard on a distributed proving network, where each node takes on the responsibility to prove eg. one percent of a block's execution, and then the block producer only needs to aggregate the hundred proofs at the end. Proof aggregation trees could help further. But if this doesn't work well, then one other compromise would be to allow the hardware requirements of proving to get higher, but make sure that a "node that does everything" can verify Ethereum blocks directly (without a proof), fast enough to effectively participate in the network.ConclusionsI think it is actually true that 2021-era Ethereum thought became too comfortable with offloading responsibilities to a small number of large-scale actors, as long as some kind of market mechanism or zero knowledge proof system existed to force the centralized actors to behave honestly. Such systems often work well in the average case, but fail catastrophically in the worst case. We're not doing this. At the same time, I think it's important to emphasize that current Ethereum protocol proposals have already significantly moved away from that kind of model, and take the need for a truly decentralized network much more seriously. Ideas around stateless nodes, MEV mitigations, single-slot finality, and similar concepts, already are much further in this direction. A year ago, the idea of doing data availability sampling by piggy-backing on relays as semi-centralized nodes was seriously considered. This year, we've moved beyond the need to do such things, with surprisingly robust progress on PeerDAS.But there is a lot that we could do to go further in this direction, on all three axes that I talked about above, as well as many other important axes. Helios has made great progress in giving Ethereum an "actual light client". Now, we need to get it included by default in Ethereum wallets, and make RPC providers provide proofs along with their results so that they can be validated, and extend light client technology to layer 2 protocols. If Ethereum is scaling via a rollup-centric roadmap, layer 2s need to get the same security and decentralization guarantees as layer 1. In a rollup-centric world, there are many other things that we should be taking more seriously; decentralized and efficient cross-L2 bridges are one example of many. Many dapps get their logs through centralized protocols, as Ethereum's native log scanning has become too slow. We could improve on this with a dedicated decentralized sub-protocol; here is one proposal of mine for how this could be done.There is a near-unlimited number of blockchain projects aiming for the niche of "we can be super-fast, we'll think about decentralization later". I don't think Ethereum should be one of those projects. Ethereum L1 can and certainly should be a strong base layer for layer 2 projects that do take a hyper-scale approach, using Ethereum as a backbone for decentralization and security. Even a layer-2-centric approach requires layer 1 itself to have sufficient scalability to handle a significant number of operations. But we should have deep respect for the properties that make Ethereum unique, and continue to work to maintain and improve on those properties as Ethereum scales.
-
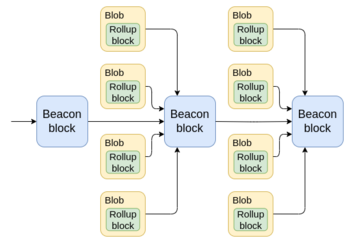
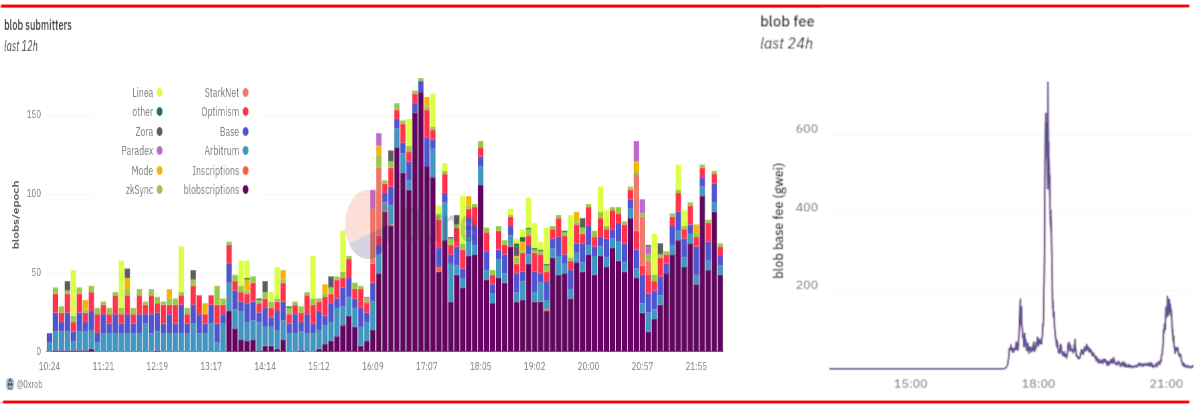
Multidimensional gas pricing Multidimensional gas pricing2024 May 09 See all posts Multidimensional gas pricing Special thanks to Ansgar Dietrichs, Barnabe Monnot and Davide Crapis for feedback and review.In Ethereum, resources were up until recently limited, and priced, using a single resource called "gas". Gas is a measure of the amount of "computational effort" needed to process a given transaction or block. Gas merges together multiple types of "effort", most notably:Raw computation (eg. ADD, MULTIPLY) Reading and writing to Ethereum's storage (eg. SSTORE, SLOAD, ETH transfers) Data bandwidth Cost of generating a ZK-SNARK proof of the block For example, this transaction that I sent cost a total of 47,085 gas. This is split between (i) a "base cost" of 21000 gas, (ii) 1556 gas for the bytes in the calldata included as part of the transaction (iii) 16500 gas for reading and writing to storage, (iv) gas 2149 for making a log, and the rest for EVM execution. The transaction fee that a user must pay is proportional to the gas that the transaction consumes. A block can contain up to a maximum of 30 million gas, and gas prices are constantly adjusted via the EIP-1559 targeting mechanism, ensuring that on average, blocks contain 15 million gas.This approach has one major efficiency: because everything is merged into one virtual resource, it leads to a very simple market design. Optimizing a transaction to minimize costs is easy, optimizing a block to collect the highest possible fees is relatively easy (not including MEV), and there are no weird incentives that encourage some transactions to bundle with other transactions to save on fees.But this approach also has one major inefficiency: it treats different resources as being mutually convertible, when the actual underlying limits of what the network can handle are not. One way to understand this issue is to look at this diagram: The gas limit enforces a constraint of \(x_1 * data + x_2 * computation < N\). The actual underlying safety constraint is often closer to \(max(x_1 * data, x_2 * computation) < N\). This discrepancy leads to either the gas limit needlessly excluding actually-safe blocks, or accepting actually-unsafe blocks, or some mixture of both.If there are \(n\) resources that have distinct safety limits, then one-dimensional gas plausibly reduces throughput by up to a factor of \(n\). For this reason, there has for a long time been interest in the concept of multi-dimensional gas, and with EIP-4844 we actually have multi-dimensional gas working on Ethereum today. This post explores the benefits of this approach, and the prospects for increasing it further.Blobs: multi-dimensional gas in DencunAt the start of this year, the average block was 150 kB in size. A large fraction of that size is rollup data: layer 2 protocols storing data on chain for security. This data was expensive: even though transactions on rollups would cost ~5-10x less than corresponding transactions on the Ethereum L1, even that cost was too high for many use cases.Why not decrease the calldata gas cost (currently 16 gas per nonzero byte and 4 gas per zero byte), to make rollups cheaper? We did this before, we could do it again. The answer here is: the worst-case size of a block was \(\frac = 1,875,000\) nonzero bytes, and the network already can barely handle blocks of that size. Reducing costs by another 4x would raise the maximum to 7.5 MB, which would be a huge risk to safety.This problem ended up being handled by introducing a separate space of rollup-friendly data, known as "blobs", into each block. The two resources have separate prices and separate limits: after the Dencun hard fork, an Ethereum block can contain at most (i) 30 million gas, and (ii) 6 blobs, which can contain ~125 kB of calldata each. Both resources have separate prices, adjusted by separate EIP-1559-like pricing mechanisms, targeting an average usage of 15 million gas and 3 blobs per block.As a result, rollups have become 100x cheaper, transaction volume on rollups increased by more than 3x, and the theoretical maximum block size was only increased slightly: from ~1.9 MB to ~2.6 MB. Transaction fees on rollups, courtesy of growthepie.xyz. The Dencun fork, which introduced blobs with multidimensional pricing, happened on 2024 Mar 13. Multi-dimensional gas and stateless clientsIn the near future, a similar problem will arise regarding storage proofs for stateless clients. Stateless clients are a new type of client which will be able to verify the chain without storing much or any data locally. Stateless clients do this by accepting proofs of the specific pieces of Ethereum state that transactions in that block need to touch. A stateless client receives a block, together with proofs proving the current values in the specific parts of the state (eg. account balances, code, storage) that the block execution touches. This allows a node to verify a block without having any storage itself. A storage read costs 2100-2600 gas depending on the type of read, and storage writes cost more. On average, a block does something like 1000 storage reads and writes (including ETH balance checks, SSTORE and SLOAD calls, contract code reading, and other operations). The theoretical maximum, however, is \(\frac = 14,285\) reads. A stateless client's bandwidth load is directly proportional to this number.Today, the plan is to support stateless clients by moving Ethereum's state tree design from Merkle Patricia trees to Verkle trees. However, Verkle trees are not quantum-resistant, and are not optimal for newer waves of STARK proving systems. As a result, many people are interested in supporting stateless clients through binary Merkle trees and STARKs instead - either skipping Verkle entirely, or upgrading a couple of years after the Verkle transition once STARKs become more mature.STARK proofs of binary hash tree branches have many advantages, but they have the key weakness that proofs take a long time to generate: while Verkle trees can prove over a hundred thousand values per second, hash-based STARKs can typically prove only a couple thousand hashes per second, and proving each value requires a "branch" containing many hashes.Given the numbers that are being projected today from hyper-optimized proof systems such as Binius and Plonky3 and specialized hashes like Vision-Mark-32, it seems likely that we will for some time be in a regime where it's practical to prove 1,000 values in less than a second, but not 14,285 values. Average blocks would be fine, but worst-case blocks, potentially published by an attacker, would break the network.The "default" way we have handled such a scenario is re-pricing: make storage reading more expensive to reduce the per-block maximum to something safer. However, we have already done this many times, and it would make too many applications too expensive to do this again. A better approach would be multidimensional gas: limit and charge for storage access separately, keeping the average usage at 1,000 storage accesses per block but setting a per-block limit of eg. 2,000.Multidimensional gas more generallyOne other resource that is worth thinking about is state size growth: operations that increase the size of the Ethereum state, which full nodes will need to hold from then on. The unique property of state size growth is that the rationale from limiting it comes entirely from long-run sustained usage, and not spikes. Hence, there may be value in adding a separate gas dimension for state size increasing operations (eg. zero-to-nonzero SSTORE, contract creation), but with a differnet goal: we could set a floating price to target a specific average usage, but set no per-block limit at all.This shows one of the powerful properties of multidimensional gas: it lets us separately ask the questions of (i) what is the ideal average usage, and (ii) what is the safe per-block maximum usage, for each resource. Rather than setting gas prices based on per-block maximums, and letting average usage follow, we have \(2n\) degrees of freedom to set \(2n\) parameters, tuning each one based on what is safe for the network.More complicated situations, like where two resources have safety considerations that are partially additive, could be handled by making an opcode or resource cost some quantity of multiple types of gas (eg. a zero-to-nonzero SSTORE could cost 5000 stateless-client-proof gas and 20000 storage-expansion gas).Per-transaction max: the weaker-but-easier way to get multidimensional gasLet \(x_1\) be the gas cost of data and \(x_2\) be the gas cost of computation, so in a one-dimensional gas system we can write the gas cost of a transaction:\[gas = x_1 * data + x_2 * computation\]In this scheme, we instead define the gas cost of a transaction as:\[gas = max(x_1 * data, x_2 * computation)\]That is, instead of a transaction being charged for data plus computation, the transaction gets charged based on which of the two resources it consumes more of. This can easily be extended to cover more dimensions (eg. \(max(..., x_3 * storage\_access)\)).It should be easy to see how this improves throughput while preserving safety. The theoretical max amount of data in a block is still \(\frac\), exactly the same as in the one-dimensional gas scheme. Similarly, the theoretical max amount of computation is \(\frac\), again exactly the same as in the one-dimensional gas scheme. However, the gas cost of any transaction that consumes both data and computation decreases.This is approximately the scheme employed in the proposed EIP-7623, to reduce maximum block size while increasing blob count further. The precise mechanism in EIP-7623 is slightly more complicated: it keeps the current calldata price of 16 gas per byte, but it adds a "floor price" of 48 gas per byte; a transaction pays the higher of (16 * bytes + execution_gas) and (48 * bytes). As a result, EIP-7623 decreases the theoretical max transaction calldata in a block from ~1.9 MB to ~0.6 MB, while leaving the costs of most applications unchanged. The benefit of this approach is that it is a very small change from the current single-dimensional gas scheme, and so it is very easy to implement.There are two drawbacks:Transactions that are heavy on one resource are still needlessly charged a large amount, even if all the other transactions in the block use little of that resource. It creates incentives for data-heavy and computation-heavy transactions to merge together into a bundle to save costs. I would argue that an EIP-7623-style rule, both for transaction calldata and for other resources, can bring large-enough benefits to be worth it even despite these drawbacks. However, if and when we are willing to put in the (significantly higher) development effort, there is a more ideal approach.Multidimensional EIP-1559: the harder-but-ideal strategyLet us first recap how "regular" EIP-1559 works. We will focus on the version that was introduced in EIP-4844 for blobs, because it's mathematically more elegant.We track a parameter, excess_blobs. During each block, we set:excess_blobs
-
Binius: highly efficient proofs over binary fields Binius: highly efficient proofs over binary fields2024 Apr 29 See all posts Binius: highly efficient proofs over binary fields This post is primarily intended for readers roughly familiar with 2019-era cryptography, especially SNARKs and STARKs. If you are not, I recommend reading those articles first. Special thanks to Justin Drake, Jim Posen, Benjamin Diamond and Radi Cojbasic for feedback and review.Over the past two years, STARKs have become a crucial and irreplaceable technology for efficiently making easy-to-verify cryptographic proofs of very complicated statements (eg. proving that an Ethereum block is valid). A key reason why is small field sizes: whereas elliptic curve-based SNARKs require you to work over 256-bit integers in order to be secure enough, STARKs let you use much smaller field sizes, which are more efficient: first the Goldilocks field (64-bit integers), and then Mersenne31 and BabyBear (both 31-bit). Thanks to these efficiency gains, Plonky2, which uses Goldilocks, is hundreds of times faster at proving many kinds of computation than its predecessors.A natural question to ask is: can we take this trend to its logical conclusion, building proof systems that run even faster by operating directly over zeroes and ones? This is exactly what Binius is trying to do, using a number of mathematical tricks that make it very different from the SNARKs and STARKs of three years ago. This post goes through the reasons why small fields make proof generation more efficient, why binary fields are uniquely powerful, and the tricks that Binius uses to make proofs over binary fields work so effectively. Binius. By the end of this post, you should be able to understand every part of this diagram. Table of contentsRecap: finite fields Recap: arithmetization Plonky2: from 256-bit SNARKs and STARKs to 64-bit... only STARKs From small primes to binary From univariate polynomials to hypercubes Simple Binius - an example Binary fields Full Binius Putting it all together What did we not cover? Recap: finite fieldsOne of the key tasks of a cryptographic proving system is to operate over huge amounts of data, while keeping the numbers small. If you can compress a statement about a large program into a mathematical equation involving a few numbers, but those numbers are as big as the original program, you have not gained anything.To do complicated arithmetic while keeping numbers small, cryptographers generally use modular arithmetic. We pick some prime "modulus" p. The % operator means "take the remainder of": \(15\ \%\ 7 = 1\), \(53\ \%\ 10 = 3\), etc (note that the answer is always non-negative, so for example \(-1\ \%\ 10 = 9\)). You've probably already seen modular arithmetic, in the context of adding and subtracting time (eg. what time is four hours after 9:00?). But here, we don't just add and subtract modulo some number, we also multiply, divide and take exponents. We redefine:\(x + y \Rightarrow (x + y)\) % \(p\)\(x * y \Rightarrow (x * y)\) % \(p\)\(x^y \Rightarrow (x^y)\) % \(p\)\(x - y \Rightarrow (x - y)\) % \(p\)\(x / y \Rightarrow (x * y ^)\) % \(p\)The above rules are all self-consistent. For example, if \(p = 7\), then:\(5 + 3 = 1\) (because \(8\) % \(7 = 1\)) \(1 - 3 = 5\) (because \(-2\) % \(7 = 5\)) \(2 \cdot 5 = 3\) \(3 / 5 = 2\) (because (\(3 \cdot 5^5\)) % \(7 = 9375\) % \(7 = 2\)) A more general term for this kind of structure is a finite field. A finite field is a mathematical structure that obeys the usual laws of arithmetic, but where there's a limited number of possible values, and so each value can be represented in a fixed size.Modular arithmetic (or prime fields) is the most common type of finite field, but there is also another type: extension fields. You've probably already seen an extension field before: the complex numbers. We "imagine" a new element, which we label \(i\), and declare that it satisfies \(i^2 = -1\). You can then take any combination of regular numbers and \(i\), and do math with it: \((3i+2) * (2i + 4) =\) \(6i^2 + 12i + 4i + 8 = 16i + 2\). We can similarly take extensions of prime fields. As we start working over fields that are smaller, extensions of prime fields become increasingly important for preserving security, and binary fields (which Binius uses) depend on extensions entirely to have practical utility.Recap: arithmetizationThe way that SNARKs and STARKs prove things about computer programs is through arithmetization: you convert a statement about a program that you want to prove, into a mathematical equation involving polynomials. A valid solution to the equation corresponds to a valid execution of the program.To give a simple example, suppose that I computed the 100'th Fibonacci number, and I want to prove to you what it is. I create a polynomial \(F\) that encodes Fibonacci numbers: so \(F(0) = F(1) = 1\), \(F(2) = 2\), \(F(3) = 3\), \(F(4) = 5\), and so on for 100 steps. The condition that I need to prove is that \(F(x+2) = F(x) + F(x+1)\) across the range \(x = \\). I can convince you of this by giving you the quotient:\[H(x) = \frac\]Where \(Z(x) = (x - 0) * (x - 1) * ... * (x - 98)\). If I can provide valid \(F\) and \(H\) that satisfy this equation, then \(F\) must satisfy \(F(x+2) - F(x+1) - F(x)\) across that range. If I additionally verify that \(F\) satisfies \(F(0) = F(1) = 1\), then \(F(100)\) must actually be the 100th Fibonacci number.If you want to prove something more complicated, then you replace the "simple" relation \(F(x+2) = F(x) + F(x+1)\) with a more complicated equation, which basically says "\(F(x+1)\) is the output of initializing a virtual machine with the state \(F(x)\), and running one computational step". You can also replace the number 100 with a bigger number, eg. 100000000, to accommodate more steps.All SNARKs and STARKs are based on this idea of using a simple equation over polynomials (or sometimes vectors and matrices) to represent a large number of relationships between individual values. Not all involve checking equivalence between adjacent computational steps in the same way as above: PLONK does not, for example, and neither does R1CS. But many of the most efficient ones do, because enforcing the same check (or the same few checks) many times makes it easier to minimize overhead.Plonky2: from 256-bit SNARKs and STARKs to 64-bit... only STARKsFive years ago, a reasonable summary of the different types of zero knowledge proof was as follows. There are two types of proofs: (elliptic-curve-based) SNARKs and (hash-based) STARKs. Technically, STARKs are a type of SNARK, but in practice it's common to use "SNARK" to refer to only the elliptic-curve-based variety, and "STARK" to refer to hash-based constructions. SNARKs are small, and so you can verify them very quickly and fit them onchain easily. STARKs are big, but they don't require trusted setups, and they are quantum-resistant. STARKs work by treating the data as a polynomial, computing evaluations of that polynomial across a large number of points, and using the Merkle root of that extended data as the "polynomial commitment" A key bit of history here is that elliptic curve-based SNARKs came into widespread use first: it took until roughly 2018 for STARKs to become efficient enough to use, thanks to FRI, and by then Zcash had already been running for over a year. Elliptic curve-based SNARKs have a key limitation: if you want to use elliptic curve-based SNARKs, then the arithmetic in these equations must be done with integers modulo the number of points on the elliptic curve. This is a big number, usually near \(2^\): for example, for the bn128 curve, it's 21888242871839275222246405745257275088548364400416034343698204186575808495617. But the actual computation is using small numbers: if you think about a "real" program in your favorite language, most of the stuff it's working with is counters, indices in for loops, positions in the program, individual bits representing True or False, and other things that will almost always be only a few digits long.Even if your "original" data is made up of "small" numbers, the proving process requires computing quotients, extensions, random linear combinations, and other transformations of the data, which lead to an equal or larger number of objects that are, on average, as large as the full size of your field. This creates a key inefficiency: to prove a computation over n small values, you have to do even more computation over n much bigger values. At first, STARKs inherited the habit of using 256-bit fields from SNARKs, and so suffered the same inefficiency. A Reed-Solomon extension of some polynomial evaluations. Even though the original values are small, the extra values all blow up to the full size of the field (in this case \(2^ - 1\)). In 2022, Plonky2 was released. Plonky2's main innovation was doing arithmetic modulo a smaller prime: \(2^ - 2^ + 1 = 18446744069414584321\). Now, each addition or multiplication can always be done in just a few instructions on a CPU, and hashing all of the data together is 4x faster than before. But this comes with a catch: this approach is STARK-only. If you try to use a SNARK, with an elliptic curve of such a small size, the elliptic curve becomes insecure.To continue to be safe, Plonky2 also needed to introduce extension fields. A key technique in checking arithmetic equations is "sampling at a random point": if you want to check if \(H(x) * Z(x)\) actually equals \(F(x+2) - F(x+1) - F(x)\), you can pick some random coordinate \(r\), provide polynomial commitment opening proofs proving \(H(r)\), \(Z(r)\), \(F(r)\), \(F(r+1)\) and \(F(r+2)\), and then actually check if \(H(r) * Z(r)\) equals \(F(r+2) - F(r+1) - F(r)\). If the attacker can guess the coordinate ahead of time, the attacker can trick the proof system - hence why it must be random. But this also means that the coordinate must be sampled from a set large enough that the attacker cannot guess it by random chance. If the modulus is near \(2^\), this is clearly the case. But with a modulus of \(2^ - 2^ + 1\), we're not quite there, and if we drop to \(2^ - 1\), it's definitely not the case. Trying to fake a proof two billion times until one gets lucky is absolutely within the range of an attacker's capabilities.To stop this, we sample \(r\) from an extension field. For example, you can define \(y\) where \(y^3 = 5\), and take combinations of \(1\), \(y\) and \(y^2\). This increases the total number of coordinates back up to roughly \(2^\). The bulk of the polynomials computed by the prover don't go into this extension field; they just use integers modulo \(2^-1\), and so you still get all the efficiencies from using the small field. But the random point check, and the FRI computation, does dive into this larger field, in order to get the needed security.From small primes to binaryComputers do arithmetic by representing larger numbers as sequences of zeroes and ones, and building "circuits" on top of those bits to compute things like addition and multiplication. Computers are particularly optimized for doing computation with 16-bit, 32-bit and 64-bit integers. Moduluses like \(2^ - 2^ + 1\) and \(2^ - 1\) are chosen not just because they fit within those bounds, but also because they align well with those bounds: you can do multiplication modulo \(2^ - 2^ + 1\) by doing regular 32-bit multiplication, and shift and copy the outputs bitwise in a few places; this article explains some of the tricks well.What would be even better, however, is doing computation in binary directly. What if addition could be "just" XOR, with no need to worry about "carrying" the overflow from adding 1 + 1 in one bit position to the next bit position? What if multiplication could be more parallelizable in the same way? And these advantages would all come on top of being able to represent True/False values with just one bit.Capturing these advantages of doing binary computation directly is exactly what Binius is trying to do. A table from the Binius team's zkSummit presentation shows the efficiency gains: Despite being roughly the same "size", a 32-bit binary field operation takes 5x less computational resources than an operation over the 31-bit Mersenne field.From univariate polynomials to hypercubesSuppose that we are convinced by this reasoning, and want to do everything over bits (zeroes and ones). How do we actually commit to a polynomial representing a billion bits?Here, we face two practical problems:For a polynomial to represent a lot of values, those values need to be accessible at evaluations of the polynomial: in our Fibonacci example above, \(F(0)\), \(F(1)\) ... \(F(100)\), and in a bigger computation, the indices would go into the millions. And the field that we use needs to contain numbers going up to that size. Proving anything about a value that we're committing to in a Merkle tree (as all STARKs do) requires Reed-Solomon encoding it: extending \(n\) values into eg. \(8n\) values, using the redundancy to prevent a malicious prover from cheating by faking one value in the middle of the computation. This also requires having a large enough field: to extend a million values to 8 million, you need 8 million different points at which to evaluate the polynomial. A key idea in Binius is solving these two problems separately, and doing so by representing the same data in two different ways. First, the polynomial itself. Elliptic curve-based SNARKs, 2019-era STARKs, Plonky2 and other systems generally deal with polynomials over one variable: \(F(x)\). Binius, on the other hand, takes inspiration from the Spartan protocol, and works with multivariate polynomials: \(F(x_1, x_2 ... x_k)\). In fact, we represent the entire computational trace on the "hypercube" of evaluations where each \(x_i\) is either 0 or 1. For example, if we wanted to represent a sequence of Fibonacci numbers, and we were still using a field large enough to represent them, we might visualize the first sixteen of them as being something like this: That is, \(F(0,0,0,0)\) would be 1, \(F(1,0,0,0)\) would also be 1, \(F(0,1,0,0)\) would be 2, and so forth, up until we get to \(F(1,1,1,1) = 987\). Given such a hypercube of evaluations, there is exactly one multilinear (degree-1 in each variable) polynomial that produces those evaluations. So we can think of that set of evaluations as representing the polynomial; we never actually need to bother computing the coefficients.This example is of course just for illustration: in practice, the whole point of going to a hypercube is to let us work with individual bits. The "Binius-native" way to count Fibonacci numbers would be to use a higher-dimensional cube, using each set of eg. 16 bits to store a number. This requires some cleverness to implement integer addition on top of the bits, but with Binius it's not too difficult.Now, we get to the erasure coding. The way STARKs work is: you take \(n\) values, Reed-Solomon extend them to a larger number of values (often \(8n\), usually between \(2n\) and \(32n\)), and then randomly select some Merkle branches from the extension and perform some kind of check on them. A hypercube has length 2 in each dimension. Hence, it's not practical to extend it directly: there's not enough "space" to sample Merkle branches from 16 values. So what do we do instead? We pretend the hypercube is a square!Simple Binius - an exampleSee here for a python implementation of this protocol.Let's go through an example, using regular integers as our field for convenience (in a real implementation this will be binary field elements). First, we take the hypercube we want to commit to, and encode it as a square: Now, we Reed-Solomon extend the square. That is, we treat each row as being a degree-3 polynomial evaluated at x = , and evaluate the same polynomial at x = : Notice that the numbers blow up quickly! This is why in a real implementation, we always use a finite field for this, instead of regular integers: if we used integers modulo 11, for example, the extension of the first row would just be [3, 10, 0, 6].If you want to play around with extending and verify the numbers here for yourself, you can use my simple Reed-Solomon extension code here.Next, we treat this extension as columns, and make a Merkle tree of the columns. The root of the Merkle tree is our commitment. Now, let's suppose that the prover wants to prove an evaluation of this polynomial at some point \(r = \\). There is one nuance in Binius that makes it somewhat weaker than other polynomial commitment schemes: the prover should not know, or be able to guess, \(s\), until after they committed to the Merkle root (in other words, \(r\) should be a pseudo-random value that depends on the Merkle root). This makes the scheme useless for "database lookup" (eg. "ok you gave me the Merkle root, now prove to me \(P(0, 0, 1, 0)\)!"). But the actual zero-knowledge proof protocols that we use generally don't need "database lookup"; they simply need to check the polynomial at a random evaluation point. Hence, this restriction is okay for our purposes.Suppose we pick \(r = \\) (the polynomial, at this point, evaluates to \(-137\); you can confirm it with this code). Now, we get into the process of actually making the proof. We split up \(r\) into two parts: the first part \(\\) representing a linear combination of columns within a row, and the second part \(\\) representing a linear combination of rows. We compute a "tensor product", both for the column part:\[\bigotimes_^1 (1 - r_i, r_i)\]And for the row part:\[\bigotimes_^3 (1 - r_i, r_i)\]What this means is: a list of all possible products of one value from each set. In the row case, we get:\[[(1 - r_2) * (1 - r_3), r_2 * (1 - r_3), (1 - r_2) * r_3, r_2 * r_3]\]Using \(r = \\) (so \(r_2 = 3\) and \(r_3 = 4\)):\[ [(1 - 3) * (1 - 4), 3 * (1 - 4), (1 - 3) * 4, 3 * 4] \\ = [6, -9, -8, 12]\]Now, we compute a new "row" \(t'\), by taking this linear combination of the existing rows. That is, we take:\[\begin[3, 1, 4, 1] * 6\ + \\ [5, 9, 2, 6] * (-9)\ + \\ [5, 3, 5, 8] * (-8)\ + \\ [9, 7, 9, 3] * 12 = \\ [41, -15, 74, -76] \end\]You can view what's going on here as a partial evaluation. If we were to multiply the full tensor product \(\bigotimes_^3 (1 - r_i, r_i)\) by the full vector of all values, you would get the evaluation \(P(1, 2, 3, 4) = -137\). Here we're multiplying a partial tensor product that only uses half the evaluation coordinates, and we're reducing a grid of \(N\) values to a row of \(\sqrt\) values. If you give this row to someone else, they can use the tensor product of the other half of the evaluation coordinates to complete the rest of the computation.The prover provides the verifier with this new row, \(t'\), as well as the Merkle proofs of some randomly sampled columns. This is \(O(\sqrt)\) data. In our illustrative example, we'll have the prover provide just the last column; in real life, the prover would need to provide a few dozen columns to achieve adequate security.Now, we take advantage of the linearity of Reed-Solomon codes. The key property that we use is: taking a linear combination of a Reed-Solomon extension gives the same result as a Reed-Solomon extension of a linear combination. This kind of "order independence" often happens when you have two operations that are both linear.The verifier does exactly this. They compute the extension of \(t'\), and they compute the same linear combination of columns that the prover computed before (but only to the columns provided by the prover), and verify that these two procedures give the same answer. In this case, extending \(t'\), and computing the same linear combination (\([6, -9, -8, 12]\)) of the column, both give the same answer: \(-10746\). This proves that the Merkle root was constructed "in good faith" (or it at least "close enough"), and it matches \(t'\): at least the great majority of the columns are compatible with each other and with \(t'\).But the verifier still needs to check one more thing: actually check the evaluation of the polynomial at \(\\). So far, none of the verifier's steps actually depended on the value that the prover claimed. So here is how we do that check. We take the tensor product of what we labelled as the "column part" of the evaluation point:\[\bigotimes_^1 (1 - r_i, r_i)\]In our example, where \(r = \\) (so the half that chooses the column is \(\\)), this equals:\[ [(1 - 1) * (1 - 2), 1 * (1 - 2), (1 - 1) * 2, 1 * 2] \\ = [0, -1, 0, 2]\]So now we take this linear combination of \(t'\):\[ 0 * 41 + (-1) * (-15) + 0 * 74 + 2 * (-76) = -137 \]Which exactly equals the answer you get if you evaluate the polynomial directly.The above is pretty close to a complete description of the "simple" Binius protocol. This already has some interesting advantages: for example, because the data is split into rows and columns, you only need a field half the size. But this doesn't come close to realizing the full benefits of doing computation in binary. For this, we will need the full Binius protocol. But first, let's get a deeper understanding of binary fields.Binary fieldsThe smallest possible field is arithmetic modulo 2, which is so small that we can write out its addition and multiplication tables:+ 0 1 0 0 1 1 1 0 * 0 1 0 0 0 1 0 1 We can make larger binary fields by taking extensions: if we start with \(F_2\) (integers modulo 2) and then define \(x\) where \(x^2 = x + 1\), we get the following addition and multiplication tables:+ 0 1 x x+1 0 0 1 x x+1 1 1 0 x+1 x x x x+1 0 1 x+1 x+1 x 1 0 + 0 1 x x+1 0 0 0 0 0 1 0 1 x x+1 x 0 x x+1 1 x+1 0 x+1 1 x It turns out that we can expand the binary field to arbitrarily large sizes by repeating this construction. Unlike with complex numbers over reals, where you can add one new element \(i\), but you can't add any more (quaternions do exist, but they're mathematically weird, eg. \(ab \neq ba\)), with finite fields you can keep adding new extensions forever. Specifically, we define elements as follows:\(x_0\) satisfies \(x_0^2 = x_0 + 1\) \(x_1\) satisfies \(x_1^2 = x_1x_0 + 1\) \(x_2\) satisfies \(x_2^2 = x_2x_1 + 1\) \(x_3\) satisfies \(x_3^2 = x_3x_2 + 1\) And so on. This is often called the tower construction, because of how each successive extension can be viewed as adding a new layer to a tower. This is not the only way to construct binary fields of arbitary size, but it has some unique advantages that Binius takes advantage of.We can represent these numbers as a list of bits, eg. \(\texttt\). The first bit represents multiples of 1, the second bit represents multiples of \(x_0\), then subsequent bits represent multiples of: \(x_1\), \(x_1 * x_0\), \(x_2\), \(x_2 * x_0\), and so forth. This encoding is nice because you can decompose it: \(\texttt = \texttt + \texttt * x_3\) \(= \texttt + \texttt * x_2 + \texttt * x_3 + \texttt * x_2x_3\) \(= \texttt + \texttt * x_2 + \texttt * x_2x_1 + \texttt * x_3 + \texttt * x_2x_3 + \texttt * x_1x_2x_3\) \(= 1 + x_0 + x_2 + x_2x_1 + x_3 + x_2x_3 + x_0x_2x_3 + x_1x_2x_3 + x_0x_1x_2x_3\) This is a relatively uncommon notation, but I like representing binary field elements as integers, taking the bit representation where more-significant bits are to the right. That is, \(\texttt = 1\), \(x_0 = \texttt = 2\), \(1 + x_0 = \texttt = 3\), \(1 + x_0 + x_2 = \texttt = 19\), and so forth. \(\texttt\) is, in this representation, 61779.Addition in binary fields is just XOR (and, incidentally, so is subtraction); note that this implies that \(x + x = 0\) for any \(x\). To multiply two elements \(x * y\), there's a pretty simple recursive algorithm: split each number into two halves:\(x = L_x + R_x * x_k\) \(y = L_y + R_y * x_k\)Then, split up the multiplication:\(x * y = (L_x * L_y) + (L_x * R_y) * x_k + (R_x * L_y) * x_k + (R_x * R_y) * x_k^2\)The last piece is the only slightly tricky one, because you have to apply the reduction rule, and replace \(R_x * R_y * x_k^2\) with \(R_x * R_y * (x_ * x_k + 1)\). There are more efficient ways to do multiplication, analogues of the Karatsuba algorithm and fast Fourier transforms, but I will leave it as an exercise to the interested reader to figure those out.Division in binary fields is done by combining multiplication and inversion: \(\frac = 3 * \frac\). The "simple but slow" way to do inversion is an application of generalized Fermat's little theorem: \(\frac = x^-2}\) for any \(k\) where \(2^ > x\). In this case, \(\frac = 5^ = 14\), and so \(\frac = 3 * 14 = 9\). There is also a more complicated but more efficient inversion algorithm, which you can find here. You can use the code here to play around with binary field addition, multiplication and division yourself. Left: addition table for four-bit binary field elements (ie. elements made up only of combinations of \(1\), \(x_0\), \(x_1\) and \(x_0x_1\)). Right: multiplication table for four-bit binary field elements. The beautiful thing about this type of binary field is that it combines some of the best parts of "regular" integers and modular arithmetic. Like regular integers, binary field elements are unbounded: you can keep extending as far as you want. But like modular arithmetic, if you do operations over values within a certain size limit, all of your answers also stay within the same bound. For example, if you take successive powers of \(42\), you get:\[1, 42, 199, 215, 245, 249, 180, 91...\]And after 255 steps, you get right back to \(42^ = 1\). And like both regular integers and modular arithmetic, they obey the usual laws of mathematics: \(a*b = b*a\), \(a * (b+c) = a*b + a*c\), and even some strange new laws, eg. \(a^2 + b^2 = (a+b)^2\) (the usual \(2ab\) term is missing, because in a binary field, \(1 + 1 = 0\)).And finally, binary fields work conveniently with bits: if you do math with numbers that fit into \(2^k\) bits, then all of your outputs will also fit into \(2^k\) bits. This avoids awkwardness like eg. with Ethereum's EIP-4844, where the individual "chunks" of a blob have to be numbers modulo 52435875175126190479447740508185965837690552500527637822603658699938581184513, and so encoding binary data involves throwing away a bit of space and doing extra checks at the application layer to make sure that each element is storing a value less than \(2^\). It also means that binary field arithmetic is super fast on computers - both CPUs, and theoretically optimal FPGA and ASIC designs.This all means that we can do things like the Reed-Solomon encoding that we did above, in a way that completely avoids integers "blowing up" like we saw in our example, and in a way that is extremely "native" to the kind of calculation that computers are good at. The "splitting" property of binary fields - how we were able to do \(\texttt = \texttt + \texttt * x_3\), and then keep splitting as little or as much as we wanted, is also crucial for enabling a lot of flexibility.Full BiniusSee here for a python implementation of this protocol.Now, we can get to "full Binius", which adjusts "simple Binius" to (i) work over binary fields, and (ii) let us commit to individual bits. This protocol is tricky to understand, because it keeps going back and forth between different ways of looking at a matrix of bits; it certainly took me longer to understand than it usually takes me to understand a cryptographic protocol. But once you understand binary fields, the good news is that there isn't any "harder math" that Binius depends on. This is not elliptic curve pairings, where there are deeper and deeper rabbit holes of algebraic geometry to go down; here, binary fields are all you need.Let's look again at the full diagram: By now, you should be familiar with most of the components. The idea of "flattening" a hypercube into a grid, the idea of computing a row combination and a column combination as tensor products of the evaluation point, and the idea of checking equivalence between "Reed-Solomon extending then computing the row combination", and "computing the row combination then Reed-Solomon extending", were all in simple Binius.What's new in "full Binius"? Basically three things:The individual values in the hypercube, and in the square, have to be bits (0 or 1) The extension process extends bits into more bits, by grouping bits into columns and temporarily pretending that they are larger field elements After the row combination step, there's an element-wise "decompose into bits" step, which converts the extension back into bits We will go through both in turn. First, the new extension procedure. A Reed-Solomon code has the fundamental limitation that if you are extending \(n\) values to \(k*n\) values, you need to be working in a field that has \(k*n\) different values that you can use as coordinates. With \(F_2\) (aka, bits), you cannot do that. And so what we do is, we "pack" adjacent \(F_2\) elements together into larger values. In the example here, we're packing two bits at a time into elements in \(\\), because our extension only has four evaluation points and so that's enough for us. In a "real" proof, we would probably back 16 bits at a time together. We then do the Reed-Solomon code over these packed values, and unpack them again into bits. Now, the row combination. To make "evaluate at a random point" checks cryptographically secure, we need that point to be sampled from a pretty large space, much larger than the hypercube itself. Hence, while the points within the hypercube are bits, evaluations outside the hypercube will be much larger. In our example above, the "row combination" ends up being \([11, 4, 6, 1]\).This presents a problem: we know how to combine pairs of bits into a larger value, and then do a Reed-Solomon extension on that, but how do you do the same to pairs of much larger values?The trick in Binius is to do it bitwise: we look at the individual bits of each value (eg. for what we labeled as "11", that's \([1, 1, 0, 1]\)), and then we extend row-wise. That is, we perform the extension procedure on the \(1\) row of each element, then on the \(x_0\) row, then on the "\(x_1\)" row, then on the \(x_0 * x_1\) row, and so forth (well, in our toy example we stop there, but in a real implementation we would go up to 128 rows (the last one being \(x_6 *\ ... *\ x_0\))).Recapping:We take the bits in the hypercube, and convert them into a grid Then, we treat adjacent groups of bits on each row as larger field elements, and do arithmetic on them to Reed-Solomon extend the rows Then, we take a row combination of each column of bits, and get a (for squares larger than 4x4, much smaller) column of bits for each row as the output Then, we look at the output as a matrix, and treat the bits of that as rows again Why does this work? In "normal" math, the ability to (often) do linear operations in either order and get the same result stops working if you start slicing a number up by digits. For example, if I start with the number 345, and I multiply it by 8 and then by 3, I get 8280, and if do those two operations in reverse, I also do 8280. But if I insert a "split by digit" operation in between the two steps, it breaks down: if you do 8x then 3x, you get:\[345 \xrightarrow 2760 \rightarrow [2, 7, 6, 0] \xrightarrow [6, 21, 18, 0]\]But if you do 3x then 8x, you get:\[345 \xrightarrow 1035 \rightarrow [1, 0, 3, 5] \xrightarrow [8, 0, 24, 40]\]But in binary fields built with the tower construction, this kind of thing does work. The reason why has to do with their separability: if you multiply a big value by a small value, what happens in each segment, stays in each segment. If we multiply \(\texttt\) by \(\texttt\), that's the same as first decomposing \(\texttt\) into \(\texttt + \texttt * x_2 + \texttt * x_2x_1 + \texttt * x_3 + \texttt * x_2x_3 + \texttt * x_1x_2x_3\), and then multiplying each component by \(\texttt\) separately.Putting it all togetherGenerally, zero knowledge proof systems work by making statements about polynomials that simultaneously represent statements about the underlying evaluations: just like we saw in the Fibonacci example, \(F(X+2) - F(X+1) - F(X) = Z(X) * H(X)\) simultaneously checks all steps of the Fibonacci computation. We check statements about polynomials by proving evaluations at a random point: given a commitment to \(F\), you might randomly choose eg. 1892470, demand proofs of evaluations of \(F\), \(Z\) and \(H\) at that point (and \(H\) at adjacent points), check those proofs, and then check if \(F(1892472) - F(1892471) - F(1892470)\) \(= Z(1892470) * H(1892470)\). This check at a random point stands in for checking the whole polynomial: if the polynomial equation doesn't match, the chance that it matches at a specific random coordinate is tiny.In practice, a major source of inefficiency comes from the fact that in real programs, most of the numbers we are working with are tiny: indices in for loops, True/False values, counters, and similar things. But when we "extend" the data using Reed-Solomon encoding to give it the redundancy needed to make Merkle proof-based checks safe, most of the "extra" values end up taking up the full size of a field, even if the original values are small.To get around this, we want to make the field as small as possible. Plonky2 brought us down from 256-bit numbers to 64-bit numbers, and then Plonky3 went further to 31 bits. But even this is sub-optimal. With binary fields, we can work over individual bits. This makes the encoding "dense": if your actual underlying data has n bits, then your encoding will have n bits, and the extension will have 8 * n bits, with no extra overhead.Now, let's look at the diagram a third time: In Binius, we are committing to a multilinear polynomial: a hypercube \(P(x_0, x_1 ... x_k)\), where the individual evaluations \(P(0, 0 ... 0)\), \(P(0, 0 ... 1)\) up to \(P(1, 1, ... 1)\) are holding the data that we care about. To prove an evaluation at a point, we "re-interpret" the same data as a square. We then extend each row, using Reed-Solomon encoding over groups of bits, to give the data the redundancy needed for random Merkle branch queries to be secure. We then compute a random linear combination of rows, with coefficients designed so that the new combined row actually holds the evaluation that we care about. Both this newly-created row (which get re-interpreted as 128 rows of bits), and a few randomly-selected columns with Merkle branches, get passed to the verifier. This is \(O(\sqrt)\) data: the new row has \(O(\sqrt)\) size, and each of the (constant number of) columns that get passed has \(O(\sqrt)\) size.The verifier then does a "row combination of the extension" (or rather, a few columns of the extension), and an "extension of the row combination", and verifies that the two match. They then compute a column combination, and check that it returns the value that the prover is claiming. And there's our proof system (or rather, the polynomial commitment scheme, which is the key building block of a proof system).What did we not cover?Efficient algorithms to extend the rows, which are needed to actually make the computational efficiency of the verifier \(O(\sqrt)\). With naive Lagrange interpolation, we can only get \(O(N^})\). For this, we use Fast Fourier transforms over binary fields, described here (though the exact implementation will be different, because this post uses a less efficient construction not based on recursive extension). Arithmetization. Univariate polynomials are convenient because you can do things like \(F(X+2) - F(X+1) - F(X) = Z(X) * H(X)\) to relate adjacent steps in the computation. In a hypercube, the interpretation of "the next step" is not nearly as clean as "\(X + 1\)". You can do \(X * k\) and jump around powers of \(k\), but this jumping around behavior would sacrifice many of the key advantages of Binius. The Binius paper introduces solutions to this (eg. see Section 4.3), but this is a "deep rabbit hole" in its own right. How to actually safely do specific-value checks. The Fibonacci example required checking key boundary conditions: \(F(0) = F(1) = 1\), and the value of \(F(100)\). But with "raw" Binius, checking at pre-known evaluation points is insecure. There are fairly simple ways to convert a known-evaluation check into an unknown-evaluation check, using what are called sum-check protocols; but we did not get into those here. Lookup protocols, another technology which has been recently gaining usage as a way to make ultra-efficient proving systems. Binius can be combined with lookup protocols for many applications. Going beyond square-root verification time. Square root is expensive: a Binius proof of \(2^\) bits is about 11 MB long. You can remedy this using some other proof system to make a "proof of a Binius proof", thus gaining both Binius's efficiency in proving the main statement and a small proof size. Another option is the much more complicated FRI-Binius protocol, which creates a poly-logarithmic-sized proof (like regular FRI). How Binius affects what counts as "SNARK-friendly". The basic summary is that, if you use Binius, you no longer need to care much about making computation "arithmetic-friendly": "regular" hashes are no longer more efficient than traditional arithmetic hashes, multiplication modulo \(2^\) or modulo \(2^\) is no longer a big headache compared to multiplication modulo \(p\), and so forth. But this is a complicated topic; lots of things change when everything is done in binary. I expect many more improvements in binary-field-based proving techniques in the months ahead.
-
Degen communism: the only correct political ideology Degen communism: the only correct political ideology2024 Apr 01 See all posts Degen communism: the only correct political ideology In 2024, there is a widespread feeling throughout the Western world that all of our political ideologies are outdated, and are increasingly failing us. Old ideas that have dominated elite political thought, whether capitalism or liberalism or progressive social democracy or whatever else, are rapidly losing popularity. The capitalists are supporting tariffs. The libertarians are pushing to ban lab-grown meat, and are actively railing against the few in their ranks who still remember that libertarianism is supposed to be about liberty. The "new authoritarians" of the world, meanwhile, are hardly presenting an attractive alternative.Some are trying to respond to this crisis by reminding us of the virtues of the old ideals of civility and decorum, hoping that we could wind back the clock and return to them. My friend Dennis Pourteaux is a good example of this kind of mentality: The problem is that this is a fundamentally reactionary mentality, and it fails for the exact same reasons why all other reactionary mentalities fail. If before we were at political equilibrium A, and today we are at political equilibrium B, then that alone is strong evidence that A is unstable, and even if you somehow force a transition back to A, the likely outcome is that we'll come right back to B again.As much as defenders of the ancien regime might wish otherwise, pre-internet old guard elite notions of respectability and decorum are simply fundamentally incompatible with the world as it stands in the 2020s. And so instead of trying to look backward, we need to look forward. So what is the forward-looking ideology that solves these problems? Degen communism.What is degen communism? What does the internet of the 2020s - not the "respectable" internet of Substack, not a hypothetical version of Twitter where the bad people and somehow only the bad people are censored, but the real internet as it exists today - fundamentally want? The answer is, it wants chaos. It does not want gentle debates between professionals who "disagree on policy but agree on civics". It wants decisive action and risk, in all its glory. Not a world with genteel respect for principles, where even the loser peacefully accepts defeat because they understand that even if they lose one day they may still win the next, but a world with great warriors who are willing to bet their entire life savings and reputation on one single move that reflects their deepest conviction on what things need to be done. And it wants a world where the brave have the freedom to take such risks.At the same time, the general welfare of humanity demands a greater focus on the common good. We've seen too many instances of epic collapses, orchestrated by failed machinations of the elites, where the common people end up screwed but the elites remain immune or even benefit. The 2008 financial crisis was itself an example of this. Rapid advances in technology, and rapid openings in immigration and trade, leave most people better off, but often leave jobless those who are not in a good position to adjust. Rapidly growing tech companies" disrupt" old extractive elites, but then quickly become extractive elites themselves. But most proponents of the common good associate the common good with extreme notions of "social stability", which are often an excuse for keeping old extractive elites entrenched, and in any case are lame and incompatible with the trends of the 21st century. Like the occasional forest fire and its positive effects on antifragility of natural ecosystems, chaos is the mother of revitalization and renewal.This brings me to the core idea of degen communism: a political ideology that openly embraces chaos, but tweaks key rules and incentives to create a background pressure where the consequences of chaos are aligned with the common good.Degen communist ideas can be adopted by any type of entity with a network effect: crypto projects, social media sites, virtual game environments and governments. Many of the core ideas are common across all of these categories.Cryptocurrency: the avant garde in degen. Can it become degen communist?The world of cryptocurrencies is one of the sectors of society that embraces the "degen" the most. It has ups and downs that are unseen in almost any other market. Meanwhile, the actual effects of the downs are often smaller than they seem, which is why the space has not collapsed completely. A 90% price drop erases billions of dollars of value, but the average dollar lost is only lost in mark-to-market book-value terms: it's people to held on the way up, and kept holding on the way down. The average coin lost from a $100 million defi hack is a coin that was worth ten times less two years earlier. Sometimes, the unpredictable chaos also does good: many memecoins have donated significant amounts to charity.But even still, when the prices crash, especially due to sudden failures of projects that promised their users stability, too many people get hurt. Could we create a world where the chaos remains, but the human harm that comes from the downfalls is 10x smaller? Here, I will resurrect an idea that I supported during the Terra/Luna collapse of 2022: When projects collapse or get hacked, and only partial refunds are possible, don't make the refunds proportional. Instead, make smaller users whole first, up to some threshold (eg. $50k). Two years ago, when I proposed this idea, many treated it with scorn, misrepresenting the idea as asking for government bailouts. Today, nobody seems to care about principles anymore, and so even versions of this idea that are government-backed can perhaps more easily get adopted. Here, though, I am not proposing anything to do with governments; rather, I am proposing that project teams put into their terms of service an expectation that in the event of project insolvency, partial refunds will be prioritized in this way. The only request to governments is that appropriate rules get passed so that bankruptcy courts acknowledge the legitimacy of such arrangements.This mitigates the downsides of chaos toward the most vulnerable. Now, what about better capturing the upsides of chaos? Here, I support a combination of steps:Memecoins and games can donate a portion of their issuance to charity. Projects can use airdrops that try their best to distribute the most to individual users, as well as public good contributors such as open source software developers, solo stakers, etc. The Starknet airdrop was an excellent demonstration of this, as were other egalitarian airdrops like the ENS airdrop. Projects can have public goods funding programs (whether proactive or retroactive). The first three rounds of optimism retro funding were an excellent example; more projects should replicate this model. If a governance token gets too concentrated, and the concentrated players make bad decisions, the community should be more willing to fork the project and zero out the tokens of the concentrated players who made the bad decisions. This was done most successfully in the Hive fork of Steem. Many of these ideas, especially those that depend on some notion of "per-person", would have been very difficult to reliably administer in 2019. In 2024, however, we have more and more robust proof of personhood protocols, proofs of community participation such as POAPs, and reusable lists such as Starkware's list of solo stakers that they used for their airdrop. Hence, a degen communist future for crypto is very possible. The solution is to merge the two together. Keep the base instinct, especially the base instinct of enjoying watching things blow up, but tilt it toward the common good. In exchange, the base instinct people can enjoy greater legitimacy.Incidentally, maybe this is why that L2 is called "Base". What might degen communism look like in government policy?The two main forms of chaos in the broader world are social media and markets. Rather than trying to defang both, we should embrace both (especially markets), and try to tilt them toward more often serving the common good. Politics is inherently a more slow-moving domain, so the proposals will seem 10x milder. However, the increased scale of their impact more than makes up for it.Land value taxes and YIMBY Today, real estate markets in many parts of the developed world are in crisis. In the most expensive regions, wealthy landowners earn millions by simply holding on to pieces of real estate that they acquired at dirt-cheap prices more than half a century ago. Rules like California's Proposition 13 mean that they only have to pay property taxes calculated as though their plot still had a much lower price. At the same time, many of these same people push to maintain restrictive regulations that prevent more dense housing from being built. This is a society that favors the rich. Traditional leftists' favorite countermeasure, rent control rules, only benefit people who stay in the same place for many years, at the expense of very long waits for new people who want to come in. Meanwhile, governments' ability to raise revenue to fund public services is limited by the fact that if income and sales taxes are pushed too high, people simply go somewhere else.This status quo is the exact opposite of degen, and the opposite of communist. And so a degen communist will seek to overturn all parts of it. Instead of focusing on taxing income and business, which can flee a state or country that taxes it too heavily, we would put the primary tax burden on land, which cannot. Land value taxes, a yearly property tax proportional on the value of land (but not the buildings on the land), have been broadly supported by many economists for over a century. We can add per-person exemptions, limiting the effects of the tax on the most vulnerable: if we send half the entire revenue from a land value tax directly into a per-person dividend, then anyone who owns less than half the average amount of land (ie. almost all poor people) would net-benefit!This could be viewed as a market-based tax plus a dividend, or it can be viewed as a rationing scheme, where if you own less land than your quota you can get a reward by renting your excess quota to people who own more.A degen communist would also repeal restrictive rules that heavily limit what can be built on the land, allowing much more construction to take place. There are already places in the world that follow something close to this approach: much of East Asia and, surprisingly, Austin, Texas. Austin skyline, 2014 vs 2023. Housing supply growth in Austin is fast, and rents are dropping. Texas does not have a land value tax, but it has high property taxes: 1.77% per year, compared to 0.7% per year in much of California. Texas taxes its rich - but it taxes their land, not their income. And it taxes stasis, rather than dynamism, and in doing so it makes itself more affordable to the poor.Many today are suffering from high prices - so let's drop the prices we can drop (most notably, rent) with a few simple policy changes.Harberger taxes on intellectual propertySo-called "intellectual property" (ie. copyrights and patents) is one of the most elite-controlled forms of "property" around, and one of the forms of government regulation most harmful to dynamism. On the other hand, many are concerned that removing intellectual property entirely would overly harm the incentive to innovate and make artistic works. To strike a balance, I propose a happy medium: we keep copyrights and patents, but put Harberger taxes on them.This would work as follows. For a copyright or patent to be valid, whoever owns it must publicly register a value, which we will call that copyright or patent's "exclusivity price". They must then pay 2% of the exclusivity price annually in tax (they can change the exclusivity price at any time). Anyone can pay the owner the exclusivity price, and get an unlimited right to also use (and if they wish sub-license, including to the entire world) that copyright or patent. The original owner would retain the right to use in all cases; others can gain permission to use either by getting the original owner's permission, or by paying the owner the exclusivity price.This accomplishes two goals. First, it fixes defaults: if someone has no interest in making money off of keeping an invention or work exclusive, it sets the default so that it's publicly available for anyone. Second, it leads to more permissionlessness, and less exclusion, on the margin, by putting a price on exclusion. The revenues from this tax could go into a citizen's dividend, or they could go into a quadratic funding pool that supports non-profit science and art.Immigration Left: the US standard immigration system. Backlogged and unfair. Right: the US alternative immigration system. Honest and fair. One of the most beautiful and deeply good ideas in early communism is the internationalism: the focus on "workers of the world uniting" and songs like The Internationale. In 2024, we are unfortunately in an age of rising nationalism, where it's considered normal for each nation to only care about each own citizens, at the expense of people unlucky enough to be born outside. Faced with these restrictions, some are taking matters into their own hands, making their way into wealthy countries the old-fashioned way - the way that pretty much everyone did up until globalist schemes of social control like passports were introduced about a century ago.A degen communist would embrace dynamism and change, especially when it seems like such dynamism and change might benefit the global poor more than anyone else. Degen communists would greatly expand safe and legal pathways for people to visit and live where they want to visit and live, trusting in liberalized housing construction, plus governments made wealthy by taxes from such construction, to build needed infrastructure for them. Restrictions would be focused on keeping out particularly risky or bad actors, rather than keeping out almost everyone. A "proof of stake" scheme could be adopted where someone can put down funds (or the right to make future invitations) at stake on a claim that a given person will not break any rules, which would then give that person an automatic right to enter. Security can be improved while total freedom of movement is increased.Decision-making in degen communismDecision-making in degen communist institutions would be democratic, and would follow three equally important principles: dynamism, cross-tribal bridging and quality. Decisions could be made quickly, using algorithms that identify ideas that are held in common across groups which normally disagree with each other, and which elevate quality without entrenching a fixed set of elites.This involves a two-layer stack:Public discussion and consensus-finding platforms, which can allow large groups of people to rapidly participate but include mechanisms to identify points of consensus. This includes tools such as pol.is and Community Notes, which focus on cross-tribal bridging. It also includes prediction markets (eg. Polymarket), which in addition to helping communities surface good predictions, serve the role of giving intellectuals an outlet to express their conviction about their strongest and most fervent beliefs - and for others to bet against them. The final governance mechanism (eg. voting). This can use quadratic voting, though the "cross-tribal bridging" functionality can be enhanced by ideas like the matrix-factoring algorithm in Community Notes or by pairwise-bounded quadratic voting. These two sets of tools together allow decisions to be made quickly, at large scale, and in a way that favors quality in a dynamic way that allows experts to quickly rise and fall with each individual topic or decision.In all of these possible implementations, the core theme of degen communism is the same. Do not try to enforce stasis. Instead, embrace the chaos of markets and other fast-paced human activity. At the same time, however, tweak rules in such a way that the upsides get funneled into supporting public goods (including quality of the governance itself), and the downsides get capped or even outright removed for the people who are not able to handle it. This can be a way forward for everyone in the 21st century.
-
What else could memecoins be? What else could memecoins be?2024 Mar 29 See all posts What else could memecoins be? Ten years ago, two weeks before the Ethereum project was publicly announced, I published this post on Bitcoin magazine arguing that issuing coins could be a new way to fund important public projects. The thinking went: society needs ways to fund valuable large-scale projects, markets and institutions (both corporations and governments) are the main techniques that we have today, and both work in some cases and fail in others. Issuing new coins seems like a third class of large-scale funding technology, and it seems different enough from both markets and institutions that it would succeed and fail in different places - and so it could fill in some important gaps. People who care about cancer research could hold, accept and trade AntiCancerCoin; people who care about saving the environment would hold and use ClimateCoin, and so forth. The coins that people choose to use would determine what causes get funded.Today in 2024, a major topic of discussion in "the crypto space" appears to be memecoins. We have seen memecoins before, starting from Dogecoin back in 2015, and "dog coins" were a major topic during the 2020-21 season. This time, they are heating up again, but in a way that is making many people feel uneasy, because there isn't anything particularly new and interesting about the memecoins. In fact, often quite the opposite: apparently a bunch of Solana memecoins have recently been openly super-racist. And even the non-racist memecoins often seem to just go up and down in price and contribute nothing of value in their wake.And people are upset: Even long-time Ethereum philosopher Polynya is very very unhappy: One answer to this conundrum is to shake our heads and virtue-signal about how much we are utterly abhorred by and stand against this stupidity. And to some extent, this is the correct thing to do. But at the same time, we can also ask another question: if people value having fun, and financialized games seem to at least sometimes provide that, then could there be a more positive-sum version of this whole concept?Charity coinsAmong the more interesting of the coins that I've seen are coins where a large portion of the token supply (or some ongoing fee mechanism) is dedicated to some kind of charity. One and a half years ago, there was a (no longer active) coin called "GiveWell Inu" that donated proceeds to GiveWell. For the past two years, there has been a coin called "Fable of the Dragon Tyrant" which supported cultural projects related to anti-aging research, in addition to other causes. Unfortunately, both of these are far from perfect: GiveWell Inu seems to no longer be maintained, and the other one has some highly annoying core community members that constantly badger me for attention, which currently makes me unenthusiastic about mentioning them more than once. More successfully, after I was gifted half the supply of the Dogelon Mars token, and immediately re-gifted it to the Methuselah Foundation, the Methuselah Foundation and the Dogelon Mars community seemed to develop a positive-sum relationship with each other, retroactively converting $ELON into a charity coin.It feels like there is an unclaimed opportunity here to try to create something more positive-sum and long-lasting. But ultimately, I think even that would create something fundamentally limited, and we can do better.Robin Hood gamesIn principle, people participate in memecoins because (i) the value might go up, (ii) they feel democratic and open for anyone to participate, and (iii) they are fun. We can siphon off a large percent of a memecoin's supply to support public goods that people value, but that does nothing for the participants directly, and indeed comes at the expense of (i), and if done poorly at the expense of (ii) too. Can we do something that instead improves on both for the average user?The answer for (iii) is simple: don't just make a coin, make a game. But make an actually meaningful and fun game. Don't think Candy Crush on the blockchain; think World of Warcraft on the blockchain. An "Ethereum Researcher" in World of Warcraft. If you kill one, you get 15 silver 61 copper, and a 0.16% chance of getting some "Ethereum Relay Data". Do not attempt in real life. Now, what about the Robin Hood part? When I go around low-income Southeast Asian countries, one claim that I often hear is how some people or their family members were poor before, but then got medium-rich off of the play-to-earn feature in Axie Infinity in 2021. Of course, Axie Infinity's situation in 2022 was somewhat less favorable. But even still, I get the impression that if you take the game's play-to-earn properties into account, on average, the net financial gains were negative for high-income users but might (emphasis on might!) have been positive for low-income users. This seems like a nice property to have: if you have to be financially brutal on someone, be brutal on those who can handle it, but have a safety net to keep lower-income users protected and even try to make them come out better off than they came in.Regardless of how well Axie Infinity in particular accomplished this, it feels intuitive that (i) if the goal is to satisfy people's desire to have fun, we should be making not simple copy-paste coins but rather more complicated and interesting games, and (ii) games that leave lower-income players in particular economically better off are more likely to leave their communities better than they came in. Charity coins and games could even be combined: one of the features of the game could be a mechanism where players who succeed at some task can participate in voting on which charities the issued funds are distributed to.That said, making a genuinely fun game is a challenge - see some negative takes on how well Axie did at being fun, and this positive take on how they have improved since then. The team that I personally have the most confidence in to make fun crypto games is 0xPARC, because they have already succeeded twice (!!) at making crypto games (first Dark Forest, then FrogCrypto) where players were willing to play entirely for fun, rather than out of a desire to make money. Ideally, the goal is to make a co-created environment that leaves all players happy: money is zero sum, but fun can be positive sum.ConclusionsOne of my personal moral rules is "if there is a class of people or groups you dislike, be willing to praise at least a few of them that do the best job of satisfying your values". If you dislike governments because they violate people's freedoms, perhaps you may find space in your heart to say something good about the Swiss one. If you dislike social media platforms for being extractive and encouraging toxic behavior, but you think Reddit is 2x less bad, say nice things about Reddit. The opposite approach - to shout "yes, all X are part of the problem" - feels good in the moment, but it alienates people and pushes them further toward their own bubble where they will insulate themselves entirely from any moral appeals you might have in the future.I think of the "degen" parts of the crypto space in the same way. I have zero enthusiasm for coins named after totalitarian political movements, scams, rugpulls or anything that feels exciting in month N but leaves everyone upset in month N+1. At the same time, I value people's desire to have fun, and I would rather the crypto space somehow swim with this current rather than against it. And so I want to see higher quality fun projects that contribute positively to the ecosystem and the world around them (and not just by "bringing in users") get more mindshare. At the least, more good memecoins than bad ones, ideally those that support public goods instead of just enriching insiders and creators. But also ideally, making games rather than coins, and making projects that people enjoy participating in.
-
Ethereum has blobs. Where do we go from here? Ethereum has blobs. Where do we go from here?2024 Mar 28 See all posts Ethereum has blobs. Where do we go from here? On March 13, the Dencun hard fork activated, enabling one of the long-awaited features of Ethereum: proto-danksharding (aka EIP-4844, aka blobs). Initially, the fork reduced the transaction fees of rollups by a factor of over 100, as blobs were nearly free. In the last day, we finally saw blobs spike up in volume and the fee market activate as the blobscriptions protocol started to use them. Blobs are not free, but they remain much cheaper than calldata. Left: blob usage finally spiking up to the 3-per-block target thanks to Blobscriptions. RIght: blob fees "entering price discovery mode" as a result. Source: https://dune.com/0xRob/blobs. This milestone represents a key transition in Ethereum's long-term roadmap: blobs are the moment where Ethereum scaling ceased to be a "zero-to-one" problem, and became a "one-to-N" problem. From here, important scaling work, both in increasing blob count and in improving rollups' ability to make the best use of each blob, will continue to take place, but it will be more incremental. The scaling-related changes to the fundamental paradigm of how Ethereum as an ecosystem operates are increasingly already behind us. Additionally, emphasis is already slowly shifting, and will continue to slowly shift, from L1 problems such as PoS and scaling, to problems closer to the application layer. The key question that this post will cover is: where does Ethereum go from here?The future of Ethereum scalingOver the last few years, we have seen Ethereum slowly shift over to becoming an L2-centric ecosystem. Major applications have started to move over from L1 to L2, payments are starting to be L2-based by default, and wallets are starting to build their user experience around the new multi-L2 environment.From the very beginning, a key piece of the rollup-centric roadmap was the idea of separate data availability space: a special section of space in a block, which the EVM would not have access to, that could hold data for layer-2 projects such as rollups. Because this data space is not EVM-accessible, it can be broadcasted separately from a block and verified separately from a block. Eventually, it can be verified with a technology called data availability sampling, which allows each node to verify that the data was correctly published by only randomly checking a few small samples. Once this is implemented, the blob space could be greatly expanded; the eventual goal is 16 MB per slot (~1.33 MB per second). Data availability sampling: each node only needs to download a small portion of the data to verify the availability of the whole thing. EIP-4844 (aka "blobs") does not give us data availability sampling. But it does set up the basic scaffolding in such a way that from here on, data availability sampling can be introduced and blob count can be increased behind the scenes, all without any involvement from users or applications. In fact, the only "hard fork" required is a simple parameter change.There are two strands of development that will need to continue from here:Progressively increasing blob capacity, eventually bringing to life the full vision of data availability sampling with 16 MB per slot of data space Improving L2s to make better use of the data space that we have Bringing DAS to lifeThe next stage is likely to be a simplified version of DAS called PeerDAS. In PeerDAS, each node stores a significant fraction (eg. 1/8) of all blob data, and nodes maintain connections to many peers in the p2p network. When a node needs to sample for a particular piece of data, it asks one of the peers that it knows is responsible for storing that piece. If each node needs to download and store 1/8 of all data, then PeerDAS lets us theoretically scale blobs by 8x (well, actually 4x, because we lose 2x to the redundancy of erasure coding). PeerDAS can be rolled out over time: we can have a stage where professional stakers continue downloading full blobs, and solo stakers only download 1/8 of the data.In addition to this, EIP-7623 (or alternatives such as 2D pricing) can be used to put stricter bounds on the maximum size of an execution block (ie. the "regular transactions" in a block), which makes it safer to increase both the blob target and the L1 gas limit. In the longer term, more complicated 2D DAS protocols will let us go all the way and increase blob space further.Improving L2sThere are four key places in which layer 2 protocols today can improve.1. Using bytes more efficiently with data compression My outline-in-a-picture of data compression continues to be available here;Naively, a transaction takes up around 180 bytes of data. However, there are a series of compression techniques that can be used to bring this size down over several stages; with optimal compression we could potentially go all the way down to under 25 bytes per transaction.2. Optimistic data techniques that secure L2s by only using the L1 in exceptional situations Plasma is a category of techniques that allows you to get rollup-equivalent security for some applications while keeping data on L2 in the normal case. For EVMs, plasma can't protect all coins. But Plasma-inspired constructions can protect most coins. And constructions much simpler than Plasma can improve greatly on the validiums of today. L2s that are not willing to put all of their data on-chain should explore such techniques.3. Continue improving on execution-related constraintsOnce the Dencun hard fork activated, making rollups set up to use the blobs that it introduced 100x cheaper. usage on the Base rollup spiked up immediately: This in turn led to Base hitting its own internal gas limit, causing fees to unexpectedly surge. This has led to a more widespread realization that Ethereum data space is not the only thing that needs to be scaled: rollups need to be scaled internally as well.Part of this is parallelization; rollups could implement something like EIP-648. But just as important is storage, and interaction effects between compute and storage. This is an important engineering challenge for rollups.4. Continue improving securityWe are still far from a world where rollups are truly protected by code. In fact, according to l2beat only these five, of which only Arbitrum is full-EVM, have even reached what I have called "stage 1". This needs to be tackled head-on. While we are not currently at the point where we can be confident enough in the complex code of an optimistic or SNARK-based EVM verifier, we are absolutely at the point where we can go halfway there, and have security councils that can revert the behavior of the code only with a high threshold (eg. I proposed 6-of-8; Arbitrum is doing 9-of-12).The ecosystem's standards need to become stricter: so far, we have been lenient and accepted any project as long as it claims to be "on a path to decentralization". By the end of the year, I think our standards should increase and we should only treat a project as a rollup if it has actually reached at least stage 1.After this, we can cautiously move toward stage 2: a world where rollups truly are backed by code, and a security council can only intervene if the code "provably disagrees with itself" (eg. accepts two incompatible state roots, or two different implementations give different answers). One path toward doing this safely is to use multiple prover implementations.What does this mean for Ethereum development more broadly?In a presentation at ETHCC in summer 2022, I made a presentation describing the current state of Ethereum development as an S-curve: we are entering a period of very rapid transition, and after that rapid transition, development will once again slow down as the L1 solidifies and development re-focuses on the user and application layer. Today, I would argue that we are decidedly on the decelerating, right side of this S-curve. As of two weeks ago, the two largest changes to the Ethereum blockchain - the switch to proof of stake, and the re-architecting to blobs - are behind us. Further changes are still significant (eg. Verkle trees, single-slot finality, in-protocol account abstraction), but they are not drastic to the same extent that proof of stake and sharding are. In 2022, Ethereum was like a plane replacing its engines mid-flight. In 2023, it was replacing its wings. The Verkle tree transition is the main remaining truly significant one (and we already have testnets for that); the others are more like replacing a tail fin.The goal of EIP-4844 was to make a single large one-time change, in order to set rollups up for long-term stability. Now that blobs are out, a future upgrade to full danksharding with 16 MB blobs, and even switching the cryptography over to STARKs over a 64-bit goldilocks field, can happen without requiring any further action from rollups and users. It also reinforces an important precedent: that the Ethereum development process executes according to a long-existing well-understood roadmap, and applications (including L2s) that are built with "the new Ethereum" in mind get an environment that is stable for the long term.What does this mean for applications and users?The first ten years of Ethereum have largely been a training stage: the goal has been to get the Ethereum L1 off the ground, and applications have largely been happening within a small cohort of enthusiasts. Many have argued that the lack of large-scale applications for the past ten years proves that crypto is useless. I have always argued against this: pretty much every crypto application that is not financial speculation depends on low fees - and so while we have high fees, we should not be surprised that we mainly see financial speculation!Now that we have blobs, this key constraint that has been holding us back all this time is starting to melt away. Fees are finally much lower; my statement from seven years ago that the internet of money should not cost more than five cents per transaction is finally coming true. We are not entirely out of the woods: fees may still increase if usage grows too quickly, and we need to continue working hard to scale blobs (and separately scale rollups) further over the next few years. But we are seeing the light at the end of the... err..... dark forest. What this means to developers is simple: we no longer have any excuse. Up until a couple of years ago, we were setting ourselves a low standard, building applications that were clearly not usable at scale, as long as they worked as prototypes and were reasonably decentralized. Today, we have all the tools we'll need, and indeed most of the tools we'll ever have, to build applications that are simultaneously cypherpunk and user-friendly. And so we should go out and do it.Many are rising to the challenge. The Daimo wallet is explicitly describing itself as Venmo on Ethereum, aiming to combine Venmo's convenience with Ethereum's decentralization. In the decentralized social sphere, Farcaster is doing a good job of combining genuine decentralization (eg. see this guide on how to build your own alternative client) with excellent user experience. Unlike the previous hype waves of "social fi", the average Farcaster user is not there to gamble - passing the key test for a crypto application to truly be sustainable. This post was sent on the main Farcaster client, Warpcast, and this screenshot was taken from the alternative Farcaster + Lens client Firefly. These are successes that we need to build on, and expand to other application spheres, including identity, reputation and governance.Applications built or maintained today should be designed with 2020s Ethereum in mindThe Ethereum ecosystem still has a large number of applications that operate around a fundamentally "2010s Ethereum" workflow. Most ENS activity is still on layer 1. Most token issuance happens on layer 1, without serious consideration to making sure that bridged tokens on layer 2s are available (eg. see this fan of the ZELENSKYY memecoin appreciating the coin's ongoing donations to Ukraine but complaining that L1 fees make it too expensive). In addition to scalability, we are also behind on privacy: POAPs are all publicly on-chain, probably the right choice for some use cases but very suboptimal for others. Most DAOs, and Gitcoin Grants, still use fully transparent on-chain voting, making them highly vulnerable to bribery (including retroactive airdrops), and this has been shown to heavily distort contribution patterns. Today, ZK-SNARKs have existed for years, and yet many applications still have not even started to properly use them.These are all hard-working teams that have to handle large existing user bases, and so I do not fault them for not simultaneously upgrading to the latest wave of technology. But soon, this upgrading needs to happen. Here are some key differences between "a fundamentally 2010s Ethereum workflow" and "a fundamentally 2020s Ethereum workflow": 2010s Ethereum 2020s Ethereum Architecture Build everything on L1 Build on a specific L2, or architect the application so that it supports every L2 that follows some standards Privacy Everything public A user's data is private by default, users merkle-prove or ZK-prove specific claims as needed to establish trust Anti-sybil You must have 0.01 ETH Application can require an ETH deposit, but clients should offer wrappers for non-crypto users that provide "centralized anti-sybil" (eg. SMS) Wallets EOAs Account abstraction wallets: key recovery, different access control for different security levels, sponsored txs... Proof of community membership (for voting, airdrops...) Based on how much ETH you have ETH + proof of personhood + POAPs + ZuStamps + EAS + third party curated lists (eg. Starknet's solo staker list) Basically, Ethereum is no longer just a financial ecosystem. It's a full-stack replacement for large parts of "centralized tech", and even provides some things that centralized tech does not (eg. governance-related applications). And we need to build with this broader ecosystem in mind.ConclusionsEthereum is in the process of a decisive shift from a "very rapid L1 progress" era to an era where L1 progress will be still very significant, but somewhat more mellow, and less disruptive to applications. We still need to finish scaling. This work will be more in-the-background, but it remains important. Application developers are no longer building prototypes; we are building tools for many millions of people to use. Across the ecosystem, we need to fully readjust mindsets accordingly. Ethereum has upgraded from being "just" a financial ecosystem into a much more thorough independent decentralized tech stack. Across the ecosystem, we need to fully readjust mindsets accordingly to this too.
-
Ask security questions Ask security questions2024 Feb 09 See all posts Ask security questions Special thanks to Hudson Jameson, OfficerCIA and samczsun for feedback and review.Over the past week, an article has been floating around about a company that lost $25 million when a finance worker was convinced to send a bank wire to a scammer pretending to be the CFO... over what appears to have been a very convincing deepfaked video call. Deepfakes (ie. AI-generated fake audio and video) are appearing increasingly often both in the crypto space and elsewhere. Over the past few months, deepfakes of me have been used to advertise all kinds of scams, as well as dog coins. The quality of the deepfakes is rapidly improving: while the deepfakes of 2020 were embarrassingly obvious and bad, those from the last few months are getting increasingly difficult to distinguish. Someone who knows me well could still identify the recent video of me shilling a dog coin as a fake because it has me saying "let's f***ing go" whereas I've only ever used "LFG" to mean "looking for group", but people who have only heard my voice a few times could easily be convinced.Security experts to whom I mentioned the above $25 million theft uniformly confirm that it was an exceptional and embarrassing failure of enterprise operational security on multiple levels: standard practice is to require several levels of sign-off before a transfer anywhere close to that size can be approved. But even still, the fact remains that as of 2024, an audio or even video stream of a person is no longer a secure way of authenticating who they are.This raises the question: what is?Cryptographic methods alone are not the answerBeing able to securely authenticate people is valuable to all kinds of people in all kinds of situations: individuals recovering their social recovery or multisig wallets, enterprises approving business transactions, individuals approving large transactions for personal use (eg. to invest into a startup, buy a house, send remittances) whether with crypto or with fiat, and even family members needing to authenticate each other in emergencies. So it's really important to have a good solution that can survive the coming era of relatively easy deepfakes.One answer to this question that I often hear in crypto circles is: "you can authenticate yourself by providing a cryptographic signature from an address attached to your ENS / proof of humanity profile / public PGP key". This is an appealing answer. However, it completely misses the point of why involving other people when signing off on transactions is useful in the first place. Suppose that you are an individual with a personal multisig wallet, and you are sending off a transaction that you want some co-signers to approve. Under what circumstances would they approve it? If they're confident that you're the one who actually wants the transfer to happen. If it's a hacker who stole your key, or a kidnapper, they would not approve. In an enterprise context, you generally have more layers of defense; but even still, an attacker could potentially impersonate a manager not just for the final request, but also for the earlier stages in the approval process. They may even hijack a legitimate request-in-progress by providing the wrong address.And so in many cases, the other signers accepting that you are you if you sign with your key kills the whole point: it turns the entire contract into a 1-of-1 multisig where someone needs to only grab control of your single key in order to steal the funds!This is where we get to one answer that actually makes some sense: security questions.Security questionsSuppose that someone texts you claiming to be a particular person who is your friend. They are texting from an account you have never seen before, and they are claiming to have lost all of their devices. How do you determine if they are who they say they are?There's an obvious answer: ask them things that only they would know about their life. These should be things that:You know You expect them to remember The internet does not know Are difficult to guess Ideally, even someone who has hacked corporate and government databases does not know The natural thing to ask them about is shared experiences. Possible examples include:When the two of us last saw each other, what restaurant did we eat at for dinner, and what food did you have? Which of our friends made that joke about an ancient politician? And which politician was it? Which movie did we recently watch that you did not like? You suggested last week that I chat with ____ about the possibility of them helping us with ____ research? Actual example of a security question that someone recently used to authenticate me. The more unique your question is, the better. Questions that are right on the edge where someone has to think for a few seconds and might even forget the answer are good: but if the person you're asking does claim to have forgotten, make sure to ask them three more questions. Asking about "micro" details (what someone liked or disliked, specific jokes, etc) is often better than "macro" details, because the former are generally much more difficult for third parties to accidentally be able to dig up (eg. if even one person posted a photo of the dinner on Instagram, modern LLMs may well be fast enough to catch that and provide the location in real time). If your question is potentially guessable (in the sense that there are only a few potential options that make sense), stack up the entropy by adding another question.People will often stop engaging in security practices if they are dull and boring, so it's healthy to make security questions fun! They can be a way to remember positive shared experiences. And they can be an incentive to actually have those experiences in the first place.Complements to security questionsNo single security strategy is perfect, and so it's always best to stack together multiple techniques.Pre-agreed code words: when you're together, intentionally agree on a shared code word that you can later use to authenticate each other. Perhaps even agree on a duress key: a word that you can innocently insert into a sentence that will quietly signal to the other side that you're being coerced or threatened. This word should be common enough that it will feel natural when you use it, but rare enough that you won't accidentally insert it into your speech. When someone is sending you an ETH address, ask them to confirm it on multiple channels (eg. Signal and Twitter DM, on the company website, or even through a mutual acquaintance) Guard against man-in-the-middle attacks: Signal "safety numbers", Telegram emojis and similar features are all good to understand and watch out for. Daily limits and delays: simply impose delays on highly consequential and irreversible actions. This can be done either at policy level (pre-agree with signers that they will wait for N hours or days before signing) or at code level (impose limits and delays in smart contract code) A potential sophisticated attack where an attacker impersonates an executive and a grantee at multiple steps of an approval process. Security questions and delays can both guard against this; it's probably better to use both. Security questions are nice because, unlike so many other techniques that fail because they are not human-friendly, security questions build off of information that human beings are naturally good at remembering. I have used security questions for years, and it is a habit that actually feels very natural and not awkward, and is worth including into your workflow - in addition to your other layers of protection.Note that "individual-to-individual" security questions as described above are a very different use case from "enterprise-to-individual" security questions, such as when you call your bank to reactivate your credit card after it got deactivated for the 17th time after you travel to a different country, and once you get past the 40-minute queue of annoying music a bank employee appears and asks you for your name, your birthday and maybe your last three transactions. The kinds of questions that an individual knows the answers to are very different from what an enterprise knows the answers to. Hence, it's worth thinking about these two cases quite separately.Each person's situation is unique, and so the kinds of unique shared information that you have with the people you might need to authenticate with differs for different people. It's generally better to adapt the technique to the people, and not the people to the technique. A technique does not need to be perfect to work: the ideal approach is to stack together multiple techniques at the same time, and choose the techniques that work best for you. In a post-deepfake world, we do need to adapt our strategies to the new reality of what is now easy to fake and what remains difficult to fake, but as long as we do, staying secure continues to be quite possible.
-
The end of my childhood The end of my childhood2024 Jan 31 See all posts The end of my childhood One of my most striking memories from my last two years was speaking at hackathons, visiting hacker houses, and doing Zuzalu in Montenegro, and seeing people a full decade younger than myself taking on leading roles, as organizers or as developers, in all kinds of projects: crypto auditing, Ethereum layer 2 scaling, synthetic biology and more. One of the memes of the core organizing team at Zuzalu was the 21-year-old Nicole Sun, and a year earlier she had invited me to visit a hacker house in South Korea: a ~30-person gathering where, for the first time that I can recall, I was by a significant margin the oldest person in the room.When I was as old as those hacker house residents are now, I remember lots of people lavishing me with praise for being one of these fancy young wunderkinds transforming the world like Zuckerberg and so on. I winced at this somewhat, both because I did not enjoy that kind of attention and because I did not understand why people had to translate "wonder kid" into German when it works perfectly fine in English. But watching all of these people go further than I did, younger than I did, made me clearly realize that if that was ever my role, it is no longer. I am now in some different kind of role, and it is time for the next generation to take up the mantle that used to be mine. The path leading up to the hacker house in Seoul, August 2022. Photo'd because I couldn't tell which house I was supposed to be entering and I was communicating with the organizers to get that information. Of course, the house ended up not being on this path at all, but rather in a much more visible venue about twenty meters to the right of it. 1As a proponent of life extension (meaning, doing the medical research to ensure that humans can literally live thousands or millions of years), people often ask me: isn't the meaning of life closely tied to the fact that it's finite: you only have a small bit, so you have to enjoy it? Historically, my instinct has been to dismiss this idea: while is it true as a matter of psychology that we tend to value things more if they are limited or scarce, it's simply absurd to argue that the ennui of a great prolonged existence could be so bad that it's worse than literally no longer existing. Besides, I would sometimes think, even if eternal life proved to be that bad, we could always simultaneously dial up our "excitement" and dial down our longevity by simply choosing to hold more wars. The fact that the non-sociopathic among us reject that option today strongly suggests to me that we would reject it for biological death and suffering as well, as soon as it becomes a practical option to do so.As I have gained more years, however, I realized that I do not even need to argue any of this. Regardless of whether our lives as a whole are finite or infinite, every single beautiful thing in our lives is finite. Friendships that you thought are forever turn out to slowly fade away into the mists of time. Your personality can completely change in 10 years. Cities can transform completely, for better or sometimes for worse. You may move to a new city yourself, and restart the process of getting acquainted with your physical environment from scratch. Political ideologies are finite: you may build up an entire identity around your views on top marginal tax rates and public health care, and ten years later feel completely lost once people seem to completely stop caring about those topics and switch over to spending their whole time talking about "wokeness", the "Bronze Age mindset" and "e/acc".A person's identity is always tied to their role in the broader world that they are operating in, and over a decade, not only does a person change, but so does the world around them. One change in my thinking that I have written about before is how my thinking involves less economics than it did ten years ago. The main cause of this shift is that I spent a significant part of the first five years of my crypto life trying to invent the mathematically provably optimal governance mechanism, and eventually I discovered some fundamental impossibility results that made it clear to me that (i) what I was looking for was impossible, and (ii) the most important variables that make the difference between existing flawed systems succeeding or failing in practice (often, the degree of coordination between subgroups of participants, but also other things that we often black-box as "culture") are variables that I was not even modeling.Before, mathematics was a primary part of my identity: I was heavily involved in math competitions in high school, and soon after I got into crypto, I began doing a lot of coding, in Ethereum, Bitcoin and elsewhere, I was getting excited about every new cryptography protocol, and economics too seemed to me to be part of that broader worldview: it's the mathematical tool for understanding and figuring out how to improve the social world. All the pieces neatly fit together. Now, those pieces fit together somewhat less. I do still use mathematics to analyze social mechanisms, though the goal is more often to come up with rough first-pass guesses about what might work and mitigate worst-case behavior (which, in a real-world setting, would be usually done by bots and not humans) rather than explain average-case behavior. Now, much more of my writing and thinking, even when supporting the same kinds of ideals that I supported a decade ago, often uses very different kinds of arguments. One thing that fascinates me about modern AI is that it lets us mathematically and philosophically engage with the hidden variables guiding human interaction in a different way: AI can make "vibes" legible. All of these deaths, births and rebirths, whether of ideas or collections of people, are ways in which life is finite. These deaths and births would continue to take place in a world where we lived two centuries, a millennium, or the same lifetime as a main-sequence star. And if you personally feel like life doesn't have enough finiteness and death and rebirth in it, you don't have to start wars to add more: you can also just make the same choice that I did and become a digital nomad.2"Grads are falling in Mariupol".I still remember anxiously watching the computer screen in my hotel room in Denver, on February 23, 2022, at 7:20 PM local time. For the past two hours, I had been simultaneously scrolling Twitter for updates and repeatedly pinging my dad, who has having the very same thoughts and fears that I was, until he finally sent me that fateful reply. I sent out a tweet making my position on the issue as clear as possible and I kept watching. I stayed up very late that night.The next morning I woke up to the Ukraine government twitter account desperately asking for donations in cryptocurrency. At first, I thought that there is no way this could be real, and I became very worried that the account was opportunistically hacked: someone, perhaps the Russian government itself, taking advantage of everyone's confusion and desperation to steal some money. My "security mindset" instinct took over, and I immediately started tweeting to warn people to be careful, all while going through my network to find people who could confirm or deny if the ETH address is genuine. An hour later, I was convinced that it was in fact genuine, and I publicly relayed my conclusion. And about an hour after that, a family member sent me a message pointing out that, given what I had already done, it would be better for my safety for me to not go back to Russia again.Eight months later, I was watching the crypto world go through a convulsion of a very different sort: the extremely public demise of Sam Bankman-Fried and FTX. At the time, someone posted on Twitter a long list of "crypto main characters", showing which ones had fallen and which ones were still intact. The casualty rate was massive: Rankings copied from the above tweet. The SBF situation was not unique: it mix-and-matched aspects of MtGox and several other convulsions that had engulfed the crypto space before. But it was a moment where I realized, all at once, that most of the people I had looked up to as guiding lights of the crypto space that I could comfortably follow in the footsteps of back in 2014 were no more.People looking at me from afar often think of me as a high-agency person, presumably because this is what you would expect of a "main character" or a "project founder" who "dropped out of college". In reality, however, I was anything but. The virtue I valorized as a kid was not the virtue of creativity in starting a unique new project, or the virtue of showing bravery in a once-in-a-generation moment that calls for it, but rather the virtue of being a good student who shows up on time, does his homework and gets a 99 percent average.My decision to drop out of college was not some kind of big brave step done out of conviction. It started with me in early 2013 deciding to take a co-op term in the summer to work for Ripple. When US visa complications prevented that, I instead spent the summer working with my Bitcoin Magazine boss and friend Mihai Alisie in Spain. Near the end of August, I decided that I needed to spend more time exploring the crypto world, and so I extended my vacation to 12 months. Only in January 2014, when I saw the social proof of hundreds of people cheering on my presentation introducing Ethereum at BTC Miami, did I finally realize that the choice was made for me to leave university for good. Most of my decisions in Ethereum involved responding to other people's pressures and requests. When I met Vladimir Putin in 2017, I did not try to arrange the meeting; rather, someone else suggested it, and I pretty much said "ok sure".Now, five years later, I finally realized that (i) I had been complicit in legitimizing a genocidal dictator, and (ii) within the crypto space too, I no longer had the luxury of sitting back and letting mystical "other people" run the show.These two events, as different as they are in the type and the scale of their tragedy, both burned into my mind a similar lesson: that I actually have responsibilities in this world, and I need to be intentional about how I operate. Doing nothing, or living on autopilot and letting myself simply become part of the plans of others, is not an automatically safe, or even blameless, course of action. I was one of the mystical other people, and it was up to me to play the part. If I do not, and the crypto space either stagnates or becomes dominated by opportunistic money-grabbers more than it otherwise would have as a result, I have only myself to blame. And so I decided to become careful in which of others' plans I go along with, and more high-agency in what plans I craft myself: fewer ill-conceived meetings with random powerful people who were only interested in me as a source of legitimacy, and more things like Zuzalu. The Zuzalu flags in Montenegro, spring 2023. 3On to happier things - or at least, things that are challenging in the way that a math puzzle is challenging, rather than challenging in the way that falling down in the middle of a run and needing to walk 2km with a bleeding knee to get medical attention is challenging (no, I won't share more details; the internet has already proven top notch at converting a photo of me with a rolled-up USB cable in my pocket into an internet meme insinuating something completely different, and I certainly do not want to give those characters any more ammunition).I have talked before about the changing role of economics, the need to think differently about motivation (and coordination: we are social creatures, so the two are in fact intimately linked), and the idea that the world is becoming a "dense jungle": Big Government, Big Business, Big Mob, and Big X for pretty much any X will all continue to grow, and they will have more and more frequent and complicated interactions with each other. What I have not yet talked as much about is how many of these changes affect the crypto space itself.The crypto space was born in late 2008, in the aftermath of the Global Financial Crisis. The genesis block of the Bitcoin blockchain contained a reference to this famous article from the UK's The Times: The early memes of Bitcoin were heavily influenced by these themes. Bitcoin is there to abolish the banks, which is a good thing to do because the banks are unsustainable megaliths that keep creating financial crises. Bitcoin is there to abolish fiat currency, because the banking system can't exist without the underlying central banks and the fiat currencies that they issue - and furthermore, fiat currency enables money printing which can fund wars. But in the fifteen years since then, the broader public discourse as a whole seems to have to a large extent moved beyond caring about money and banks. What is considered important now? Well, we can ask the copy of Mixtral 8x7b running on my new GPU laptop: Once again, AI can make vibes legible.No mention of money and banks or government control of currency. Trade and inequality are listed as concerns globally, but from what I can tell, the problems and solutions being discussed are more in the physical world than the digital world. Is the original "story" of crypto falling further and further behind the times?There are two sensible responses to this conundrum, and I believe that our ecosystem would benefit from embracing both of them:Remind people that money and finance still do matter, and do a good job of serving the world's underserved in that niche Extend beyond finance, and use our technology to build a more holistic vision of an alternative, more free and open and democratic tech stack, and how that could build toward either a broadly better society, or at least tools to help those who are excluded from mainstream digital infrastructure today. The first answer is important, and I would argue that the crypto space is uniquely positioned to provide value there. Crypto is one of the few tech industries that is genuinely highly decentralized, with developers spread out all over the globe: Source: Electric Capital's 2023 crypto developer reportHaving visited many of the new global hubs of crypto over the past year, I can confirm that this is the case. More and more of the largest crypto projects are headquartered in all kinds of far-flung places around the world, or even nowhere. Furthermore, non-Western developers often have a unique advantage in understanding the concrete needs of crypto users in low-income countries, and being able to create products that satisfy those needs. When I talk to many people from San Francisco, I get a distinct impression that they think that AI is the only thing that matters, San Francisco is the capital of AI, and therefore San Francisco is the only place that matters. "So, Vitalik, why are you not settled down in the Bay with an O1 visa yet"? Crypto does not need to play this game: it's a big world, and it only takes one visit to Argentina or Turkey or Zambia to remind ourselves that many people still do have important problems that have to do with access to money and finance, and there is still an opportunity to do the complicated work of balancing user experience and decentralization to actually solve those problems in a sustainable way.The second answer is the same vision as what I outlined in more detail in my recent post, "Make Ethereum Cypherpunk Again". Rather than just focusing on money, or being an "internet of value", I argued that the Ethereum community should expand its horizons. We should create an entire decentralized tech stack - a stack that is independent from the traditional Silicon Valley tech stack to the same extent that eg. the Chinese tech stack is - and compete with centralized tech companies at every level.Reproducing that table here: Traditional stack Decentralized stack Banking system ETH, stablecoins, L2s for payments, DEXes (note: still need banks for loans) Receipts Links to transactions on block explorers Corporations DAOs DNS (.com, .io, etc) ENS (.eth) Regular email Encrypted email (eg. Skiff) Regular messaging (eg. Telegram) Decentralized messaging (eg. Status) Sign in with Google, Twitter, Wechat Sign in with Ethereum, Zupass, Attestations via EAS, POAPs, Zu-Stamps... + social recovery Publishing blogs on Medium, etc Publishing self-hosted blogs on IPFS (eg. using Fleek) Twitter, Facebook Lens, Farcaster... Limit bad actors through all-seeing big brother Constrain bad actors through zero knowledge proofs After I made that post, some readers reminded me that a major missing piece from this stack is democratic governance technology: tools for people to collectively make decisions. This is something that centralized tech does not really even try to provide, because the assumption that each indidvidual company is just run by a CEO, and oversight is provided by... err... a board. Ethereum has benefited from very primitive forms of democratic governance technology in the past already: when a series of contentious decisions, such as the DAO fork and several rounds of issuance decrease, were made in 2016-2017, a team from Shanghai made a platform called Carbonvote, where ETH holders could vote on decisions. The ETH vote on the DAO fork. The votes were advisory in nature: there was no hard agreement that the results would determine what happens. But they helped give core developers the confidence to actually implement a series of EIPs, knowing that the mass of the community would be behind them. Today, we have access to proofs of community membership that are much richer than token holdings: POAPs, Gitcoin Passport scores, Zu stamps, etc.From these things all together, we can start to see the second vision for how the crypto space can evolve to better meet the concerns and needs of the 21st century: create a more holistic trustworthy, democratic, and decentralized tech stack. Zero knowledge proofs are key here in expanding the scope of what such a stack can offer: we can get beyond the false binary of "anonymous and therefore untrusted" vs "verified and KYC'd", and prove much more fine-grained statements about who we are and what permissions we have. This allows us to resolve concerns around authenticity and manipulation - guarding against "the Big Brother outside" - and concerns around privacy - guarding against "the Big Brother within" - at the same time. This way, crypto is not just a finance story, it can be part of a much broader story of making a better type of technology.4But how, beyond telling stories do we make this happen? Here, we get back to some of the issues that I raised in my post from three years ago: the changing nature of motivation. Often, people with an overly finance-focused theory of motivation - or at least, a theory of motivation within which financial motives can be understood and analyzed and everything else is treated as that mysterious black box we call "culture" - are confused by the space because a lot of the behavior seems to go against financial motives. "Users don't care about decentralization", and yet projects still often try hard to decentralize. "Consensus runs on game theory", and yet successful social campaigns to chase people off the dominant mining or staking pool have worked in Bitcoin and in Ethereum.It occurred to me recently that no one that I have seen has attempted to create a basic functional map of the crypto space working "as intended", that tries to include more of these actors and motivations. So let me quickly make an attempt now: This map itself is an intentional 50/50 mix of idealism and "describing reality". It's intended to show four major constituencies of the ecosystem that can have a supportive and symbiotic relationship with each other. Many crypto institutions in practice are a mix of all four.Each of the four parts has something key to offer to the machine as a whole:Token holders and defi users contribute greatly to financing the whole thing, which has been key to getting technologies like consensus algorithms and zero-knowledge proofs to production quality. Intellectuals provide the ideas to make sure that the space is actually doing something meaningful. Builders bridge the gap and try to build applications that serve users and put the ideas into practice. Pragmatic users are the people we are ultimately serving. And each of the four groups has complicated motivations, which interplay with the other groups in all kinds of complicated ways. There are also versions of each of these four that I would call "malfunctioning": apps can be extractive, defi users can unwittingly entrench extractive apps' network effects, pragmatic users can entrench centralized workflows, and intellectuals can get overly worked up on theory and overly focus on trying to solve all problems by yelling at people for being "misaligned" without appreciating that the financial side of motivation (and the "user inconvenience" side of demotivation) matters too, and can and should be fixed.Often, these groups have a tendency to scoff at each other, and at times in my history I have certainly played a part in this. Some blockchain projects openly try to cast off the idealism that they see as naive, utopian and distracting, and focus directly on applications and usage. Some developers disparage their token holders, and their dirty love of making money. Still other developers disparage the pragmatic users, and their dirty willingness to use centralized solutions when those are more convenient for them.But I think there is an opportunity to improve understanding between the four groups, where each side understands that it is ultimately dependent on the other three, works to limit its own excesses, and appreciates that in many cases their dreams are less far apart than they think. This is a form of peace that I think is actually possible to achieve, both within the "crypto space", and between it and adjacent communities whose values are highly aligned.5One of the beautiful things about crypto's global nature is the window that it has given me to all kinds of fascinating cultures and subcultures around the world, and how they interact with the crypto universe.I still remember visiting China for the first time in 2014, and seeing all the signs of brightness and hope: exchanges scaling up to hundreds of employees even faster than those in the US, massive-scale GPU and later ASIC farms, and projects with millions of users. Silicon Valley and Europe, meanwhile, have for a long time been key engines of idealism in the space, in their two distinct flavors. Ethereum's development was, almost since the beginning, de-facto headquartered in Berlin, and it was out of European open-source culture that a lot of the early ideas for how Ethereum could be used in non-financial applications emerged. A diagram of Ethereum and two proposed non-blockchain sister protocols Whisper and Swarm, which Gavin Wood used in many of his early presentations. Silicon Valley (by which, of course, I mean the entire San Francisco Bay Area), was another hotbed of early crypto interest, mixed in with various ideologies such as rationalism, effective altruism and transhumanism. In the 2010s these ideas were all new, and they felt "crypto-adjacent": many of the people who were interested in them, were also interested in crypto, and likewise in the other direction.Elsewhere, getting regular businesses to use cryptocurrency for payments was a hot topic. In all kind of places in the world, one would find people accepting Bitcoin, including even Japanese waiters taking Bitcoin for tips: Since then, these communities have experienced a lot of change. China saw multiple crypto crackdowns, in addition to other broader challenges, leading to Singapore becoming a new home for many developers. Silicon Valley splintered internally: rationalists and AI developers, basically different wings of the same team back as recently as 2020 when Scott Alexander was doxxed by the New York Times, have since become separate and dueling factions over the question of optimism vs pessimism about the default path of AI. The regional makeup of Ethereum changed significantly, especially during the 2018-era introduction of totally new teams to work on proof of stake, though more through addition of the new than through demise of the old. Death, birth and rebirth.There are many other communities that are worth mentioning.When I first visited Taiwan many times in 2016 and 2017, what struck me most was the combination of capacity for self-organization and willingness to learn of the people there. Whenever I would write a document or blog post, I would often find that within a day a study club would independently form and start excitedly annotating every paragraph of the post on Google Docs. More recently, members of the Taiwanese Ministry of Digital Affairs took a similar excitement to Glen Weyl's ideas of digital democracy and "plurality", and soon posted an entire mind map of the space (which includes a lot of Ethereum applications) on their twitter account.Paul Graham has written about how every city sends a message: in New York, "you should make more money". In Boston, "You really should get around to reading all those books". In Silicon Valley, "you should be more powerful". When I visit Taipei, the message that comes to my mind is "you should rediscover your inner high school student". Glen Weyl and Audrey Tang presenting at a study session at the Nowhere book shop in Taipei, where I had presented on Community Notes four months earlier When I visited Argentina several times over the past few years, I was struck by the hunger and willingness to build and apply the technologies and ideas that Ethereum and the broader cryptoverse have to offer. If places like Siilicon Valley are frontiers, filled with abstract far-mode thinking about a better future, places like Argentina are frontlines, filled with an active drive to meet challenges that need to be handled today: in Argentina's case, ultra-high inflation and limited connection to global financial systems. The amount of crypto adoption there is off the charts: I get recognized in the street more frequently in Buenos Aires than in San Francisco. And there are many local builders, with a surprisingly healthy mix of pragmatism and idealism, working to meet people's challenges, whether it's crypto/fiat conversion or improving the state of Ethereum nodes in Latin America. Myself and friends in a coffee shop in Buenos Aires, where we paid in ETH. There are far too many others to properly mention: the cosmopolitanism and highly international crypto communities based in Dubai, the growing ZK community everywhere in East and Southeast Asia, the energetic and pragmatic builders in Kenya, the public-goods-oriented solarpunk communities of Colorado, and more.And finally, Zuzalu in 2023 ended up creating a beautiful floating sub-community of a very different kind, which will hopefully flourish on its own in the years to come. This is a significant part of what attracts me about the network states movement at its best: the idea that cultures and communities are not just something to be defended and preserved, but also something that can be actively created and grown.6There are many lessons that one learns when growing up, and the lessons are different for different people. For me, a few are:Greed is not the only form of selfishness. Lots of harm can come from cowardice, laziness, resentment, and many other motives. Furthermore, greed itself can come in many forms: greed for social status can often be just as harmful as greed for money or power. As someone raised in my gentle Canadian upbringing, this was a major update: I felt like I had been taught to believe that greed for money and power is the root of most evils, and if I made sure I was not greedy for those things (eg. by repeatedly fighting to reduce the portion of the ETH supply premine that went to the top-5 "founders") I satisfied my responsibility to be a good person. This is of course not true. You're allowed to have preferences without needing to have a complicated scientific explanation of why your preferences are the true absolute good. I generally like utilitarianism and find it often unfairly maligned and wrongly equated with cold-heartedness, but this is one place where I think ideas like utilitarianism in excess can sometimes lead human beings astray: there's a limit to how much you can change your preferences, and so if you push too hard, you end up inventing reasons for why every single thing you prefer is actually objectively best at serving general human flourishing. This often leads you to try to convince others that these back-fitted arguments are correct, leading to unneeded conflict. A related lesson is that a person can be a bad fit for you (for any context: work, friendship or otherwise) without being a bad person in some absolute sense. The importance of habits. I intentionally keep many of my day-to-day personal goals limited. For example, I try to do one 20-kilometer run a month, and "whatever I can" beyond that. This is because the only effective habits are the habits that you actually keep. If something is too difficult to maintain, you will give up on it. As a digital nomad who regularly jumps continents and makes dozens of flights per year, routine of any kind is difficult for me, and I have to work around that reality. Though Duolingo's gamification, pushing you to maintain a "streak" by doing at least something every day, actually does work on me. Making active decisions is hard, and so it's always best to make active decisions that make the most long-term impact on your mind, by reprogramming your mind to default into a different pattern. There is a long tail of these that each person learns, and in principle I could go for longer. But there's also a limit to how much it's actually possible to learn from simply reading other people's experiences. As the world starts to change at a more rapid pace, the lessons that are available from other people's accounts also become outdated at a more rapid pace. So to a large extent, there is also no substitute for simply doing things the slow way and gaining personal experience.7Every beautiful thing in the social world - a community, an ideology, a "scene", or a country, or at the very small scale a company, a family or a relationship - was created by people. Even in those few cases where you could write a plausible story about how it existed since the dawn of human civilization and the Eighteen Tribes, someone at some point in the past had to actually write that story. These things are finite - both the thing in itself, as a part of the world, and the thing as you experience it, an amalgamation of the underlying reality and your own ways of conceiving and interpreting it. And as communities, places, scenes, companies and families fade away, new ones have to be created to replace them.For me, 2023 has been a year of watching many things, large and small, fade into the distance of time. The world is rapidly changing, the frameworks I am forced to use to try to make sense of the world are changing, and the role I play in affecting the world is changing. There is death, a truly inevitable type of death that will continue to be with us even after the blight of human biological aging and mortality is purged from our civilization, but there is also birth and rebirth. And continuing to stay active and doing what we can to create the new is a task for each one of us.
-
The promise and challenges of crypto + AI applications The promise and challenges of crypto + AI applications2024 Jan 30 See all posts The promise and challenges of crypto + AI applications Special thanks to the Worldcoin and Modulus Labs teams, Xinyuan Sun, Martin Koeppelmann and Illia Polosukhin for feedback and discussion.Many people over the years have asked me a similar question: what are the intersections between crypto and AI that I consider to be the most fruitful? It's a reasonable question: crypto and AI are the two main deep (software) technology trends of the past decade, and it just feels like there must be some kind of connection between the two. It's easy to come up with synergies at a superficial vibe level: crypto decentralization can balance out AI centralization, AI is opaque and crypto brings transparency, AI needs data and blockchains are good for storing and tracking data. But over the years, when people would ask me to dig a level deeper and talk about specific applications, my response has been a disappointing one: "yeah there's a few things but not that much".In the last three years, with the rise of much more powerful AI in the form of modern LLMs, and the rise of much more powerful crypto in the form of not just blockchain scaling solutions but also ZKPs, FHE, (two-party and N-party) MPC, I am starting to see this change. There are indeed some promising applications of AI inside of blockchain ecosystems, or AI together with cryptography, though it is important to be careful about how the AI is applied. A particular challenge is: in cryptography, open source is the only way to make something truly secure, but in AI, a model (or even its training data) being open greatly increases its vulnerability to adversarial machine learning attacks. This post will go through a classification of different ways that crypto + AI could intersect, and the prospects and challenges of each category. A high-level summary of crypto+AI intersections from a uETH blog post. But what does it take to actually realize any of these synergies in a concrete application? The four major categoriesAI is a very broad concept: you can think of "AI" as being the set of algorithms that you create not by specifying them explicitly, but rather by stirring a big computational soup and putting in some kind of optimization pressure that nudges the soup toward producing algorithms with the properties that you want. This description should definitely not be taken dismissively: it includes the process that created us humans in the first place! But it does mean that AI algorithms have some common properties: their ability to do things that are extremely powerful, together with limits in our ability to know or understand what's going on under the hood.There are many ways to categorize AI; for the purposes of this post, which talks about interactions between AI and blockchains (which have been described as a platform for creating "games"), I will categorize it as follows:AI as a player in a game [highest viability]: AIs participating in mechanisms where the ultimate source of the incentives comes from a protocol with human inputs. AI as an interface to the game [high potential, but with risks]: AIs helping users to understand the crypto world around them, and to ensure that their behavior (ie. signed messages and transactions) matches their intentions and they do not get tricked or scammed. AI as the rules of the game [tread very carefully]: blockchains, DAOs and similar mechanisms directly calling into AIs. Think eg. "AI judges" AI as the objective of the game [longer-term but intriguing]: designing blockchains, DAOs and similar mechanisms with the goal of constructing and maintaining an AI that could be used for other purposes, using the crypto bits either to better incentivize training or to prevent the AI from leaking private data or being misused. Let us go through these one by one.AI as a player in a gameThis is actually a category that has existed for nearly a decade, at least since on-chain decentralized exchanges (DEXes) started to see significant use. Any time there is an exchange, there is an opportunity to make money through arbitrage, and bots can do arbitrage much better than humans can. This use case has existed for a long time, even with much simpler AIs than what we have today, but ultimately it is a very real AI + crypto intersection. More recently, we have seen MEV arbitrage bots often exploiting each other. Any time you have a blockchain application that involves auctions or trading, you are going to have arbitrage bots.But AI arbitrage bots are only the first example of a much bigger category, which I expect will soon start to include many other applications. Meet AIOmen, a demo of a prediction market where AIs are players: Prediction markets have been a holy grail of epistemics technology for a long time; I was excited about using prediction markets as an input for governance ("futarchy") back in 2014, and played around with them extensively in the last election as well as more recently. But so far prediction markets have not taken off too much in practice, and there is a series of commonly given reasons why: the largest participants are often irrational, people with the right knowledge are not willing to take the time and bet unless a lot of money is involved, markets are often thin, etc.One response to this is to point to ongoing UX improvements in Polymarket or other new prediction markets, and hope that they will succeed where previous iterations have failed. After all, the story goes, people are willing to bet tens of billions on sports, so why wouldn't people throw in enough money betting on US elections or LK99 that it starts to make sense for the serious players to start coming in? But this argument must contend with the fact that, well, previous iterations have failed to get to this level of scale (at least compared to their proponents' dreams), and so it seems like you need something new to make prediction markets succeed. And so a different response is to point to one specific feature of prediction market ecosystems that we can expect to see in the 2020s that we did not see in the 2010s: the possibility of ubiquitous participation by AIs.AIs are willing to work for less than $1 per hour, and have the knowledge of an encyclopedia - and if that's not enough, they can even be integrated with real-time web search capability. If you make a market, and put up a liquidity subsidy of $50, humans will not care enough to bid, but thousands of AIs will easily swarm all over the question and make the best guess they can. The incentive to do a good job on any one question may be tiny, but the incentive to make an AI that makes good predictions in general may be in the millions. Note that potentially, you don't even need the humans to adjudicate most questions: you can use a multi-round dispute system similar to Augur or Kleros, where AIs would also be the ones participating in earlier rounds. Humans would only need to respond in those few cases where a series of escalations have taken place and large amounts of money have been committed by both sides.This is a powerful primitive, because once a "prediction market" can be made to work on such a microscopic scale, you can reuse the "prediction market" primitive for many other kinds of questions:Is this social media post acceptable under [terms of use]? What will happen to the price of stock X (eg. see Numerai) Is this account that is currently messaging me actually Elon Musk? Is this work submission on an online task marketplace acceptable? Is the dapp at https://examplefinance.network a scam? Is 0x1b54....98c3 actually the address of the "Casinu Inu" ERC20 token? You may notice that a lot of these ideas go in the direction of what I called "info defense" in my writings on "d/acc". Broadly defined, the question is: how do we help users tell apart true and false information and detect scams, without empowering a centralized authority to decide right and wrong who might then abuse that position? At a micro level, the answer can be "AI". But at a macro level, the question is: who builds the AI? AI is a reflection of the process that created it, and so cannot avoid having biases. Hence, there is a need for a higher-level game which adjudicates how well the different AIs are doing, where AIs can participate as players in the game.This usage of AI, where AIs participate in a mechanism where they get ultimately rewarded or penalized (probabilistically) by an on-chain mechanism that gathers inputs from humans (call it decentralized market-based RLHF?), is something that I think is really worth looking into. Now is the right time to look into use cases like this more, because blockchain scaling is finally succeeding, making "micro-" anything finally viable on-chain when it was often not before.A related category of applications goes in the direction of highly autonomous agents using blockchains to better cooperate, whether through payments or through using smart contracts to make credible commitments.AI as an interface to the gameOne idea that I brought up in my writings on is the idea that there is a market opportunity to write user-facing software that would protect users' interests by interpreting and identifying dangers in the online world that the user is navigating. One already-existing example of this is Metamask's scam detection feature: Another example is the Rabby wallet's simulation feature, which shows the user the expected consequences of the transaction that they about to sign. Rabby explaining to me the consequences of signing a transaction to trade all of my "BITCOIN" (the ticker of an ERC20 memecoin whose full name is apparently "HarryPotterObamaSonic10Inu") for ETH.Edit 2024.02.02: an earlier version of this post referred to this token as a scam trying to impersonate bitcoin. It is not; it is a memecoin. Apologies for the confusion. Potentially, these kinds of tools could be super-charged with AI. AI could give a much richer human-friendly explanation of what kind of dapp you are participating in, the consequences of more complicated operations that you are signing, whether or not a particular token is genuine (eg. BITCOIN is not just a string of characters, it's normally the name of a major cryptocurrency, which is not an ERC20 token and which has a price waaaay higher than $0.045, and a modern LLM would know that), and so on. There are projects starting to go all the way out in this direction (eg. the LangChain wallet, which uses AI as a primary interface). My own opinion is that pure AI interfaces are probably too risky at the moment as it increases the risk of other kinds of errors, but AI complementing a more conventional interface is getting very viable.There is one particular risk worth mentioning. I will get into this more in the section on "AI as rules of the game" below, but the general issue is adversarial machine learning: if a user has access to an AI assistant inside an open-source wallet, the bad guys will have access to that AI assistant too, and so they will have unlimited opportunity to optimize their scams to not trigger that wallet's defenses. All modern AIs have bugs somewhere, and it's not too hard for a training process, even one with only limited access to the model, to find them.This is where "AIs participating in on-chain micro-markets" works better: each individual AI is vulnerable to the same risks, but you're intentionally creating an open ecosystem of dozens of people constantly iterating and improving them on an ongoing basis. Furthermore, each individual AI is closed: the security of the system comes from the openness of the rules of the game, not the internal workings of each player.Summary: AI can help users understand what's going on in plain language, it can serve as a real-time tutor, it can protect users from mistakes, but be warned when trying to use it directly against malicious misinformers and scammers.AI as the rules of the gameNow, we get to the application that a lot of people are excited about, but that I think is the most risky, and where we need to tread the most carefully: what I call AIs being part of the rules of the game. This ties into excitement among mainstream political elites about "AI judges" (eg. see this article on the website of the "World Government Summit"), and there are analogs of these desires in blockchain applications. If a blockchain-based smart contract or a DAO needs to make a subjective decision (eg. is a particular work product acceptable in a work-for-hire contract? Which is the right interpretation of a natural-language constitution like the Optimism Law of Chains?), could you make an AI simply be part of the contract or DAO to help enforce these rules?This is where adversarial machine learning is going to be an extremely tough challenge. The basic two-sentence argument why is as follows:If an AI model that plays a key role in a mechanism is closed, you can't verify its inner workings, and so it's no better than a centralized application. If the AI model is open, then an attacker can download and simulate it locally, and design heavily optimized attacks to trick the model, which they can then replay on the live network. Adversarial machine learning example. Source: researchgate.net Now, frequent readers of this blog (or denizens of the cryptoverse) might be getting ahead of me already, and thinking: but wait! We have fancy zero knowledge proofs and other really cool forms of cryptography. Surely we can do some crypto-magic, and hide the inner workings of the model so that attackers can't optimize attacks, but at the same time prove that the model is being executed correctly, and was constructed using a reasonable training process on a reasonable set of underlying data!Normally, this is exactly the type of thinking that I advocate both on this blog and in my other writings. But in the case of AI-related computation, there are two major objections:Cryptographic overhead: it's much less efficient to do something inside a SNARK (or MPC or...) than it is to do it "in the clear". Given that AI is very computationally-intensive already, is doing AI inside of cryptographic black boxes even computationally viable? Black-box adversarial machine learning attacks: there are ways to optimize attacks against AI models even without knowing much about the model's internal workings. And if you hide too much, you risk making it too easy for whoever chooses the training data to corrupt the model with poisoning attacks. Both of these are complicated rabbit holes, so let us get into each of them in turn.Cryptographic overheadCryptographic gadgets, especially general-purpose ones like ZK-SNARKs and MPC, have a high overhead. An Ethereum block takes a few hundred milliseconds for a client to verify directly, but generating a ZK-SNARK to prove the correctness of such a block can take hours. The typical overhead of other cryptographic gadgets, like MPC, can be even worse. AI computation is expensive already: the most powerful LLMs can output individual words only a little bit faster than human beings can read them, not to mention the often multimillion-dollar computational costs of training the models. The difference in quality between top-tier models and the models that try to economize much more on training cost or parameter count is large. At first glance, this is a very good reason to be suspicious of the whole project of trying to add guarantees to AI by wrapping it in cryptography.Fortunately, though, AI is a very specific type of computation, which makes it amenable to all kinds of optimizations that more "unstructured" types of computation like ZK-EVMs cannot benefit from. Let us examine the basic structure of an AI model: Usually, an AI model mostly consists of a series of matrix multiplications interspersed with per-element non-linear operations such as the ReLU function (y = max(x, 0)). Asymptotically, matrix multiplications take up most of the work: multiplying two N*N matrices takes \(O(N^)\) time, whereas the number of non-linear operations is much smaller. This is really convenient for cryptography, because many forms of cryptography can do linear operations (which matrix multiplications are, at least if you encrypt the model but not the inputs to it) almost "for free".If you are a cryptographer, you've probably already heard of a similar phenomenon in the context of homomorphic encryption: performing additions on encrypted ciphertexts is really easy, but multiplications are incredibly hard and we did not figure out any way of doing it at all with unlimited depth until 2009.For ZK-SNARKs, the equivalent is protocols like this one from 2013, which show a less than 4x overhead on proving matrix multiplications. Unfortunately, the overhead on the non-linear layers still ends up being significant, and the best implementations in practice show overhead of around 200x. But there is hope that this can be greatly decreased through further research; see this presentation from Ryan Cao for a recent approach based on GKR, and my own simplified explanation of how the main component of GKR works.But for many applications, we don't just want to prove that an AI output was computed correctly, we also want to hide the model. There are naive approaches to this: you can split up the model so that a different set of servers redundantly store each layer, and hope that some of the servers leaking some of the layers doesn't leak too much data. But there are also surprisingly effective forms of specialized multi-party computation. A simplified diagram of one of these approaches, keeping the model private but making the inputs public. If we want to keep the model and the inputs private, we can, though it gets a bit more complicated: see pages 8-9 of the paper. In both cases, the moral of the story is the same: the greatest part of an AI computation is matrix multiplications, for which it is possible to make very efficient ZK-SNARKs or MPCs (or even FHE), and so the total overhead of putting AI inside cryptographic boxes is surprisingly low. Generally, it's the non-linear layers that are the greatest bottleneck despite their smaller size; perhaps newer techniques like lookup arguments can help.Black-box adversarial machine learningNow, let us get to the other big problem: the kinds of attacks that you can do even if the contents of the model are kept private and you only have "API access" to the model. Quoting a paper from 2016:Many machine learning models are vulnerable to adversarial examples: inputs that are specially crafted to cause a machine learning model to produce an incorrect output. Adversarial examples that affect one model often affect another model, even if the two models have different architectures or were trained on different training sets, so long as both models were trained to perform the same task. An attacker may therefore train their own substitute model, craft adversarial examples against the substitute, and transfer them to a victim model, with very little information about the victim. Use black-box access to a "target classifier" to train and refine your own locally stored "inferred classifier". Then, locally generate optimized attacks against the inferred classifier. It turns out these attacks will often also work against the original target classifier. Diagram source. Potentially, you can even create attacks knowing just the training data, even if you have very limited or no access to the model that you are trying to attack. As of 2023, these kinds of attacks continue to be a large problem.To effectively curtail these kinds of black-box attacks, we need to do two things:Really limit who or what can query the model and how much. Black boxes with unrestricted API access are not secure; black boxes with very restricted API access may be. Hide the training data, while preserving confidence that the process used to create the training data is not corrupted. The project that has done the most on the former is perhaps Worldcoin, of which I analyze an earlier version (among other protocols) at length here. Worldcoin uses AI models extensively at protocol level, to (i) convert iris scans into short "iris codes" that are easy to compare for similarity, and (ii) verify that the thing it's scanning is actually a human being. The main defense that Worldcoin is relying on is the fact that it's not letting anyone simply call into the AI model: rather, it's using trusted hardware to ensure that the model only accepts inputs digitally signed by the orb's camera.This approach is not guaranteed to work: it turns out that you can make adversarial attacks against biometric AI that come in the form of physical patches or jewelry that you can put on your face: Wear an extra thing on your forehead, and evade detection or even impersonate someone else. Source. But the hope is that if you combine all the defenses together, hiding the AI model itself, greatly limiting the number of queries, and requiring each query to somehow be authenticated, you can make adversarial attacks difficult enough that the system could be secure. In the case of Worldcoin, increasing these other defences could also reduce their dependence on trusted hardware, increasing the project's decentralization.And this gets us to the second part: how can we hide the training data? This is where "DAOs to democratically govern AI" might actually make sense: we can create an on-chain DAO that governs the process of who is allowed to submit training data (and what attestations are required on the data itself), who is allowed to make queries, and how many, and use cryptographic techniques like MPC to encrypt the entire pipeline of creating and running the AI from each individual user's training input all the way to the final output of each query. This DAO could simultaneously satisfy the highly popular objective of compensating people for submitting data. It is important to re-state that this plan is super-ambitious, and there are a number of ways in which it could prove impractical:Cryptographic overhead could still turn out too high for this kind of fully-black-box architecture to be competitive with traditional closed "trust me" approaches. It could turn out that there isn't a good way to make the training data submission process decentralized and protected against poisoning attacks. Multi-party computation gadgets could break their safety or privacy guarantees due to participants colluding: after all, this has happened with cross-chain cryptocurrency bridges again and again. One reason why I didn't start this section with more big red warning labels saying "DON'T DO AI JUDGES, THAT'S DYSTOPIAN", is that our society is highly dependent on unaccountable centralized AI judges already: the algorithms that determine which kinds of posts and political opinions get boosted and deboosted, or even censored, on social media. I do think that expanding this trend further at this stage is quite a bad idea, but I don't think there is a large chance that the blockchain community experimenting with AIs more will be the thing that contributes to making it worse.In fact, there are some pretty basic low-risk ways that crypto technology can make even these existing centralized systems better that I am pretty confident in. One simple technique is verified AI with delayed publication: when a social media site makes an AI-based ranking of posts, it could publish a ZK-SNARK proving the hash of the model that generated that ranking. The site could commit to revealing its AI models after eg. a one year delay. Once a model is revealed, users could check the hash to verify that the correct model was released, and the community could run tests on the model to verify its fairness. The publication delay would ensure that by the time the model is revealed, it is already outdated.So compared to the centralized world, the question is not if we can do better, but by how much. For the decentralized world, however, it is important to be careful: if someone builds eg. a prediction market or a stablecoin that uses an AI oracle, and it turns out that the oracle is attackable, that's a huge amount of money that could disappear in an instant.AI as the objective of the gameIf the above techniques for creating a scalable decentralized private AI, whose contents are a black box not known by anyone, can actually work, then this could also be used to create AIs with utility going beyond blockchains. The NEAR protocol team is making this a core objective of their ongoing work.There are two reasons to do this:If you can make "trustworthy black-box AIs" by running the training and inference process using some combination of blockchains and MPC, then lots of applications where users are worried about the system being biased or cheating them could benefit from it. Many people have expressed a desire for democratic governance of systemically-important AIs that we will depend on; cryptographic and blockchain-based techniques could be a path toward doing that. From an AI safety perspective, this would be a technique to create a decentralized AI that also has a natural kill switch, and which could limit queries that seek to use the AI for malicious behavior. It is also worth noting that "using crypto incentives to incentivize making better AI" can be done without also going down the full rabbit hole of using cryptography to completely encrypt it: approaches like BitTensor fall into this category.ConclusionsNow that both blockchains and AIs are becoming more powerful, there is a growing number of use cases in the intersection of the two areas. However, some of these use cases make much more sense and are much more robust than others. In general, use cases where the underlying mechanism continues to be designed roughly as before, but the individual players become AIs, allowing the mechanism to effectively operate at a much more micro scale, are the most immediately promising and the easiest to get right.The most challenging to get right are applications that attempt to use blockchains and cryptographic techniques to create a "singleton": a single decentralized trusted AI that some application would rely on for some purpose. These applications have promise, both for functionality and for improving AI safety in a way that avoids the centralization risks associated with more mainstream approaches to that problem. But there are also many ways in which the underlying assumptions could fail; hence, it is worth treading carefully, especially when deploying these applications in high-value and high-risk contexts.I look forward to seeing more attempts at constructive use cases of AI in all of these areas, so we can see which of them are truly viable at scale.